【APUE】Chapter12 Thread Control
今天看了APUE的Chapter12 Thread Control的内容,记录一下看书的心得与示例code。
这一章的内容是对Chapter11 Threads(见上一篇日志)的补充,大部分内容都是理论上的分析提点,大概就是告诉读者:你先知道pthread有这么个特性,如果将来遇到了可以去查查。
(一)Thread Limits
这里主要介绍了pthread_attr_t的属性变量,可以通过设置属性变来定制化threads的特性(P426)。
其中,一个重要的属性就是thread的stack size。代码示例如下:
#include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <string.h> void *thr_fun(void *arg) { puts("Thread is working."); pthread_exit((void *)0); } int main() { pthread_t tid; int err,i; pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setstacksize(&attr, 1024*1024); for ( i=0;;++i ) { err = pthread_create(&tid, &attr, thr_fun, NULL); if( err ) { fprintf(stderr, "pthread_create():%s\n", strerror(err)); break; } } printf("i = %d\n",i); pthread_attr_destroy(&attr); exit(0); }
上述代码的功能是
(1)在main主线程中不断创建新的线程,用pthread_attr_t初始化每个线程的stack size为1024*1024B(单位是字节)
(2)每个线程的任务比较简答:就是puts一段儿字符串,然后就完事返回了
(3)虽然每个线程很快就完事儿了,但是产生的线程并没有被收尸,还占着当前进程的茅坑呢(还占用着产生它的进程的资源呢)。
运行结果如下:
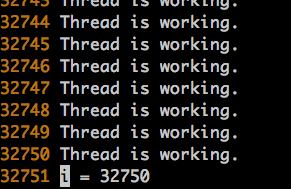
代码运行的环境是一个centos server,大概当前线程能够负担的最大线程数是32750个1024*1024B的线程。
(二)Detach
如果我对上述的代码修改一下,如下:
pthread_attr_init(&attr); pthread_attr_setstacksize(&attr, 1024*1024); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
结果就不一样了:该程序会一直运行,除非人工强制结束进程。
或者像下面这样改:
err = pthread_create(&tid, &attr, thr_fun, NULL); if( err ) { fprintf(stderr, "pthread_create():%s\n", strerror(err)); break; } pthread_detach(tid);
结果也是程序一直运行,不停下来。
通过这个例子不仅可以理解pthread_attr_t的用法,同时对pthread_detach的含义有了进一步理解。
(1)在pthread_attr_setdetachstate中设定detach属性,相当于告诉操作系统,这个线程创建完就让他自生自灭了,运行完自己给自己清理了。
(2)phread_detach(tid),相当于告诉操作系统,咱们主动为刚才创建的pthread_t为tid的线程收尸,把它清理干净了。
还有一种给线程收尸的方式是用pthread_join。但是敢用这种方式的前提是,调用pthread_join之前,线程没有被detach。看如下代码:
#include <stdio.h> #include <stdlib.h> #include <pthread.h> #include <string.h> void *thr_fun(void *arg) { puts("Thread is working."); pthread_exit((void *)0); } int main() { pthread_t tid; int err,tret; pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); err = pthread_create(&tid, &attr, thr_fun, NULL); if( err ) fprintf(stderr, "pthread_create():%s\n", strerror(err)); else printf("created\n"); err = pthread_join(tid, (void *)&tret); if( err ) fprintf(stderr, "pthread_create():%s\n", strerror(err)); else printf("joined\n"); pthread_attr_destroy(&attr); exit(0); }
上述代码运行结果如下:
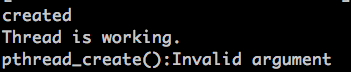
从运行结果可以看到:线程被创建成功,并且执行了;但是由于线程在创建时候pthread_attr_t被设置成detach的了,于是pthread_join就对其失效了。
(三)Recursive Mutex
书上给了一段代码,但是仅供观看,不能run;为了能够运行出结果,我稍微做了一些修改。代码如下:
#include "apue.h" #include <pthread.h> #include <time.h> #include <sys/time.h> int makethread(void *(*fn)(void *), void *arg) { int err; pthread_t tid; pthread_attr_t attr; err = pthread_attr_init(&attr); if ( err!=0 ) return err; err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); if ( err==0 ) err = pthread_create(&tid, &attr, fn, arg); pthread_attr_destroy(&attr); return err; } struct to_info{ void (*to_fn)(void *); void *to_arg; struct timespec to_wait; }; #define SECTONSEC 1000000000 #define USECTONSEC 1000 void * timeout_helper(void *arg) { struct to_info *tip; tip = (struct to_info *)arg; clock_nanosleep(CLOCK_REALTIME, 0, &tip->to_wait, NULL); (*tip->to_fn)(tip->to_arg); free(arg); return 0; } void timeout(const struct timespec *when, void (*func)(void *), void *arg) { struct timespec now; struct to_info *tip; int err; clock_gettime(CLOCK_REALTIME, &now); if ( (when->tv_sec > now.tv_sec) || (when->tv_sec==now.tv_sec && when->tv_nsec > now.tv_nsec) ) { tip = malloc(sizeof(struct to_info)); if ( tip!=NULL ) { tip->to_fn = func; tip->to_arg = arg; tip->to_wait.tv_sec = when->tv_sec - now.tv_sec; if ( when->tv_nsec>=now.tv_nsec ) { tip->to_wait.tv_nsec = when->tv_nsec - now.tv_nsec; } else { tip->to_wait.tv_sec--; tip->to_wait.tv_nsec = SECTONSEC - now.tv_nsec + when->tv_nsec; } err = makethread(timeout_helper, (void *)tip); if (err==0) { printf("makethread return 0\n"); return; } else free(tip); } } (*func)(arg); } pthread_mutexattr_t attr; pthread_mutex_t mutex; void retry(void *arg) { printf("require mutex for the second time\n"); pthread_mutex_lock(&mutex); // perform retry FILE *fp; fp = fopen("./retry.dat","w+"); fputs("this a retry.",fp); fclose(fp); pthread_mutex_unlock(&mutex); } int main() { int err, condition, arg; struct timespec when; if ( (err = pthread_mutexattr_init(&attr)) != 0 ) err_exit(err, "pthread_mutexattr_init failed"); if ( (err = pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE)) != 0 ) err_exit(err, "can't set recursive type"); if ( (err = pthread_mutex_init(&mutex, &attr)) != 0 ) err_exit(err, "can't create recursive mutex"); condition = 1; pthread_mutex_lock(&mutex); if (condition) { printf("retry until timeout\n"); clock_gettime(CLOCK_REALTIME, &when); when.tv_sec += 10; timeout(&when, retry, (void *)((unsigned long)arg)); } pthread_mutex_unlock(&mutex); sleep(15); exit(0); }
上面的代码有虽然比较接近实际应用,但是对于阐述知识点来说有些冗余(感兴趣可以都看看),或者只看红字部分就足够了。
运行结果如下:
在当前路径下生成了retry.dat的文件,OK。
上面的结果很好分析:
(1)main中对mutex上锁,调用timeout并在其中由makethread产生了一个新的线程timeout_helper(延迟10秒调用retry函数),main对mutex解锁
(2)线程timeout_helper延迟10秒后调用retry函数(此时mutex早已在main中被解锁),对mutex上锁,执行操作,再对mutex解锁。
但如果将main函数中的两条语句调换顺序:
sleep(15); pthread_mutex_unlock(&mutex);
结果就不同了,这次不会输出retry.dat文件。
因为main线程先等待15秒,而这15秒一直占着mutex;同时,timeout_helper被mutex阻塞了,直到main线程执行unlock操作。
但是main一旦unlock,主进程就exit了;由于timeout_helper也是由这个进程产生了,因此没来得及执行呢就被一起收尸了。
这里容易产生个误区:makethread中有这么一句话:
err = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
不是将timeout_helper设置成detached了么,与主线程脱钩了么?
是的,但是这个timeout_helper使用的资源依然离不开产生它的进程,因此在main中exit了,这个timeout_helper就被动收尸了。
下面,将如下的代码段屏蔽:
clock_gettime(CLOCK_REALTIME, &now); /* if ( (when->tv_sec > now.tv_sec) || (when->tv_sec==now.tv_sec && when->tv_nsec > now.tv_nsec) ) { tip = malloc(sizeof(struct to_info)); if ( tip!=NULL ) { tip->to_fn = func; tip->to_arg = arg; tip->to_wait.tv_sec = when->tv_sec - now.tv_sec; if ( when->tv_nsec>=now.tv_nsec ) { tip->to_wait.tv_nsec = when->tv_nsec - now.tv_nsec; } else { tip->to_wait.tv_sec--; tip->to_wait.tv_nsec = SECTONSEC - now.tv_nsec + when->tv_nsec; } err = makethread(timeout_helper, (void *)tip); if (err==0) { printf("makethread return 0\n"); return; } else free(tip); } } */ (*func)(arg);
大家稍微梳理下流程,就可以看到:在整个程序运行当众,只有一个main线程,并没有调用makethread产生新的线程。
因此有如下的结构:
main():
lock(mutex)
retry():
lock(mutex)
unlock(mutex)
unlock(mutex)
也就是说在同一个线程中对lock(mutex)锁了两次,如果不把mutex设定为recursive的,那就肯定死锁了;如果设定成了recursive的,就可以不死锁。
大家可以自己修改下代码测试一下,但是前提是在main的进程不能突然结束,否则任何操作就然并卵了。
=============================
还有个IBM的知识分享,可以看了
http://www.ibm.com/developerworks/cn/linux/l-cn-mthreadps/
12.8 Threads and Signals
作者提醒大家,“信号+进程”本身就已经比较复杂了,如果再跟多线程搅和在一起就更加作死了。
有几个基本的outline:
(1)每个线程都有各自的signal mask(可以设定当前线程屏蔽哪些信号)
(2)但是signal处理函数,在进程内是各个线程共享的(某个signal handler改了 其余的都受到影响)
(3)signal一般是发给单独线程的;如果是hardware fault相关的内容,哪个线程引起的就发给哪个线程
(4)给线程设置signal mask需要用pthread_sigmask函数,这个函数与sigprocmask几乎相同,区别在于pthread_sigmask如果执行错误,会返回错误码;而sigprocmask执行错误会重置errno的值,并且返回-1
两个重要的函数:
1. pthread_sigmask(int how, const sigset_t *restrict set, sigset_t *restrict oset);
三个参数的具体含义与sigprocmask类似,不再追溯。
2. sigwait(const sigset_t *restrict set, int *restrict signop);
set : 表示要等哪些signal
signop: 用于记录等来的是哪个signal (因为再set中可能等好几个signal,其中任何一个signal的到来都可以让sigwai停止阻塞,因此需要记录到底是哪个signal来的)
作者还特意强调,为了避免“erroneous behavior”,在调用sigwait之前,先要把需要等待的信号block了;在调用sigwait之后,会自动将set中的signal都unblock,然后再等signal到来
这亮个函数的好处在于,可以单独开一个线程,异步处理特定的信号。具体的做法如下:
(1)在不需要接收到特定信号的线程中,用pthread_sigmask在当前线程中屏蔽这些信号
(2)然后在用一个线程专门等着处理这个信号,sigwait就派上用场了
看一个例子:
#include <pthread.h>
#include "apue.h"
int quitflay; /*set nonzero by thread*/
sigset_t mask;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t waitloc = PTHREAD_COND_INITIALIZER;
void * thr_fn(void *arg)
{
int err, signo;
for(; ;)
{
err = sigwait(&mask, &signo); /*mask是要等着的信号集合 signo存放等来的信号*/
if (err!=0)
err_exit(err, "sigwait failed");
switch (signo)
{
case SIGINT:
printf("\ninterrupt\n");
break;
case SIGQUIT:
pthread_mutex_lock(&lock);
quitflay = 1;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&waitloc);
return 0;
default:
printf("unexpected signal %d\n", signo);
exit(1);
}
}
}
int main()
{
int err;
sigset_t oldmask;
pthread_t tid;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigaddset(&mask, SIGQUIT);
pthread_sigmask(SIG_BLOCK, &mask, &oldmask);
pthread_create(&tid, NULL, thr_fn, 0);
pthread_mutex_lock(&lock);
while (quitflay==0)
pthread_cond_wait(&waitloc, &lock);
pthread_mutex_unlock(&lock);
quitflay = 0;
sigprocmask(SIG_SETMASK, &oldmask, NULL);
exit(0);
}
代码执行结果:
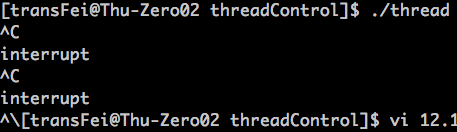
分析如下:
(1)在main的主线程中先堵住SIGINT和SIGQUIT信号
(2)堵完了之后,再用pthread_create创建新的线程,实际上就是注册了一个信号处理的线程
(3)这个新线程的signal mask继承了创建其的main线程中的signal mask(留到最后再说这个)
(3)判断quitflag的值来判断是否往下执行(这里用“条件变量+锁”的形式来保持对全局变量mash读写的同步动作)
(4)那么,有没有可能出现信号空等待的情况呢?假象一种情况:如果main函数中,pthread_create和while之间的time window中来了一个SIGINT或者SIGQUIT信号,会怎么处理?其实也没事,如果来的是SIGINT,没关系,正常进入while循环等着;如果来但是SIGQUIT,此时quitflag已经被置为1了,while循环不会执行等待。所以,经过分析,这种信号处理模式是等待安全的。
总结一下上述的代码,pthread_sigmask屏蔽的目的是让不该接收到该信号的线程收不到;而某个线程中的sigwait起到的作用是“瞬间unblock开set中的那些信号 → 接收信号,保存到signo里面 → 恢复信号mask → 处理signo这个信号”。而在这期间,只有sigwait的时候是瞬间unblock的,其余的时间都是继承main中对信号的屏蔽的。
对上述代码修改如下:
#include <pthread.h>
#include "apue.h"
int quitflay; /*set nonzero by thread*/
sigset_t mask;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t waitloc = PTHREAD_COND_INITIALIZER;
void * thr_fn(void *arg)
{
int err, signo;
sigset_t curr;
sigprocmask(SIG_BLOCK, NULL, &curr);
if ( sigismember(&curr, SIGINT) )
printf("blocking SIGINT\n");
if ( sigismember(&curr, SIGQUIT) )
printf("blocking SIGQUIT\n");
for(; ;)
{
err = sigwait(&mask, &signo); /*mask是要等着的信号集合 signo存放等来的信号*/
if ( sigismember(&curr, SIGINT) )
printf("blocking SIGINT\n");
if ( sigismember(&curr, SIGQUIT) )
printf("blocking SIGQUIT\n");
if (err!=0)
err_exit(err, "sigwait failed");
switch (signo)
{
case SIGINT:
printf("\ninterrupt\n");
break;
case SIGQUIT:
pthread_mutex_lock(&lock);
quitflay = 1;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&waitloc);
return 0;
default:
printf("unexpected signal %d\n", signo);
exit(1);
}
}
}
int main()
{
int err;
sigset_t oldmask;
pthread_t tid;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigaddset(&mask, SIGQUIT);
pthread_sigmask(SIG_BLOCK, &mask, &oldmask);
//sigprocmask(SIG_BLOCK, &mask, &oldmask);
pthread_create(&tid, NULL, thr_fn, 0);
pthread_mutex_lock(&lock);
while (quitflay==0)
pthread_cond_wait(&waitloc, &lock);
pthread_mutex_unlock(&lock);
quitflay = 0;
sigprocmask(SIG_SETMASK, &oldmask, NULL);
exit(0);
}
再次运行结果如下:
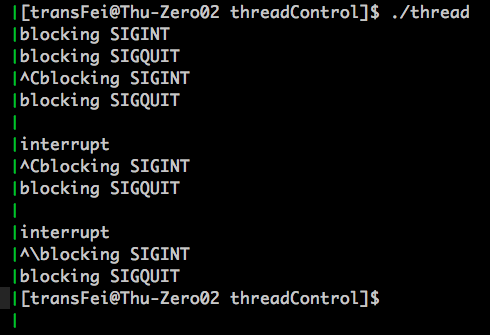
上述代码的修改就是在信号处理线程中sigwait前后均获取当前线程是否阻塞某些信号。可以看到,在信号处理线程中sigwait前后都屏蔽了信号,但是还能够处理这些信号;也就是说,只有sigwait这个函数执行的瞬间,SIGINT和SIGQUIT是unblock的,之前和之后都与main中信号mask相同。
还有一点需要总结,不是说各个线程间的signal mask可以是独立的么?下面写一个例子,直观帮助理解,代码如下:
#include <pthread.h>
#include "apue.h"
int quitflay; /*set nonzero by thread*/
sigset_t mask;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t waitloc = PTHREAD_COND_INITIALIZER;
void signal_check()
{
sigset_t curr;
sigprocmask(SIG_BLOCK, NULL, &curr);
if ( sigismember(&curr, SIGINT) )
printf("blocking SIGINT\n");
if ( sigismember(&curr, SIGQUIT) )
printf("blocking SIGQUIT\n");
if ( sigismember(&curr, SIGUSR1) )
printf("blocking SIGUSR1\n");
}
void * thr_fn(void *arg)
{
int err, signo;
printf("befor setting mask in signal handling thread...\n");
signal_check();
sigset_t extra;
sigaddset(&extra, SIGUSR1);
sigprocmask(SIG_BLOCK, &extra, NULL);
printf("after setting mask in signal handling thread...\n");
signal_check();
for(; ;)
{
err = sigwait(&mask, &signo); /*mask是要等着的信号集合 signo存放等来的信号*/
if (err!=0)
err_exit(err, "sigwait failed");
switch (signo)
{
case SIGINT:
printf("\ninterrupt\n");
break;
case SIGQUIT:
pthread_mutex_lock(&lock);
quitflay = 1;
pthread_mutex_unlock(&lock);
pthread_cond_signal(&waitloc);
return 0;
default:
printf("unexpected signal %d\n", signo);
exit(1);
}
}
}
int main()
{
int err;
sigset_t oldmask;
pthread_t tid;
sigemptyset(&mask);
sigaddset(&mask, SIGINT);
sigaddset(&mask, SIGQUIT);
pthread_sigmask(SIG_BLOCK, &mask, &oldmask);
//sigprocmask(SIG_BLOCK, &mask, &oldmask);
pthread_create(&tid, NULL, thr_fn, 0);
sleep(2);
printf("check signal in main after pthread_create...\n");
signal_check();
pthread_mutex_lock(&lock);
while (quitflay==0)
pthread_cond_wait(&waitloc, &lock);
pthread_mutex_unlock(&lock);
quitflay = 0;
sigprocmask(SIG_SETMASK, &oldmask, NULL);
exit(0);
}
运行结果如下:
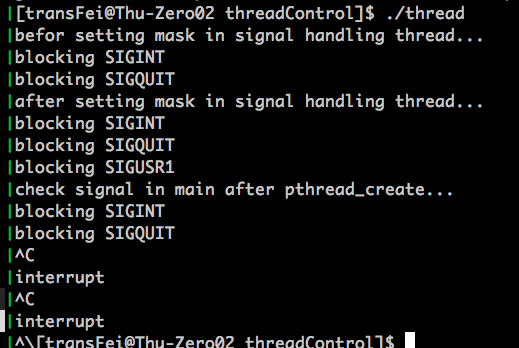
上述代码为了验证各个线程间signal mask的独立性,专门在thr_fn中多屏蔽了一个SIGUSR1,看看main线程是否会收到影响。结果是main线程的signal mask并没有收到影响。再总结一下:
(1)从main中pthread_create()这地方开始,产生了一个新的线程,同时新的线程继承了main线程中的signal mask;这也就是为什么thr_fn上来就已经把SIGINT和SIGQUIT给屏蔽了
(2)紧接着,在thr_fn中再把SIGUSR1给屏蔽了,马上thr_fn中就体现出来屏蔽SIGUSR1了;随后再检查main线程中的屏蔽信号,还是SIGINT和SIGQUIT两个,thr_fn中屏蔽的SIGUSR1并没有影响到main线程中对SIGUSR1的处理方式。
结合以上两点,可以直观理解每个线程的signal mask都是独立的。
还想继续探究,当pthread_create()执行时,有关信号处理的方面到底发生了什么?查阅了如下的资料:

更具体的参见:http://man7.org/linux/man-pages/man3/pthread_create.3.html
12.9 Threads and fork
这里的核心在于如何在多线程+多进程环境下处理锁的问题。
首先需要回顾一下8.3节的fork函数,尤其是copy-on-write的优化的fork实现方法:
(1)fork出一个child process后,parent process和child process的地址空间并非完全独立
(2)为了提高效率,如果parent process中的变量虽然copy给了child process,但只是对这个变量有“读"的操作是不会在child process中给这个变量再内存中开辟一个独立的新的地址的;只有对这个变量有“写”的操作了,这时候才会给这个变量在child process中完全独立开辟内存空间
以上是copy-on-write的fork的背景知识。
再说一下多线程状态下的fork:
(1)fork之后,copy到child process中只有一个线程,parent process中哪个线程fork的,就copy那个线程
(2)如果copy到child process中的那个线程中,有被lock住的mutex,则这种lock的状态也会被child process所继承
这里的问题就在于,很可能真正lock住mutex的那个线程并没有被copy到child process中,这样就容易出现死锁的问题(因为child process中没有那个对mutex实际锁住的线程,并且mutex是独立的,也就永远不会获得那个线程中解锁的操作了)。
书上给出的是一种比较暴力的方法:在fork的时候,把各种需要打开的锁都unlock了。
为了解决上述的问题,给出了相关的系统函数:
pthread_atfork(void (*prepare)(void), void (*parent)(void), void (*child)(void));
这个函数就是一个注册用的函数,在执行fork的时候被触发。几个参数的意义如下:
(1)prepare : 在fork出child之前用;获取所有的locks
(2)parent : 在fork出child之后,但fork return之前用;在父进程中解锁
(3)child : 在fork出child之后,但fork return之前用;在子进程中解锁
先看一个例子:
#include <pthread.h>
#include "apue.h"
pthread_mutex_t lock1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t lock2 = PTHREAD_MUTEX_INITIALIZER;
void prepare(void)
{
int err;
printf("preparing locks...\n");
/*养成这种容错编程的习惯 否则出错了都不知道是哪出的错误*/
if ((err=pthread_mutex_lock(&lock1))!=0) {
err_cont(err, "can't lock lock1 in prepare handler");
}
if ((err=pthread_mutex_lock(&lock2))!=0) {
err_cont(err, "can't lock lock2 in prepare handler");
}
}
void parent(void)
{
int err;
printf("parent unlocking locks...\n");
if ((err=pthread_mutex_unlock(&lock1))!=0) {
err_cont(err, "can't unlock lock1 in parent handler");
}
if ((err=pthread_mutex_unlock(&lock2))!=0) {
err_cont(err, "can't unlock lock2 in parent handler");
}
}
void child(void)
{
int err;
printf("child unlocking locks...\n");
if ((err=pthread_mutex_unlock(&lock1))!=0) {
err_cont(err, "can't unlock lock1 in child handler");
}
if ((err=pthread_mutex_unlock(&lock2))!=0) {
err_cont(err, "can't unlock lock2 in child handler");
}
}
void * thr_fn(void *arg)
{
printf("thread started...\n");
pause();
return 0;
}
int main()
{
int err;
pid_t pid;
pthread_t tid;
if ((err=pthread_atfork(prepare, parent, child))!=0) {
err_exit(err, "can't install fork handlers");
}
if ((err=pthread_create(&tid, NULL, thr_fn, 0))!=0) {
err_exit(err, "can't create thread");
}
sleep(2);
printf("parent about to fork...\n");
if ((pid=fork())<0) {
err_quit("fork failed");
}
else if (pid==0) {
printf("child returned from fork\n");
}
else {
printf("parent returned from fork\n");
}
exit(0);
}
程序运行结果如下:
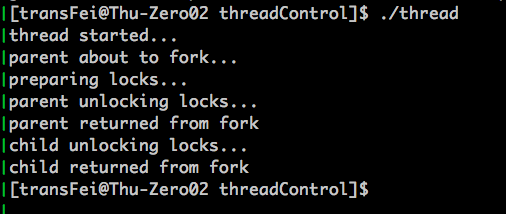
分析如下:
(1)prepare最先执行,而且是在fork出child之前执行的。为什么要有这么一个prepare?因为,如果敢在多线程条件下用fork,就必须保证fork中涉及的各个mutex的状态都得是可控的(即不能被其他的线程lock住)。这也就解决了之前提到的一个问题,“如果copy到child process的线程中有mutex被原来父进程中的某个线程锁住了怎么办?”;因为,如果一旦prepare对所有相关的mutex都获得控制权了,自然就可以避免上面的问题了。
(2)parent handler在fork出child之后,但是fork return之前执行;child handler在fork出child之后,但是fork return之前执行。这里还有一个问题:为什么给人感觉prepare加锁只有一次,但是parent handler和child handler却解锁了两次?这个问题书上说的很清楚,这是由于copy-on-write的fork实现策略给人造成的错觉。的确,在prepare获得mutex控制权的时候,lock1和lock2在内存中只有一份的;但是一旦parent handler或child handler对lock1和lock2有写操作了,马上就会先给child process在内存中独立分配出一套新的lock1和lock2变量。因此,parent handler中的解锁是针对原来的lock1和lock2,而child handler中的解锁是针对新的lock1和lock2。这样的操作是没有问题的。
书上还给出了多次调用pthread_atfork的分析,但这部分没有例子。
我的理解就是,这是针对locking hierarchy的操作,强调多个pthread_atfork的注册顺序和执行顺序。
背景:A模块调用B模块,两个模块都有各自的锁(A中有lock1 lock2,B中有lock3 lock4);现在要fork,该怎么处理?
方法:这种情况下,A的锁再外面,B的锁在里面;因此针对B的pthread_atfork一定要在A前面注册
执行顺序:parent handler和child handler按照注册顺序去调用;而prepare按照与注册相反的顺序去调用
这里需要理解两个问题:
(1)为什么prepare的执行顺序要与注册顺序相反(注意,这里B的pthread_atfork是先于A的pthread_atfork的)?原因就是,为了在获得锁的控制权的时候,依然保持原来的hierarchy;如果prepare获得了B中的锁,此时如果父进程中的A模块正等着B中的锁才能往下进行呢?于是就憋住了,形成死锁了。反之,如果能够获得A的锁,就从源头保住了不会出现A等着B的锁才能往下进行的死锁情况。这个内容,后面最好写一个例子。
(2)为什么parent handler和child handler的执行顺序与注册顺序相同了呢?我理解就是,加锁顺序是lock1 lock2 lock3 lokc4,那么解锁的顺序就应该是lock4 lock3 lock2 lock1。由于B中的pthread_atfork是先于A中的pthread_atfork注册的,所以parent handler和child handler就是按照注册的顺序执行,就符合解锁顺序了,不会造成死锁问题。
完毕。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号