
第一次个人编程作业
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 完成论文查重程序 |
github仓库地址:
https://github.com/Xb2555/Xb2555
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间 | 10 | 5 |
| Development | 开发 | 20 | 30 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 20 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 10 | 10 |
| Coding | 具体编码 | 20 | 20 |
| Code Review | 代码复审 | 10 | 8 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 15 |
| Reporting | 报告 | 20 | 30 |
| Test Repor | 测试报告 | 20 | 15 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 210 | 228 |
计算模块接口的设计与实现过程。
-
代码组织
- 分词模块:将输入的文本分词。
- 向量构建模块:将分词结果转换为词频向量。
- 相似度计算模块:基于词频向量计算余弦相似度。
-
类与函数设计
- Main 类:包含主程序逻辑和核心方法。
- JiebaSegmenter 类:第三方分词工具类(来自 jieba-analysis 库)。
- calculateCosineSimilarity:计算两个文本的余弦相似度。
- segmentWords:对文本进行分词。
- buildVector:构建词频向量。
-
函数之间关系
- calculateCosineSimilarity 是核心函数,负责调用其他函数完成以下任务:
- 调用 segmentWords 对输入文本进行分词。
- 调用 buildVector 构建词频向量。
- 计算余弦相似度并返回结果。
- segmentWords 依赖于 JiebaSegmenter 进行分词。
- buildVector 将分词结果转换为词频向量,供 calculateCosineSimilarity 使用。
- calculateCosineSimilarity 是核心函数,负责调用其他函数完成以下任务:
-
算法关键点
-
分词
- 使用 JiebaSegmenter 对中文文本进行分词。
分词结果是一个词语列表,例如:
输入:"我爱北京天安门"
输出:["我", "爱", "北京", "天安门"]
- 使用 JiebaSegmenter 对中文文本进行分词。
-
词频向量构建
- 使用一个 Map<String, int[]> 来存储词频向量。
Key:词语。
Value:一个长度为 2 的数组,分别表示两个文本中该词语的频率。
- 使用一个 Map<String, int[]> 来存储词频向量。
-
余弦相似度计算
- 计算步骤:
- 计算点积:dotProduct = sum(A_i * B_i)。
- 计算向量的模长:norm1 = sqrt(sum(A_i^2)),norm2 = sqrt(sum(B_i^2))。
- 计算相似度:dotProduct / (norm1 * norm2)。
- 计算步骤:
-
-
独到之处
-
中文分词的支持
-
使用 JiebaSegmenter 对中文文本进行分词,能够准确处理中文词语的切分问题。
-
分词结果转换为小写,避免大小写对相似度计算的影响。
-
词频向量的高效构建
- 使用 Map<String, int[]> 存储词频向量,避免了稀疏向量的存储问题。
- 通过一次遍历即可完成两个文本的词频统计,时间复杂度为 O(n)O(n),其中n 是词语总数。
-
余弦相似度的高效计算
- 通过一次遍历词频向量,同时计算点积和模长,避免了多次遍历。
-处理了分母为零的情况,避免除零错误。
- 通过一次遍历词频向量,同时计算点积和模长,避免了多次遍历。
-
模块化设计
- 将分词、向量构建、相似度计算分离为独立的函数,便于扩展和维护。
- 例如,如果需要支持英文文本,可以替换分词模块,而不影响其他部分的逻辑。
-
计算模块接口部分的性能改进
-
性能分析
- 分词阶段
- 使用 JiebaSegmenter 对两个文本进行分词。
- 分词时间复杂度为O(n),n为文本长度
- 假设两个文本的长度分别为n1和n2,则分词阶段总时间复杂度为O(n1+n2)
- 向量构建阶段
- 遍历两个分词结果列表,构建词频向量。
- 假设两个文本的分词结果总数为m,则构建词频向量的时间复杂度为O(m)
- 相似度计算阶段
- 遍历词频向量,计算点积和模长。
- 假设词频向量的大小为k,则计算相似度的时间复杂度为O(k)
- 分词阶段
-
改进思路
- 高效处理中文分词
- 使用 JiebaSegmenter:
- Jieba 是中文分词领域广泛使用的工具,分词准确且性能较好。
- 分词结果转换为小写,避免大小写对相似度计算的影响。
- 词频向量的高效构建
- 使用 Map<String, int[]> 存储词频向量:
- 通过哈希表存储词频,避免了稀疏向量的存储问题。
- 一次遍历即可完成两个文本的词频统计,时间复杂度为O(m)
- 高效处理中文分词
计算模块部分单元测试展示
- 测试 segmentWords 方法:
- 准备一段中文文本。
- 调用 segmentWords 方法进行分词。
- 验证分词结果是否符合预期。
// 中文分词
//测试中文分词函数
@Test
public void testSegmentWords() {
JiebaSegmenter segmenter = new JiebaSegmenter();
String text = "我爱软件工程";
List<String> words = Main.segmentWords(segmenter, text);
// 验证分词结果
List<String> expected = Arrays.asList("我", "爱", "软件工程");
assertEquals(expected, words);
}
- 测试 calculateCosineSimilarity 方法:
- 准备两段中文文本。
- 调用 calculateCosineSimilarity 方法计算相似度。
- 验证计算结果是否在合理范围内。
//测试计算余弦相似度函数
@Test
public void testBuildVector() {
List<String> words1 = Arrays.asList("apple", "banana", "apple");
List<String> words2 = Arrays.asList("banana", "orange", "banana");
Map<String, int[]> vectorMap = new HashMap<>();
Main.buildVector(words1, vectorMap, 0);
Main.buildVector(words2, vectorMap, 1);
// 验证词频向量
assertArrayEquals(new int[]{2, 0}, vectorMap.get("apple"));
assertArrayEquals(new int[]{1, 2}, vectorMap.get("banana"));
assertArrayEquals(new int[]{0, 1}, vectorMap.get("orange"));
}
- 测试 main 方法:
- 模拟命令行参数。
- 创建临时文件作为输入和输出文件。
- 调用 main 方法。
- 验证输出文件中的内容是否符合预期。
//测试命令行输入及输出
@Test
public void testMain(@TempDir Path tempDir) throws IOException {
// 创建临时文件
File originalFile = tempDir.resolve("original.txt").toFile();
File plagiarizedFile = tempDir.resolve("plagiarized.txt").toFile();
File outputFile = tempDir.resolve("output.txt").toFile();
try (BufferedWriter writer = new BufferedWriter(new FileWriter(originalFile))) {
writer.write("我爱北京天安门");
}
try (BufferedWriter writer = new BufferedWriter(new FileWriter(plagiarizedFile))) {
writer.write("我爱北京天安门");
}
// 模拟命令行参数
String[] args = new String[]{
originalFile.getAbsolutePath(),
plagiarizedFile.getAbsolutePath(),
outputFile.getAbsolutePath()
};
// 调用 main 方法
Main.main(args);
// 验证输出文件内容
try (BufferedReader reader = new BufferedReader(new FileReader(outputFile))) {
String result = reader.readLine();
assertEquals("100.00%", result);
}
}
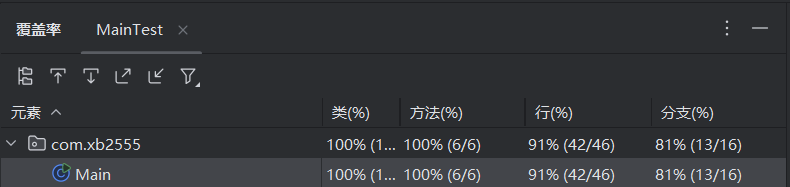
单元测试覆盖率
计算模块部分异常处理说明
- 文件读取异常
- 设计目标
目标:处理文件读取过程中可能出现的错误,例如文件不存在、文件权限不足或文件损坏。 - 处理方式:捕获 IOException,并输出友好的错误信息,避免程序崩溃。
- 设计目标
@Test
void testReadFileWithIOException() {
// 模拟一个不存在的文件路径
String nonExistentFilePath = "non_existent_file.txt";
// 捕获异常并验证
Exception exception = assertThrows(IOException.class, () -> {
Main.readFile(nonExistentFilePath);
});
// 验证异常信息
assertTrue(exception.getMessage().contains("文件不存在"));
}
- 词频向量构建异常(空输入)
- 设计目标
目标:处理词频向量构建过程中可能出现的异常,例如分词结果为空。 - 处理方式:检查分词结果是否为空,避免空指针异常。
- 设计目标
@Test
void testBuildVectorWithEmptyWords() {
Map<String, int[]> vectorMap = new HashMap<>();
List<String> emptyWords = new ArrayList<>();
// 调用向量构建函数
Main.buildVector(emptyWords, vectorMap, 0);
// 验证词频向量为空
assertTrue(vectorMap.isEmpty());
}
- 余弦相似度计算异常(除零错误)
- 设计目标
目标:处理余弦相似度计算过程中可能出现的除零错误,例如两个文本的词频向量都为零。 - 处理方式:在计算相似度之前,检查模长是否为零,避免除零错误。
- 设计目标
@Test
void testCalculateCosineSimilarityWithZeroVectors() {
String emptyText1 = "";
String emptyText2 = "";
// 调用相似度计算函数
double similarity = Main.calculateCosineSimilarity(emptyText1, emptyText2);
// 验证相似度为 0
assertEquals(0.0, similarity, 0.0001);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号