CDH Hadoop集群重启导致的集群异常,namenode启动失败
在一次集群重启之后,发现namenode节点启动失败,通过日志查看发现如下问题,在网上搜了一大堆,大多数是建议执行
hadoop namenode -recover
尝试过执行,发现会出现连接拒绝的异常(后期排查确定是VPN)造成的,pass掉这一种方法之后,我选择了通过复制其中一个数据看上去较为正常的JournalNode数据到其他的JournalNode节点
复制完毕, 启动nomenode, 发现还是会有如下异常,
Failed to start namenode. java.io.IOException: There appears to be a gap in the edit log. We expected txid 22817733, but got txid 22817880. at org.apache.hadoop.hdfs.server.namenode.MetaRecoveryContext.editLogLoaderPrompt(MetaRecoveryContext.java:94) at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:213) at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadFSEdits(FSEditLogLoader.java:141) at org.apache.hadoop.hdfs.server.namenode.FSImage.loadEdits(FSImage.java:903) at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:756) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1152) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:799) at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:614) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:676) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:844) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:823) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1547) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1615)
查看 jn 目录下edit文件发现,正常的文件具有序号连续性,而edits_22817689-22817733之后,跟着的文件是edits_22817880-22817924,按理应该是edits_22817734-22817777
可以确定造成standby Namenode启动失败的原因是,异常宕机后的启动导致edits文件异常递增,而对应的文件索引没有增加.
同时也可以确定网上一系列的方法都不适用于当前情景,也尝试过删除edits_22817880-22817924文件只剩下22817733文件,重启 Namenode,出现新的问题:
java.lang.AssertionError: Decided to synchronize log to startTxId: 22817733 endTxId: 22817879 isInProgress: true but logger xxx.xx.xx.xx:8485 had seen txid 22818137 committed at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.recoverUnclosedSegment(QuorumJournalManager.java:337) at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.recoverUnfinalizedSegments(QuorumJournalManager.java:460) at org.apache.hadoop.hdfs.server.namenode.JournalSet$8.apply(JournalSet.java:624) at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:393) at org.apache.hadoop.hdfs.server.namenode.JournalSet.recoverUnfinalizedSegments(JournalSet.java:621) at org.apache.hadoop.hdfs.server.namenode.FSEditLog.recoverUnclosedStreams(FSEditLog.java:1478) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startActiveServices(FSNamesystem.java:1294) at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.startActiveServices(NameNode.java:1771) at org.apache.hadoop.hdfs.server.namenode.ha.ActiveState.enterState(ActiveState.java:61) at org.apache.hadoop.hdfs.server.namenode.ha.HAState.setStateInternal(HAState.java:64) at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.setState(StandbyState.java:49) at org.apache.hadoop.hdfs.server.namenode.NameNode.transitionToActive(NameNode.java:1644) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.transitionToActive(NameNodeRpcServer.java:1406) at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.transitionToActive(HAServiceProtocolServerSideTranslatorPB.java:107) at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4460) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2278) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2274) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2272)
很明显22817733文件是已经被提交的状态,删除新增的edits文件这种方式是不可行的,得另谋他路
考虑到hadoop集群实际数据是存储在datanode角色中的,namenode只是datanode的的管理者,namenode启动失败的原因是JournalNode在HA场景下数据验证失败;那么我们是不是可以重新安装一次namenode
就可以了?当然得留有余地,做好服务器的快照.然后在上CDH先关闭HA,再删除掉所有的namenode,和JournalNode,
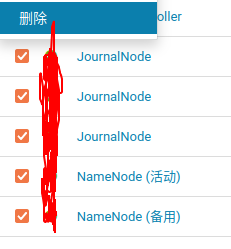
然后再正常添加角色实例,把删除掉的角色按照原来的服务器分布添加回来.重启HDFS,问题解决.
需要注意的是,如果新添加回来的角色没有启用HA的话,那么Hive有关的Shell ( Impala ) 在执行HQL时都会报一个:未知的hostname:nameservice1 (我这启用HA时使用的就是默认 hostname名:nameservice1)错误
原因是之前删除的HA角色是更改了Hive客户端配置文件的,新加的角色不会更新Hive客户端配置文件,而HQL是通过配置文件的nameservice1作为服务名取获取数据的, 那此时就需要需要用户手动更改,刷新Metastore
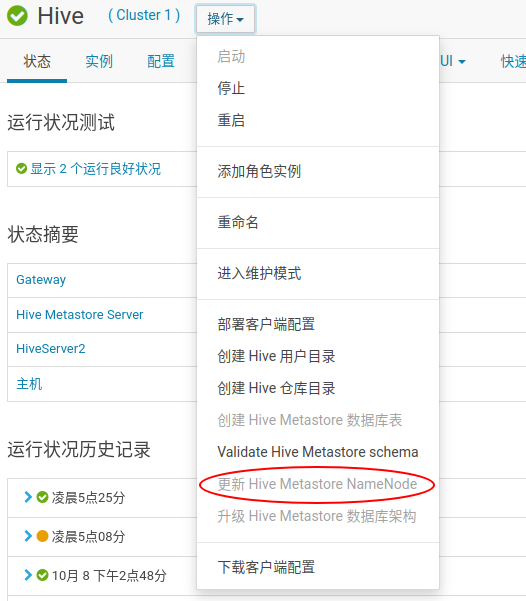
停止Hive, 然后就可以点击Update Hive Metastore NameNode 按钮了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号