记一次T-SQL查询优化 索引的重要性
概述
在一次调优一个项目组件的性能问题时,发现SQL的设计真的是非常的重要,所以写一篇博文来记录总结一下。
环境介绍
这个项目组件是一个Window服务,内部在使用轮循机会在处理一个事件表中的事件,将其转换在对应的任务。性能问题在于,统计下来,这个服务一秒的时间内只能处理完成12条左右。这个性能是非常的差。
我使用的SQL版本是SQL 2012,机器是CPU I7-2670,内存16G,SSD硬盘。
在这个数据库中有一个表的数据量大概30万条数据,并不是很多, 事先没有建立任何索引,只有一个主键的索引。

那么在这其中有一条非常简单的查询语句:
SELECT TOP 1 * FROM SMS_SHORTNO_ASSIGN WHERE APP_CODE = 'SMSNotice' AND IS_DYNAMIC_ASSIGN = 'N' AND SMS_TYPE_CODE = 'Mas'
有数据和无数据的性能对比
在上面的查询中,IS_DYNAMIC_ASSIGN = 'N'是查询不到任何数据的,IS_DYNAMIC_ASSIGN = 'Y'是有数据的,对比一下,在没有任何数据的情况下,查询是非常的慢,但是有数据的情况下,就不同了。
首先来看一下这个SQL的查询计划是什么样子:
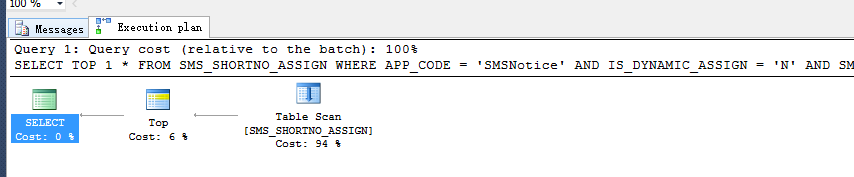
下面是更清晰的执行查询计划:

可以看到,在没有索引的情况下,会执行表扫描。
来看一下各自的执行时间:
可以查询到数据: |
不能查询到数据:
|

可以看到,在没有查询到数据的情况下,总共需要耗时89ms. 不要觉得89ms才只有0.1s都不到,但是想一想之前上面说的1S钟才处理12条记录,就可以想像到和这个89ms有相当大的关系,如果只执行这一条SQL,那么1S钟也只能执行12条左右。
在这种情况下,我们来优化一下这条SQL语句。首先这句SQL本身已经是最简单的,不能再简化,那么只有在索引上下功夫。
聚集索引和非聚集索引
两者之间有什么区别呢?大家可以参考一篇博客圆另一博主的博文 聚集索引和非聚集索引(整理)。
首先我们按照我们一般没有深入研究过索引童鞋们的思路,就是把WHERE后面条件的字段加起来建一个索引。
根据WHERE 条件字段创建非聚集索引

创建后好,我们来看看上面的语句的查询计划:

咦,为什么还是使用了表扫描呢,而不用使用索引呢?
在这里贴上一篇博文 Select * 一定不走索引是否正确? 这篇博文分析了SELECT * 和各种索引的关系,但是这个博文里面分析的和我得出的结论不一样,我也在作者的评论留言了,同时我找到别一篇博文 SELECT * 的真相: 索引覆盖(index coverage) 来解释我现在的现象。因为我不怎么研究SQL,所以我不清楚到底是什么原因,望有知者,可以告知一下。关于索引覆盖也可以参考这篇博文 SQL Server 查询性能优化——覆盖索引(二)。
那么我现在将SELECT * 改成 SELECT 字段后,索引才真正的应用了。

可以看到如果SELECT中的字段包含在索引中,将可以利用到索引。
但是这样的话,改变了我原来程序的用意,这是不能接受的。那有什么别的办法可以解决吗?这个时候我想到了聚集索引。
创建聚集索引
默认情况下,在使用表设计器的创建表的时候,会默认创建一个主键的聚集索引。根据主键创建聚集索引,并不一定是最优的选择。关于聚集索引 可以参考下 索引优化(2)聚集索引 。我观察了一下我的表结构,我根据可能使用的列频率最高的两个字段上建立了聚集索引,这两个字段包含在上述语句的WHERE语句中。这两个字段并不是主键。

创建好后,我们再来看一下查询计划和查询的时间:

查询时间:
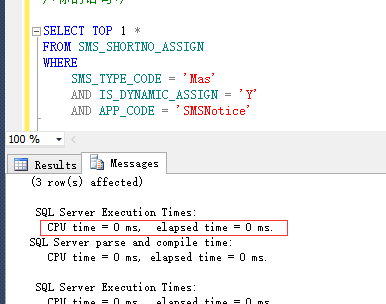
可以看到,查询速度已经0ms了,非常的快速了。到这里面,其实问题关于这一条SQL优化应该是已经结束了。
聚集索引很重要并且一个表只能建一条聚集索引,不能根据某一条SQL的WHERE来建立,而是要考虑到各种不同的WHERE条件才确定这样建立聚集索引是不是最优的,我根据这两个字段建立好聚集索引后,我使用别的WHERE来查询,速度也是非常的快,所以最后才确认使用这两个字段建聚集索引。
当然我的项目中还是有很多的语句可以优化,以及程序C#代码本身也可以优化,经过我的优化后,处理速度可以达到1秒处理130条左右了。
题外篇
===========================题外篇=======================
在学习这个优化过程中,还有一些别的心得和疑问的,也在此记录一下。
根据上面我创建一条聚集索引就解决了问题,并且也建立了非聚集索引,非聚集索引反而没有用上,那么是不是说非聚集索引就没有用呢?并不是这样的,非聚集索引是SQL优化的很大的一部分。
之前上面说道SELECT中只包含索引列的情况下会使用到非聚焦索引。那么下面再说一个例子来说明非聚集索引的用途。
我们们将之前建立的三个字段的非聚集索引删除,使用统计函数来统计一下符合条件的条数:

查询时间:

可以看到耗时还是很久28ms的. 大家不用关注COUNT(*)可以使用COUNT(1)或Count(主键),这个讨论网上也很多,我自己切换三种写法也没有什么本质的不同。
这时,我们将之前删除的非聚集索引加回来,再来查看查询计划和时间:


可以看到查询计划中,这个时候优先使用了非聚集索引,并且统计的速度是要快过使用聚集索引的。
疑问(求答疑)
在别一个SQL中,也是很简单的SQL,使用了LEFT JOIN后,会导致查询的性能不高,在这种情况下,该如何来优化呢,我使用了not Exists,子查询来各种替换并不能减少这个SQL的查询时间。
业务场景是这样的,SQL还是和之前的一样,SMS_SHORTNO_LOCKED表里面会存入SMS_SHORTNO_ASSIGN表里面的记录,锁定的时候会增加一条,解锁的时候会将这条记录删除,所以在此使用LEFT JOIN来取出一条没有锁定的记录。
下面是它的查询语句和查询计划和响应时间:

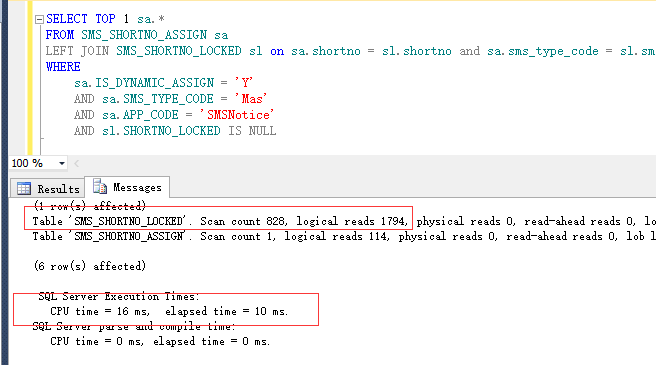
这个26ms最主要是在SHORTNO_LOCKED IS NULL这条判断上,如果不是使用IS NULL,而是使用 SHORTNO_LOCKED = 1或=0这种方法来判断的话,查询是非常的快。
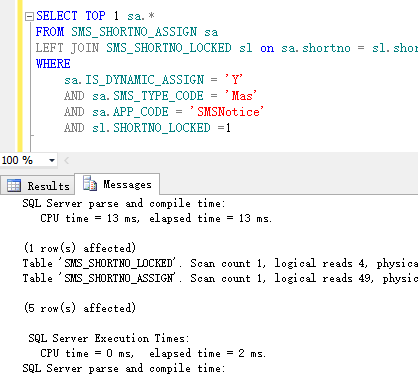
那么在此,请问一下大家,相信很多人都使用LEFT JOIN,然后使用IS NULL来判断别一个表没有的数据。但是这样的性能并不是很高,有什么办法可以解决LEFT JOIN的问题,或者可以改成别的写法,我尝试了很多种都没有改善。
所以我想难道以后在设计表的时候,是不是尽量使用 INNER JOIN ,然后根据某一个字段判断特定的值,这样的话,这个字段可以使用索引来优化,像上面就因为IS NULL的问题是没办法使用索引的。
希望有高人指点,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号