树模型之Boosting算法总结中篇
XGBoost
讲的非常好的链接:https://snaildove.github.io/2018/10/02/get-started-XGBoost/
开始的优化目标根据加法模型和MSE的推导可以变成和第t棵树的一阶导和二阶导的关系, 再利用ft等于样本所在叶子节点上的权重,可以得到目标函数和样本的所在叶子的一阶导和二阶导的关系。每一树的小目标是找到样本所在叶子的权重,模型的大目标是计算样本的一阶导和二阶导。节点分裂依据是:\({二阶导^2}/{一阶导}\)的信息增益,计算没有分裂和分裂之后的信息增益数值。最好分裂节点的查找过程是:1. 对每个特征的按照特征值进行排序,2.在每个特征上进行线性扫描,计算每个分裂点的信息增益,最后选择最大的信息增益分裂点作为分裂点。剪枝和正则化:从叶子开始递归减去负增益的节点。(GBDT是计算到负信息增益就停止)
XGBoost最近很流行的一种算法,在GBDT算法上改进了精度和性能。
- 在精度上的改进:
- 目标函数加入正则化项和损失函数使用。之前的GBDT残差是MSE损失函数的一阶导数,现在使用其他损失函数,并且加入其二阶导数的信息。
- 正则化项是CART回归树的生成和叶子节点的数量和叶子节点的得分有关.
- 处理缺失值。实际运用中,输入很可能是稀疏的。有很多种可能造成数据是稀疏的:1) 数据中的缺失值; 2)较多的0值;3) 类似one-hot的特征工程。之前处理方式存在的问题是:树分裂选择特征时候,直接忽略这些特征。对于这些缺失值,xgboost将样本分类到默认分支上去,而默认分支是提出的non-missing value算法学习到的。选择特征的时候会考虑有missing的特征。具体方法是: 会忽略该特征值为missing的样本,只统计该特征值为non-missing的样本. 同时考虑将该特征值为missing的样本分为左子树和右子树的情况,选择特征增益大的方向进行分裂。使用了该方法,相当于比传统方法多遍历了一次,但是它只在非缺失值的样本上进行迭代,因此其复杂度与非缺失值的样本成线性关系。
- 在性能上的改进:
- 缩放:衰减树的权重
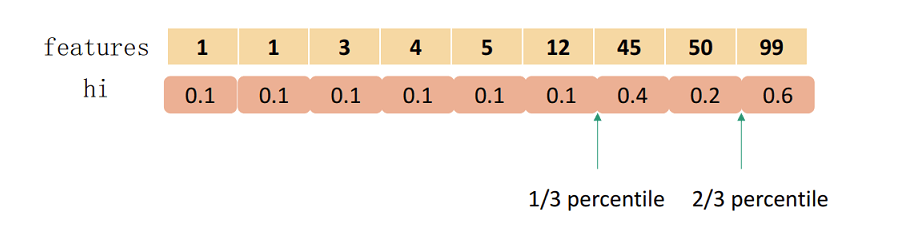
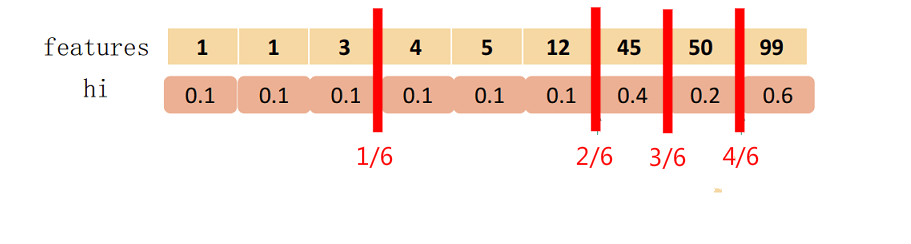
- 改进的查找分裂点算法。在单机上使用extract分裂点算法,在分布式系统上使用weight quantile算法。分裂点查找的近似算法,分为全局分桶和局部分桶,全局设置小的eps,全局设置多次使用, local设置大的eps,在每次分裂节点的时候重新执行。带权重的近似分位数方案:把最后的obj凑平方项,可以得到\({h_i(f_t(x_i)-(-g_i/h_i)}^2+正则化项和常数项\)的结果,可以视为标签为\(-g_i/h_i\), 且权重为\(h_i\)的平方误差。所以我们\(h_i\)作为分位数的权重。查找分位数的时候根据相邻点的权重不超过eps的标准来找。
- 缺失点的分裂点查找。比较缺失值进入左右子树后的一阶导和二阶导的信息增益的,取信息增益大的。
- 采用CSR对全局特征进行排序。在训练之前就进行预排序,然后保存成block数据,存储数据的内容,行号,列号。所以遍历特征的取值的时候只要遍历values数组就可以了,只有反复用这个数据就可以了。
- 预缓存的方式提高读取梯度的速度,梯度索引来保存的,但是梯度的获取顺序是按照特征的大小来读取的,会导致多次非连续内存访问,可能导致CPU的cache缓存命中率很低,所以用缓存预期的方式。先给每个进行分配一个buffer,读取梯度信息到buffer中待用,这样对训练大样本的时候特别有用。
- 多线程并行,XGB的并行是发生在树向下分裂节点的时候. 它会把所有的数据放在一个共享内存中, 分裂的时候,将特征分成多组,每个线程计算一组特征,底层调用的是用C语言的OpenMP库。同时, 针对内存无法放下的数据问题, 统一的多节点的API借口正在开发中,未来可能会使用C++的后端+Yarn分布式系统.
模型评价(准确率,时间,空间,模型复杂度,过拟合,抗噪声,是否可并行化,调参)
- 准确率: 可以处理分类和回归问题, 但是完全依靠调参才能取得好的效果
- 时间: 速度很快
- 需要树的棵树较少
- 减少了预排序的次数
- 优化找到分裂最优点的方式
- 内存: 用了block数据结构,省空间
- 模型复杂度: 用了损失函数的一阶导和二阶导信息, 同时加入了节点的样本个数和节点得分作为正则化项
- 过拟合: 也是用了缩减率和采样率防止过拟合
- 抗噪声: 使用了行采样和列采样,所以就对噪声不敏感.
- 训练树的子样本比例. 设置成0.5 意味着XGBoost随机搜集一般的样本来训练树
- 训练特征的特征比例.
- 每个级别中每个拆分的列的子样本比例. 指的应该是树分裂时选择的候选特征的比例.
- 是否可并行化: 分裂特征并行化
- 调参:0
- 通用参数: 树的棵树,深度, 叶子节点的最小样本数量, 采样比例, 缩减比例
- booster参数: 目标函数,损失函数,多线程的数量
优点
- 不仅支持决策树作为基分类器,还支持线性分类器
- 用到了损失函数的二阶泰勒展开,因此与损失函数更接近,收敛更快
- 在代价函数中加入了正则项,用于控制模型复杂度。正则项里包括了树的叶子节点个数和叶子结点输出值的L2范数,可以防止模型过拟合
- 内置了交叉验证。节省验证集
- 可以随时保存模型,下一次运行在上一次保存的模型基础上开始
- 良好的可拓展性和接口,支持spark、Java、Scala、Spark-Scala、Flink-Scala;支持导入HDFS,Apache Hadoop S3(S3)
- 支持Pipeline
- 支持early_stopping
QA
-
为什么XGBoost使用损失函数的一阶导和二阶导?
二阶偏导相当于找到了一阶导数的下降方向, 会使梯度下降的更快, 收敛的更快. -
为什么可以使用近似搜索算法?
虽然使用直方图会降低模型的准确率,但是决策树本身就是弱模型, 分割点不是很精确对最后的结果影响不大,
较粗的分割点也有正则化的效果, 可以有效防止过拟合.
同时梯度提升的框架对每次模型的结果的要求不是很高! -
为什么XGBoost使用泰勒展开?
使用泰勒展开可以在不确定损失函数的情况下分析算法优化, 本质上是把损失函数的选取和模型的优化分开了, 是一种去耦合的方式. 增加了XGBoost的适用性. -
为什么机器学习比赛中很少用使用SVM?
SVM的输入数据适合数值型
XGBoost模型的良好可扩展性 -
为什么XGBoost适合比赛?
深度神经网络通过不同step的网络可以对时空信息建模,就很适合图像, 声音, 文字等带有时序特质的数据.
基于树模型的XGBoost则能很好地处理表格数据,同时模型的可解释性、输入数据的不变性、更易于调参等特质更适合数值型数据. -
为什么XGBoost用很低的深度就可以学到很好的精度,一般6就很高了。但是DecisionTree/RandomForest的时候需要把树的深度调到15或更高,这是为什么?
RF是Bagging算法,同时在基分类器上采用了随机抽取样本和特征的方式,使得每个基分类器的精度下降,所以只有当决策树的深度足够深的时候,才能提高基分类器的精度。
XGBoost是Boosting算法,每个决策树都在之前决策树的基础上进一步提高了预测精度,所以就不需要很深的树就可以实现好的效果,反之选择深度小的,可以防止过拟合。 -
如果用其他模型换掉XGBoost的,哪种模型(知识广度)
最好的替代品是LightGBM
针对分类任务: 基础的SVM, LR
针对回归任务: 基础的Lasso, 岭回归
XGBoost的调参经验
- 确定线性模型还是树,树模型(常用的)
- 确定object学习目标:线性回归,逻辑回归,二分类的逻辑回归(输出是概率还是类别),多分类(输出是概率还是类别)
- 调节的参数:基分类器的数量,每棵树的深度,内部节点分裂的最小样本数量和叶子节点的最小样本数量。学习率,使用的特征数量,使用的样本数量。网格搜索,先是大范围再小范围。
LightGBM
参考链接:https://blog.csdn.net/anshuai_aw1/article/details/83659932
优化
- 算法优化
- 带深度限制的叶子生长策略。之前向下生长树的时候, 同时分裂同一层叶子, 容易进行多线程, 但是存在的问题不加区分的对待同一层的叶子,如果叶子的分裂增益很低没必要继续分裂.所以为了解决这个问题, 在生长的时候,每次从当前叶子中找到分裂增益最大的一个叶子进行分裂。缺点是可能找出深度很深的树,容易过拟合,所以LightGBM做了最大深度限制,保证高效率的同时防止过拟合。
- 单边梯度采样算法(Goss)。算法认为梯度变化较小是较高的准确率,所以算法要针对梯度变化较大的样本,所以采样变化和较小的样本。具体是:按照梯度降序,取大梯度的a%的样本,取(1-a)*b%小梯度样本,为了不改变数据分布,加大小梯度的权重。使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGB遍历所有特征值节省了不少开销。
- 互斥稀疏特征绑定(EFB)。使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。GBDT直接忽略0值的特征,但是基于直方图的算法无论是否是0值都需要进行遍历。将不互斥的特征(同时取非0的特征)捆成一团,团和团之间是互斥的,按照团寻找最佳分裂特征进行分裂。互斥的定义是不同时为0的特征,意思就是特征上一个数值为0,一个数值为1,这样叫做互斥。这样能最大保留特征的信息。使用贪心算法求解互斥团。同时,为了减少束的个数,允许团内特征存在冲突,也就是存在同时为1的状况。求解的时候是先建立一个图,然后检查排序后的每个特征,对他进行新的绑定使得总体的冲突更小。形成团之后,将一个团之内的特征concat在一起,通过位移表示新的特征。A特征的原始取值为区间[0,10),B特征的原始取值为区间[0,20),我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为[10,30),这样就可以放心的融合特征A和B了。 按照非零值的数量排序,因为非0值越多,同时非0值的概率越大,冲突越大。
- 性能优化:
-
直方图算法
连续特征按照等宽的方式离散化,离散特征按照等频的方式离散化,然后为每个特征值建立一个bin桶,会直接忽略出现样本量很少的桶。如果bin桶的个数<=4,直接OVA方式处理。默认的桶是256。使用时计算每个桶内一阶导和二阶导,对桶从大到小排序,把桶作为划分点。
注意离散值和连续值的桶区别!
流程:
- 首先,对于每个特征建立一个离散值的划分区间(桶), 其中保存了所有样本的二阶导数之和和样本个数.
- 分配所有的样本到每个桶中
- 遍历所有的桶,计算以当前桶作为分割点, 所有左边桶的所有样本的梯度和,所有右边桶的所有样本的所有梯度和(由父节点的梯度和和左边的梯度相减得到)
- 带入公式\(Loss=\frac{s_{L}^{2}}{n_L}+\frac{s_{R}^{2}}{n_L}-\frac{s_{p}^{2}}{n_p}\), 计算增益
- 选择增益最大的桶的特征和特征值作为分裂的最优特征.
这种方式使用三重循环,看者很复杂,但是具体思考复杂度:但是lgb是深度树,叶子节点不是很多,如果是计算过的节点就不会在计算了。第二步就是分配空间和对应索引,这个可以速度比较快,不计入考虑遍历所有样本,计算梯度,全局计算一次梯度就好。重点是分割点的数量比直接分割特征的数量少了非常多,所有直方图在大数据量上的优势非常大。直方图在数据存储和查询中使用较多,有相关研究,比如基于数据分割的直方图,基于单元格密度的直方图,基于欧拉和闭欧拉直方图的方式。 -
直方图差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到, 在分裂节点的时候, 计算玩所有左孩子的直方图之后, 直接用父节点的直方图-左孩子的直方图就可以得到右孩子的直方图。参考链接:https://blog.csdn.net/anshuai_aw1/article/details/83040541 -
支持类别属性特征(不需要one hot),直接计算类别的出现次数作为直方图。
-
特征并行
在不同的机器在不同的特征集合上分别寻找最优的分割点, 然后再机器间同步最优的分割点. -
数据并行
让不同的机器先在本地构造直方图, 然后进行全局的合并,然后在合并的直方图上寻找最优的分割点.
QA
-
XGBoost的近似搜索算法和LightGBM的直方图算法有什么区别?
XGBoost的近似搜索算法是保存所有样本的二阶梯度, 用分位数确定划分方法,他的分割点是可以直接通过计算总的样本梯度和和分位数点得到的.
LightGBM算法是将所有样本放进对应的桶中,并以当前桶作为划分点, 计算左右桶的最大增益.它的最优点是遍历所有的桶才能得到的. -
为什么LightGBM也使用了直方图,但是速度依然比较慢?
XGB只在分布式系统中使用直方图,单机没有使用直方图优化,所以单机速度较慢。

