2019腾讯广告大赛总结
腾讯广告大赛的数据是腾讯系产品投放广告的真实数据,比赛问题直接对标广告投放逻辑的召回广告的CTR问题和排序广告的CTR问题,最后要求预估广告的曝光量。数据类型多样、数据量达上百万至上亿,要求预测曝光量。这类比赛十分对口机器学习和数据挖掘以及推荐算法专业的同学,所以推荐感兴趣的同学积极参加。同时在这里我将第一次参加比赛的经验总结下来,有需要的同学可以参考借鉴。
1. 赛题理解
比赛分为初赛和复赛两个题目:
-
初赛是: 给定的数据集如下表所示:
数据名称 数据解释 历史n天的曝光广告的数据 最终用户看到的广告id 用户数据 用户的基本特征,包括用户id、用户学历、用户所在区域等 广告数据 广告的基本特征,包括广告的尺寸、广告位、广告类型 广告操作特征 设置广告报价、允许展出时间等操作记录 测试集是新的一批广告设置(有完全新的广告id, 也有老的广告id修改了设置), 要求预估这批广告的日曝光。
其实问题对应实际业务中的召回问题, 召回本质的本质是海量数据中快速找到匹配用户特征的大批样本, 做海量的规则匹配, 所以其实模型的精细度要求不高, 对机器的性能要求很高. 但是在比赛中这点问题不存在
但是比赛的难点是通过召回的广告记录和所有的广告预测曝光量。根据我在推荐实习的经验来看,召回的广告即使被召回了也会被各种业务策略和模型排序确定最终的CTR分数, 只有topk的广告会被展示, 那么从中间到最后展出的过程被缺失, 无法直接预测. 所以初期我们的模型直接选用了最快的LightGBM+6个特征,全靠trick进入复赛.
所以有时候做比赛也需要一些trick和运气😌
-
复赛是: 复赛比初赛多给了一个用户广告请求竞价记录表,也是每个用户请求后召回的广告列表。所以全部数据统计如下:
数据名称 数据解释 历史n天的曝光广告的数据 最终用户看到的广告id 用户数据 用户的基本特征,包括用户id、用户学历、用户所在区域等 广告数据 广告的基本特征,包括广告的尺寸、广告位、广告类型 广告操作特征 设置广告报价、允许展出时间等操作记录 广告请求的竞价记录 一个用户id对应200条广告记录,最终一个用户可能看到1-2个广告,一个广告一天会多次请求召回 问题对应的实际业务中的精排过程, 只有被召回的广告才有机会曝光, 200个召回中大约有1-2被曝光.
问题的难点在与建模方式和数据的构建. 一种是直接建模, 一种是间接建模. 直接建模是统计每个广告每天的曝光量作为label, 直接预测最后的曝光量, 这种方式简单, 数据量小, 容易操作. 一种是间接建模, 预测被召回的广告是否被曝光, 统计最后的曝光. 这种方式需要将请求队列和广告拼接起来, 拼接后的数据量达到7亿, 服务器也没有办法处理, 同时,大量的广告是没有曝光的, 所以正负样本分布差距非常大, 对模型挑战很大. 所以我们最后选择了第一种方法, 把整个问题当作预估CTR问题来处理.
-
评价指标:
- 单调性: 出价越高, 曝光量越高
- SAMPE: 对称均方根误差,
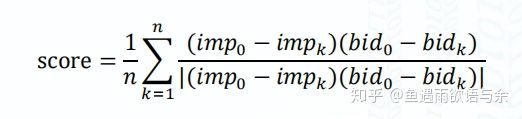
2. 建模方式
-
初赛是选用所有在一天中没有操作的广告数据, 我们认为没有操作的广告的出价和状态是可以完全对应当天的曝光数据. 但是现在分析看来, 我们对操作数据的分析太少, 没有仔细考虑每次操作的内容, 比如修改的是广告状态? 出价和还是目标人群? 后来发现操作数据几乎每次都是修改出价, 但是出价特征完全没有被用到, 所以一开始我的数据构造方式就太复杂. 观察队友发现, 队友保留所有操作数据的广告, 训练数据量有40万. 效果就很好。看冠军公布的方案,抽取最近1个月和45天全部数据合成训练样本,得到的分数是89,比我们的分数高了8分.
-
复赛是选用历史记录中所有召回的广告
3. 尝试模型
初赛只使用LightGBM,20万样本,10+个特征,3个离散特征,3个id特征,剩下的连续特征。
复赛使用以下模型:
1. LGB: LGB是我们比赛中重点使用的模型,也是所有参赛者广泛使用的模型, 很多参赛者的NN模型效果都没有LGB的效果好. LGB不需要处理缺失值和离散值, 随便就可以样本放进去的到的一个结果, 可以直接简单高效地验证想法, 所以我们一直用LGB做特征主模型和特征筛选. LGB的调参也主要调树的深度, 叶子节点的最小样本数量, 分类器数量, K折交叉验证, 防止过拟合.
2. LR: 只使用ID特征和离散特征, LR的效果特别好, 但是随着加入数值特征, LR的效果越来越差, 即使在LGB模型已经验证过能提分的特征加入, 效果也特别差, 所以LR模型只能作为初期的简单模型。
分析原因:LR算法是在线性函数的基础上引入非线性函数,由原来的一条直线变成曲线,增强非线性表达能力。事实上,LR还是一种简单的模型,模型是使用离散特征还是连续特征,本质是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。所以使用LR模型的关键在于搭配海量特征。第二点是LR模型加入连续值特征性能变差,我觉得是模型预测的准确度提高了,但是因为特征数量太少,所以整体预测还是不准的。所以问题的关键在于增加LR模型的特征。
3. LGB+LR: 分析LR模型不适合处理连续值, 所以我们用LGB离散化连续值, 将LGB的叶子节点位置输入到LR中, 效果有一定的提升.
分析原因:本质和连续特征转成离散特征的原因一致。另外,我曾在面试时被问到连续型特征转成离散特征会带来一定的损失,怎么办?我觉得主要的解决方法有两点:1). 从多种角度转化连续型特征,将损失的数值用特征表示出来。2). 权衡离散转化的力度。例如分箱转换,是否可以增加箱子的数量,将连续性特征转成细粒度的特征?
4. LGB+FM: 因为LGB+LR的方法效果不错, 所以想是否可以用LGB搭配更强的模型。 但是事实上, LGB+FM的效果很差, 比单独的LGB, LR和FM效果都差。
分析原因:FM是强模型,可以单独用作推荐系统的召回和精排,主要原理是特征的隐向量, 但是大量的稀疏值使V向量学习不到位, 所以效果很差。我猜这也是经常看到树+LR, 但是看不到树+FM的原因吧。通常来说,FM适合连续特征, 原始特征和特征的embedding输入都可以取得很好的效果.
5. FM: 这是我们使用的第二好的模型, 和LGB使用一样的数据, FM模型就是可以直接提高0.2个点, 损失减低10+左右. 但是缺点是没有现成的特征权重输出, 不能作为特征选择器.
此外,我们还尝试DeepCTR中的其他模型,虽然没有取得良好的成绩,但是可以学习一下推荐中常用的模型架构,了解工业界的发展。
6. Wide&Deep:效果一般。
7. DeepFM:效果稍微好一点。
8. DIN: [阿里的深度兴趣网络模型](https://www.jianshu.com/p/73b6f5d00f46?utm_campaign=maleskine&utm_content=note&utm_medium=reader_share&utm_source=weibo),是由阿里妈妈的精准定向检索和基础算法团队推出的算法,模型重点挖掘用户的兴趣和部分的历史记录信息。通俗地说就是用户平常喜欢看哪些东西,比如可以有历史人物传记、小说、电影周边等,但是当用户想买洗发露的时候,和这些兴趣就几乎没有关系了,只和历史记录中的洗护用品有关系,这些洗护用品就是重点研究对象,也就是兴趣。用户行为的兴趣是对所有广告的加权和,权重仿照Attention是每个行为和广告直接的相似度。另外,模型的评价指标是GAUC,激活函数是Dice,引入自适应正则。模型提升了1.24%。
9. DIEN: [阿里的深度兴趣进化网络](https://zhuanlan.zhihu.com/p/50758485)DIEN主要在DIN基础上描述用户的长期兴趣和短期兴趣以及兴趣转移变化过程。模型将用户行为传承序列形式,将简单的激活函数变成带Attention的GRU函数。
10. NFFM: 这是前几年的冠军模型, 被[渣大开源出来了](https://zhuanlan.zhihu.com/p/38443751), 效果很强大, 原理很复杂, 使用也很复杂, 我们勉强使用上, 但是效果一般。主要区别是将原来的Wide&Deep的Deep的输入换成FM的交叉后的特征,之后接全连接层。
11. AFM: Attention Factorization Machine, 也是阿里的前几年的模型, 使用效果也一般.
观察自身经验和其他队伍发现, NN模型效果确实没有想象中的那么好. 我觉得根本原因是深度模型使用细节存在很多坑,刚入门的小伙伴需要花很多时间调整模型。所以建议刚开始做比赛的小伙伴选用XGB或者LGB,有基础后在使用深度模型。
4. 不足之处
主要分为两点:数据和模型
- 在数据方面:
- 没有将新旧广告分开
- 构造数据时没有考虑时间窗口, 这也是我们比top10最大的差别, 他们几乎都把前10天, 前7天, 前3天, 昨天的历史数据作为特征,并且都取得了很好的成绩
- ID特征使用方式出错,没有将ID和非ID特征分开建立树模型,没有将ID处理直接输入深度模型
- 前两名队伍使用大量序列特征+DeepWalk/Transformer模型
- 我们主要花费了大量精力创造新特征, 但是新特征的效果都很差, 投入和产出严重不成比例
- 在模型方面:
- 没有提出和改进现有的模型, 我们几乎是把现有的可用模型都用了一下,但是看所有的冠军视频发现, 他们都改造模型的损失函数和架构
- 使用的深度模型效果都不好, 为什么不好, 我们没有仔细研究
值得学习的帖子
比赛结束后官方放出了前十名的答辩链接,冠军的方案被评价为最接近线上的解决方案,推荐小伙伴看一看。
比赛记录的文件:
特征工程文档1
特征工程文档2
比赛方对题的说明
比赛中收藏的帖子:
deepctr库, 包含很多CTR模型
鱼佬知乎
比赛经历贴,重点看下面的TOP方案
2018年腾讯广告大赛总结
提问帖中的特征部分

