使用Prometheus监控nomad指标
使用Prometheus监控nomad指标
本教程介绍如何配置普罗米修斯与Nomad群集和普罗米修斯Alertmanager集成。虽然本教程介绍了启用遥测和警报的基础知识,但Nomad操作员可以通过定制仪表盘和集成不同的警报接收器来进行更深入的研究。
想象一个场景,其中一个Nomad操作员需要部署Prometheus来从Nomad集群收集度量。操作员必须在Nomad服务器和客户机上启用遥测,并将普罗米修斯配置为使用Consul进行服务发现。操作员还必须配置Prometheus Alertmanager,以便将通知发送到指定的接收器。
本教程将部署Prometheus,其配置将考虑高度动态的环境。将服务发现集成到配置文件中,以避免使用硬编码的IP地址。将Prometheus部署置于fabio之后,这将允许Nomad操作员点击/path上的任何客户端节点,从而访问Prometheus web界面。
先决条件
要执行本指南中描述的任务,您需要安装一个安装了 Consul 的 Nomad 环境。您可以使用它存储 库以预配沙盒环境。本教程将假定群集具有一个服务器节点和三个客户机节点。
注意:本教程仅用于演示目的,仅使用单个服务器节点。在生产群集中,建议使用 3 或 5 个服务器节点。本教程中定义的警报规则仅用于说明目的。指警报规则了解更多信息。
在 Nomad 服务器和客户端上启用遥测
在Nomad客户端和服务器配置文件中添加下面的小节。如果您使用了本教程中提供的存储库来设置Nomad集群,那么配置文件将是/etc/nomad.d/nomad.hcl。进行此更改后,在每个服务器和客户端节点上重新启动Nomad服务。
sudo su
cat <<EOF >> /etc/nomad.d/nomad.hcl
telemetry {
collection_interval = "1s"
disable_hostname = true
prometheus_metrics = true
publish_allocation_metrics = true
publish_node_metrics = true
}
EOF
systemctl restart nomad
创建并运行 Fabio 作业
为 Fabio 创建作业规范
为 Fabio 创建一个按以下规范命名的作业:fabio.nomad
job "fabio" {
datacenters = ["dc1"]
type = "system"
group "fabio" {
task "fabio" {
driver = "docker"
config {
image = "fabiolb/fabio"
network_mode = "host"
}
resources {
cpu = 100
memory = 64
network {
port "lb" {
static = 9999
}
port "ui" {
static = 9998
}
}
}
}
}
}
要了解有关Fabio及其作业文件中使用的选项的更多信息,请参阅Fabio的负载平衡。就本指南而言,重要的是要注意type选项设置为system,以便将Fabio部署在所有客户端节点上。作业规范还将network_mode定义为主机,以便Fabio能够使用Consul进行服务发现。
运行 Fabio 作业
您现在可以注册 Fabio 职位:
nomad job run fabio.nomad
此时,您应该能够访问端口9998上的任何一个客户端节点,并为Fabio打开web界面。路由表将为空,因为您尚未部署Fabio可以路由到的任何内容。因此,如果您此时访问端口9999上的任何客户端节点,您将获得404 HTTP响应。这将很快改变。
创建并运行Prometheus作业
为Prometheus创建作业规范
为Prometheus创建一个作业并为其命名prometheus.nomad
job "prometheus" {
datacenters = ["dc1"]
type = "service"
group "monitoring" {
count = 1
network {
port "prometheus_ui" {
static = 9090
}
}
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
ephemeral_disk {
size = 300
}
task "prometheus" {
template {
change_mode = "noop"
destination = "local/prometheus.yml"
data = <<EOH
---
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'nomad_metrics'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['nomad-client', 'nomad']
relabel_configs:
- source_labels: ['__meta_consul_tags']
regex: '(.*)http(.*)'
action: keep
scrape_interval: 5s
metrics_path: /v1/metrics
params:
format: ['prometheus']
EOH
}
driver = "docker"
config {
image = "prom/prometheus:latest"
volumes = [
"local/prometheus.yml:/etc/prometheus/prometheus.yml",
]
ports = ["prometheus_ui"]
}
service {
name = "prometheus"
tags = ["urlprefix-/"]
port = "prometheus_ui"
check {
name = "prometheus_ui port alive"
type = "http"
path = "/-/healthy"
interval = "10s"
timeout = "2s"
}
}
}
}
}
请注意,使用template小结使用环境变量创建Prometheus配置。在这种情况下,作业在consul_sd_connection部分使用环境变量NOMAD_IP_prometheus_ui,以确保prometheus可以使用consul检测和刮擦目标。此示例适用于此示例,因为Consul与Nomad一起安装。此外,通过避免硬代码IP地址,从这种配置中受益。如果您没有使用本教程中提供的repo创建Nomad集群,请务必将Prometheus配置指向您设置的Consul服务器。
卷选项允许您获取template小结动态创建的配置文件并将其放置在Prometheus容器中。
运行Prometheus作业
您现在可以注册Prometheus的职位:
nomad job run prometheus.nomad
普罗米修斯现在被部署。您可以访问端口9999上的任何客户端节点来访问web界面。Nomad集群中只有一个Prometheus实例运行,但无论您访问哪个节点,您都会自动路由到它,因为Fabio也在集群上部署和运行。
在顶部菜单栏上,单击状态,然后单击目标。目标列表应该包括所有Nomad节点。请注意,集群中的IP地址将不同。
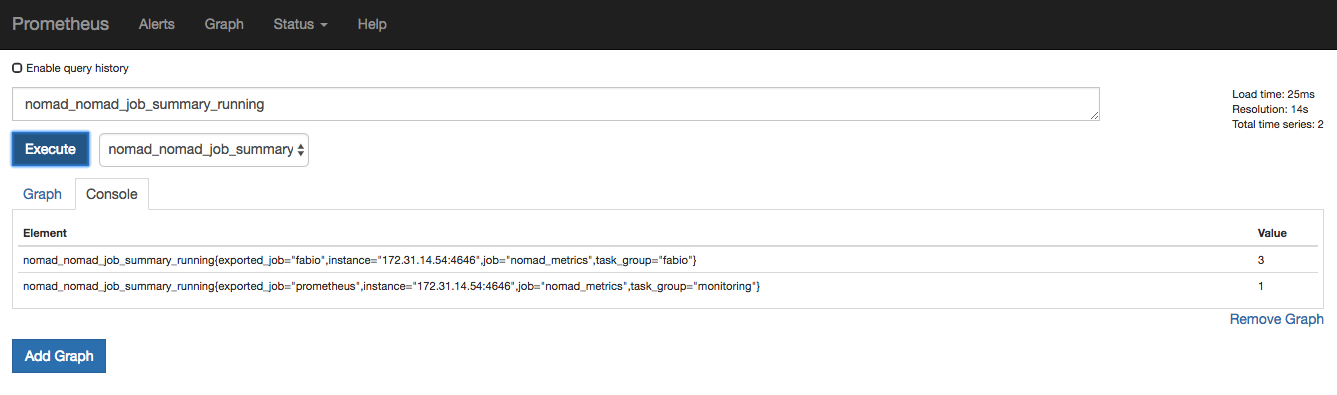
Prometheus目标
使用 Prometheus 查询我们的 Nomad 集群中正在运行的作业数。在主页上,输入查询nomad_nomad_job_summary_running。还可以从下拉列表中选择查询。
或者 nomad_client_allocated_cpu
正在运行的作业
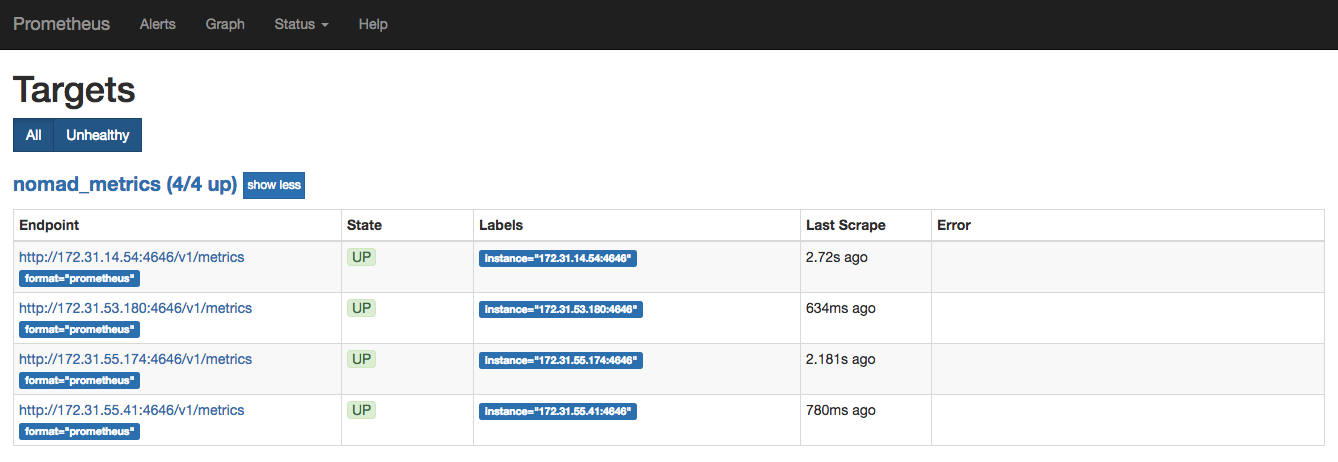
我们Fabio工作的价值在于,它正在使用3系统调度程序类型。这是有道理的,因为在我们的演示集群中有三个正在运行的Nomad客户端。另一方面,我们的 Prometheus 工作的价值在于,您只部署了它的一个实例。要了解有关其他指标的更多信息,请访问1遥测部分。
部署警报管理器
现在,您已启用 Prometheus 从我们的集群收集指标并验证我们作业的状态,请部署警报管理器.请记住,Prometheus 会向 Alertmanager 发送警报。然后,Alertmanager的工作是将这些警报的通知发送给任何指定的接收器.
为 Alertmanager 创建一个作业并将其命名alertmanager.nomad
job "alertmanager" {
datacenters = ["dc1"]
type = "service"
group "alerting" {
count = 1
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
network {
port "alertmanager_ui" {
static = 9093
}
}
ephemeral_disk {
size = 300
}
task "alertmanager" {
driver = "docker"
config {
image = "prom/alertmanager:latest"
ports = ["alertmanager_ui"]
}
# resources {
# network {
# port "alertmanager_ui" {
# static = 9093
# }
# }
# }
service {
name = "alertmanager"
tags = ["urlprefix-/alertmanager strip=/alertmanager"]
port = "alertmanager_ui"
check {
name = "alertmanager_ui port alive"
type = "http"
path = "/-/healthy"
interval = "10s"
timeout = "2s"
}
}
}
}
}
配置 Prometheus 以与 Alertmanager 集成
现在,您已经部署了 Alertmanager,请稍微修改 Prometheus 作业配置,以允许它识别并向其发送警报。请注意,配置中有一些规则引用了您即将部署的 Web 服务器。
下面是上面详述的与 Prometheus 配置相同的配置,但添加了一些将 Prometheus 连接到 Alertmanager 并设置一些警报规则的部分。
job "prometheus" {
datacenters = ["dc1"]
type = "service"
group "monitoring" {
count = 1
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
ephemeral_disk {
size = 300
}
network {
port "prometheus_ui" {
static = 9090
}
}
task "prometheus" {
template {
change_mode = "noop"
destination = "local/webserver_alert.yml"
data = <<EOH
---
groups:
- name: prometheus_alerts
rules:
- alert: Webserver down
expr: absent(up{job="webserver"})
for: 10s
labels:
severity: critical
annotations:
description: "Our webserver is down."
EOH
}
template {
change_mode = "noop"
destination = "local/prometheus.yml"
data = <<EOH
---
global:
scrape_interval: 5s
evaluation_interval: 5s
alerting:
alertmanagers:
- consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['alertmanager']
rule_files:
- "webserver_alert.yml"
scrape_configs:
- job_name: 'alertmanager'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['alertmanager']
- job_name: 'nomad_metrics'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['nomad-client', 'nomad']
relabel_configs:
- source_labels: ['__meta_consul_tags']
regex: '(.*)http(.*)'
action: keep
scrape_interval: 5s
metrics_path: /v1/metrics
params:
format: ['prometheus']
- job_name: 'webserver'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['webserver']
metrics_path: /metrics
EOH
}
driver = "docker"
config {
image = "prom/prometheus:latest"
volumes = [
"local/webserver_alert.yml:/etc/prometheus/webserver_alert.yml",
"local/prometheus.yml:/etc/prometheus/prometheus.yml"
]
ports = ["prometheus_ui"]
}
service {
name = "prometheus"
tags = ["urlprefix-/"]
port = "prometheus_ui"
check {
name = "prometheus_ui port alive"
type = "http"
path = "/-/healthy"
interval = "10s"
timeout = "2s"
}
}
}
}
}
请注意,此作业文件的以下几个重要部分:
- 另一个
template节定义了web服务器的警报规则。也就是说,如果普罗米修斯检测到Web服务器服务消失,它将发出警报。 - 普罗米修斯配置的警报块以及规则文件块,使普罗米修斯了解Alertmanager及其定义的规则。
- 现在,这项工作还将Alertmanager与我们的web服务器结合起来。
部署 Web 服务器工作负载
为我们的 Web 服务器创建一个作业并将其命名webserver.nomad
job "webserver" {
datacenters = ["dc1"]
group "webserver" {
task "server" {
driver = "docker"
config {
image = "hashicorp/demo-prometheus-instrumentation:latest"
}
resources {
cpu = 500
memory = 256
network {
port "http"{}
}
}
service {
name = "webserver"
port = "http"
tags = [
"testweb",
"urlprefix-/webserver strip=/webserver",
]
check {
type = "http"
path = "/"
interval = "2s"
timeout = "2s"
}
}
}
}
}
679456792
此时,重新运行您的Prometheus作业。几秒钟后,Web 服务器和警报管理器将显示在您的目标列表中。
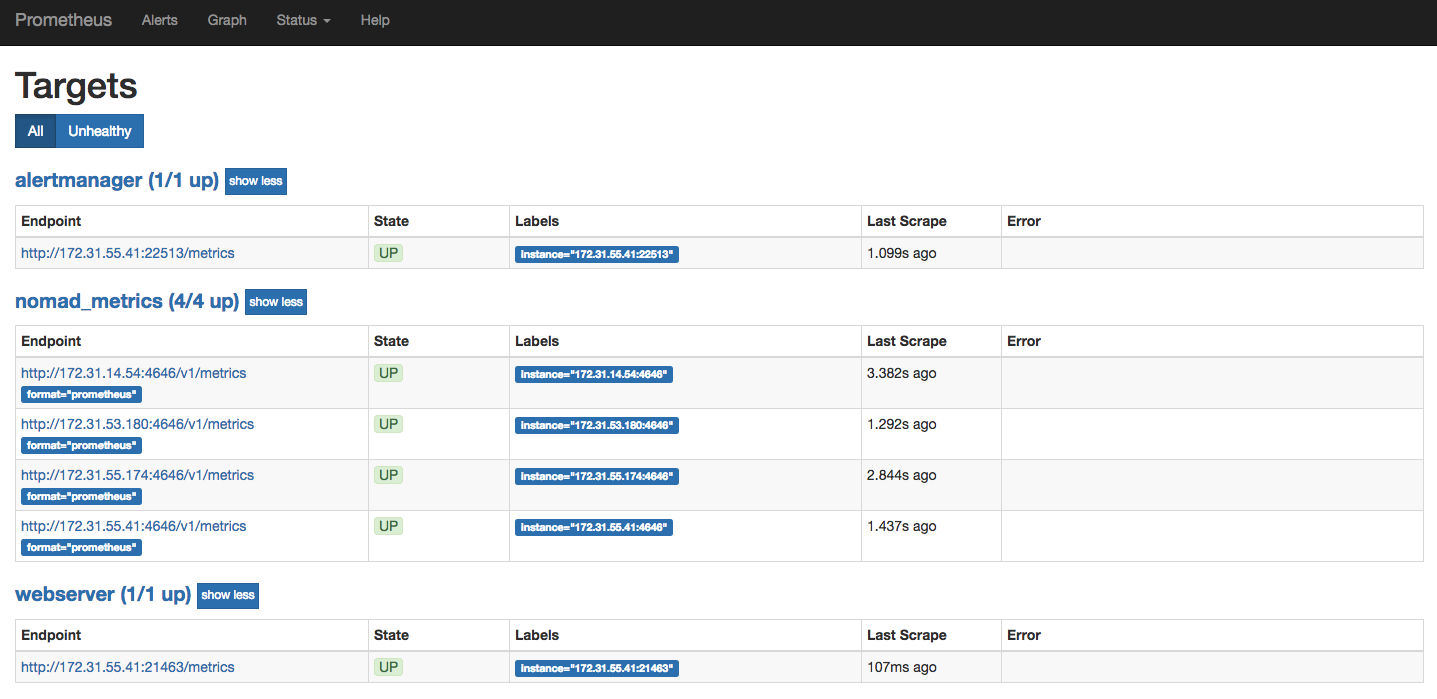
您还应该能够转到Prometheus Web界面的部分,并观察您配置的警报。没有警报处于活动状态,因为 Web 服务器已启动并正在运行。Alerts
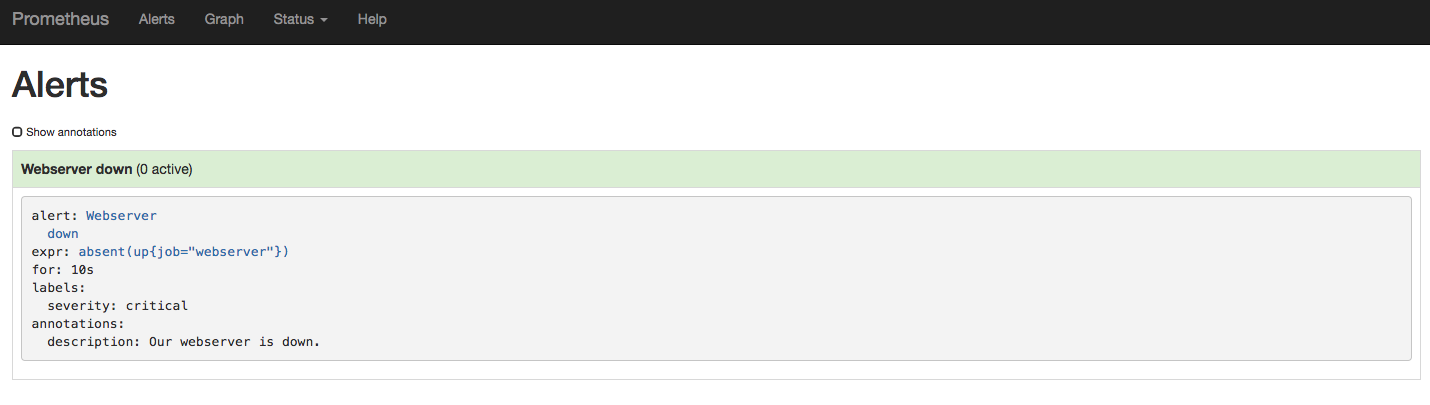
停止 Web 服务器任务
运行以停止 Web 服务器。几秒钟后,Web 界面的部分将显示活动警报。nomad stop webserverAlerts
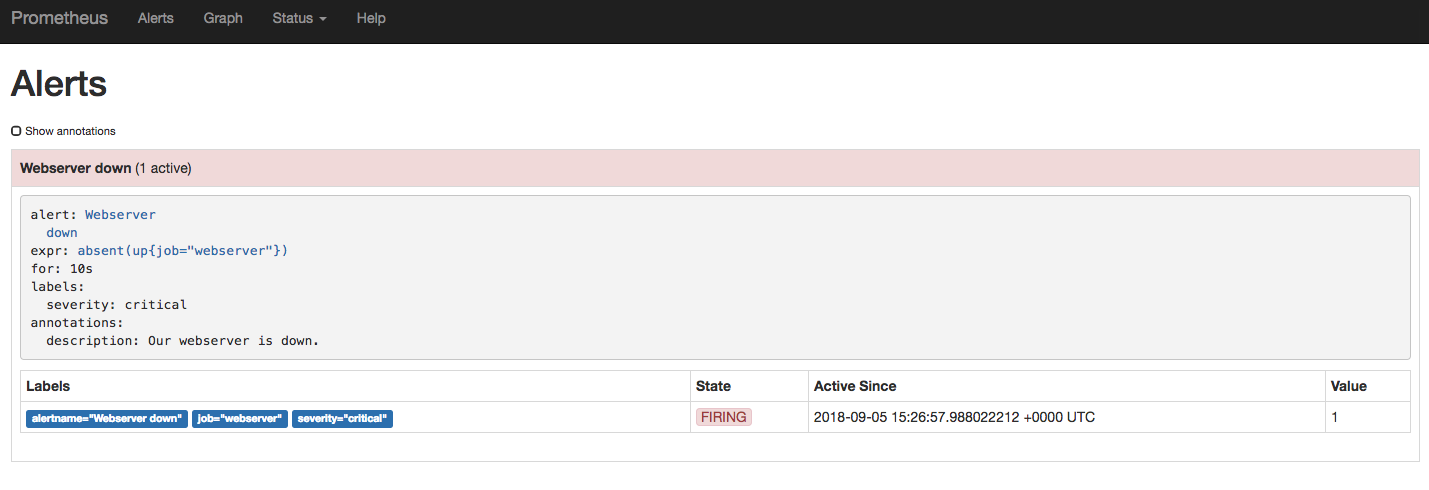
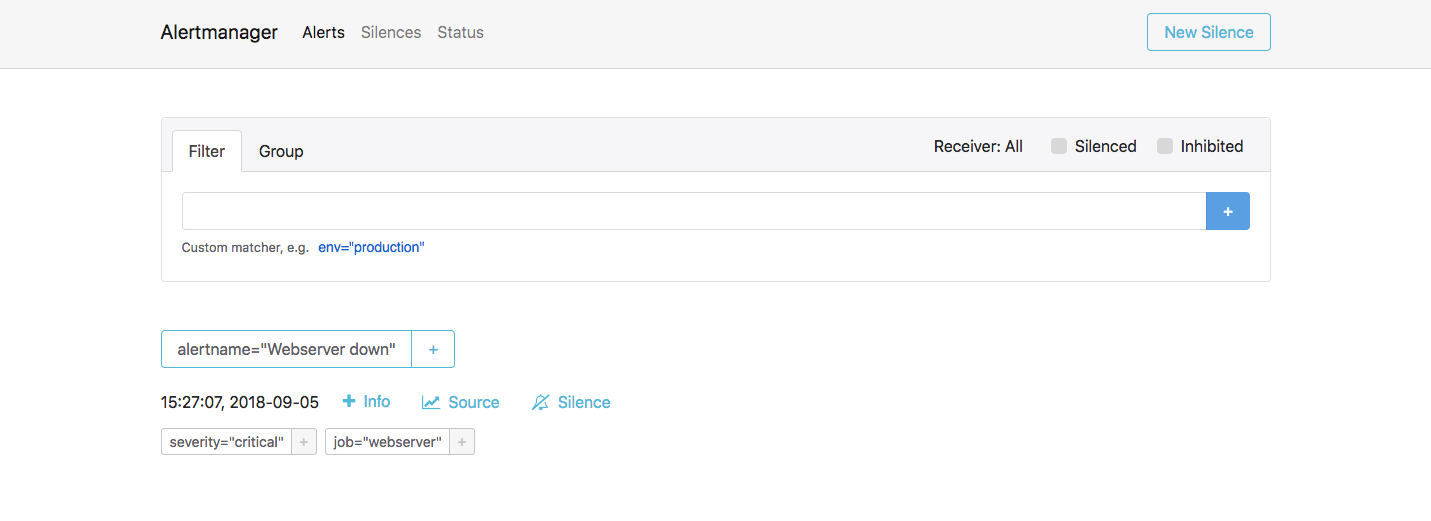
现在,您可以转到 Alertmanager Web 界面,以验证 Alertmanager 是否也收到了此警报。由于 Alertmanager 已在 Fabio 后面配置,因此请转到端口上任何客户端节点的 IP 地址并用作路由。示例如下所示:9999/alertmanager
<客户机节点 IP >:9999/alertmanager
验证警报管理器是否已收到警报。
后续步骤
阅读更多 关于 Prometheus警报管理器以及如何将其配置为向接收器您的选择。 https://prometheus.io/docs/alerting/alertmanager/
- 参考资料
配置Prometheus https://prometheus.io/docs/introduction/first_steps/#configuring-prometheus
Nomad 代理配置中的遥测节 https://www.nomadproject.io/docs/configuration/telemetry.html
警报概述 https://prometheus.io/docs/alerting/overview/
https://grafana.com/grafana/dashboards/?search=nomad
nomad 6278 3800 6281
15764 12787
nomad-cluster1 https://www.metricfire.com/blog/monitoring-hashicorp-nomad-with-prometheus-and-grafana/
grafana job https://gist.github.com/picatz/1f315e012c6ab79565524032e1c64bc7
全套 https://faun.pub/monitoring-solution-in-nomad-ee0fbd548c23
node-exporter.hcl https://github.com/visibilityspots/nomad-consul-prometheus/tree/master/nomad
拓展 个别指标没出来 查看日志
journalctl -u nomad -f
Cloudflare:如何使用HashiCorp Nomad https://www.kchuhai.com/pingtai/Cloudflare/view-26695.html
配置 https://www.nomadproject.io/docs/configuration/telemetry
监控宿主机
设置docker 可挂载的权限
cat /etc/nomad.d/client.hcl
plugin "docker" {
config {
volumes {
enabled = true
selinuxlabel = "z"
}
allow_privileged = true
}
}
job "node-exporter" {
datacenters = ["dc1"]
type = "system"
group "app" {
count = 1
restart {
attempts = 3
delay = "20s"
mode = "delay"
}
task "node-exporter" {
driver = "docker"
config {
image = "prom/node-exporter:v0.17.0"
force_pull = true
volumes = [
"/proc:/host/proc",
"/sys:/host/sys",
"/:/rootfs"
]
port_map {
http = 9100
}
logging {
type = "journald"
config {
tag = "NODE-EXPORTER"
}
}
}
service {
name = "node-exporter"
# address_mode = "driver"
tags = [
"metrics"
]
port = "http"
check {
type = "http"
path = "/metrics/"
interval = "10s"
timeout = "2s"
}
}
resources {
cpu = 50
memory = 100
network {
port "http" { static = "9100" }
}
}
}
}
}
p8s 根据 service的名字进行服务发现,p8sd 配置文件添加以下内容
- job_name: 'node'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['node-exporter']
metrics_path: /metrics
模板使用 8919
监控容器
job "cadvisors" {
region = "global"
datacenters = ["dc1"]
type = "system"
group "app" {
count = 1
restart {
attempts = 3
delay = "20s"
mode = "delay"
}
task "cadvisor" {
driver = "docker"
config {
image = "google/cadvisor:v0.33.0"
force_pull = true
volumes = [
"/:/rootfs",
"/var/run:/var/run",
"/sys:/sys",
"/var/lib/docker/:/var/lib/docker",
"/cgroup:/cgroup"
]
port_map {
http = 8080
}
logging {
type = "journald"
config {
tag = "CADVISOR"
}
}
}
service {
name = "cadvisor"
tags = [
"metrics"
]
port = "http"
check {
type = "http"
path = "/metrics/"
interval = "10s"
timeout = "2s"
}
}
resources {
cpu = 250
memory = 500
network {
port "http" { static = "8080" }
}
}
}
}
}
p8s 根据 service的名字进行服务发现,p8sd 配置文件添加以下内容
- job_name: 'node'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['cadvisor']
metrics_path: /metrics
最终
# nvc default prometheus 500GB
job "prometheus" {
datacenters = ["dc1"]
type = "service"
group "monitoring" {
count = 1
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
ephemeral_disk {
size = 3000
}
network {
port "prometheus_ui" {
static = 9090
}
}
volume "ceph-volume" {
type = "csi"
read_only = false
source = "prometheus"
access_mode = "single-node-writer"
attachment_mode = "file-system"
}
task "prometheus" {
volume_mount {
volume = "ceph-volume"
destination = "/prometheus"
read_only = false
}
template {
change_mode = "noop"
destination = "local/webserver_alert.yml"
data = <<EOH
---
groups:
- name: prometheus_alerts
rules:
- alert: Webserver down
expr: absent(up{job="webserver"})
for: 10s
labels:
severity: critical
annotations:
description: "Our webserver is down."
EOH
}
template {
change_mode = "noop"
destination = "local/prometheus.yml"
data = <<EOH
---
global:
scrape_interval: 5s
evaluation_interval: 5s
alerting:
alertmanagers:
- consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['alertmanager']
rule_files:
- "webserver_alert.yml"
scrape_configs:
- job_name: 'node'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['node-exporter']
metrics_path: /metrics
- job_name: 'alertmanager'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['alertmanager']
- job_name: 'nomad_metrics'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['nomad-client', 'nomad']
relabel_configs:
- source_labels: ['__meta_consul_tags']
regex: '(.*)http(.*)'
action: keep
scrape_interval: 5s
metrics_path: /v1/metrics
params:
format: ['prometheus']
- job_name: 'ceph'
static_configs:
- targets: ['10.103.3.134:9283']
- job_name: 'cadvisor'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['cadvisor']
metrics_path: /metrics
- job_name: 'webserver'
consul_sd_configs:
- server: '{{ env "NOMAD_IP_prometheus_ui" }}:8500'
services: ['webserver']
metrics_path: /metrics
EOH
}
driver = "docker"
config {
image = "prom/prometheus:latest"
network_mode = "host"
volumes = [
"local/webserver_alert.yml:/etc/prometheus/webserver_alert.yml",
"local/prometheus.yml:/etc/prometheus/prometheus.yml"
]
ports = ["prometheus_ui"]
}
resources {
cpu = 2000
memory = 4096
}
service {
name = "prometheus"
tags = ["urlprefix-/"]
port = "prometheus_ui"
check {
name = "prometheus_ui port alive"
type = "http"
path = "/-/healthy"
interval = "10s"
timeout = "2s"
}
}
}
}
}
模板 193 893 11277 10619
参考 https://blog.51cto.com/jiachuanlin/2538983
sum(nomad_client_host_memory_used) by (instance)
磁盘:
总磁盘:sum(nomad_client_host_disk_size{disk="/dev/dm-0"}) 单位:byte
使用:sum(nomad_client_host_disk_used{disk="/dev/dm-0"}) 单位:字节
CPU:
总 sum(nomad_client_allocated_cpu + nomad_client_unallocated_cpu) /3200 单位:核数
使用率:sum(nomad_client_host_cpu_user) / 100 单位:核数
内存:
总内存:sum(nomad_client_host_memory_total) 单位:字节
使用:sum(nomad_client_host_memory_used) 单位:字节
job 总使用 | nomad_client_allocs_memory_usage{exported_job="gtm-es"} nomad_client_allocs_cpu_user{exported_job="gtm-es"}
job 总请求 | nomad_client_allocs_memory_allocated{exported_job="gtm-es"} nomad_client_allocs_cpu_allocated{exported_job="gtm-es"}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号