神经网络的正向和反向传播
本文目的:
以自己的理解,大致介绍神经网络,并梳理神经网络的正向和反向传播公式。
神经网络简介
神经网络是机器学习的分支之一,因为大量数据的出现和可供使用以及神经网络因深度和广度的增加对于大量数据的可扩展性,目前神经网络逐渐变成了除常规机器学习方法外的另一个主流。人们所认识的神经网络一般为Fig. 1所示:
 Fig. 1 基本神经网络结构图
Fig. 1 基本神经网络结构图
 卷积神经网络结构图
卷积神经网络结构图
 循环神经网络结构图
循环神经网络结构图
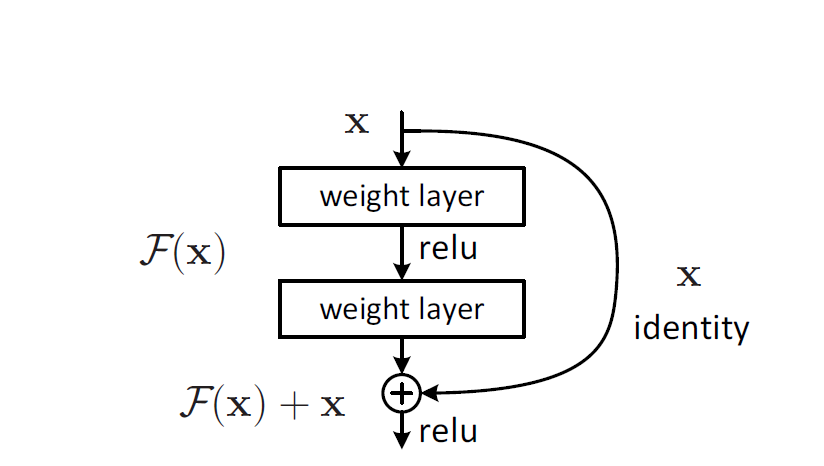 残差网络结构图
残差网络结构图
前向传播和反向传播
说起典型的神经网络的分析,那么就不得不提到前向传播和反向传播。前向传播使得输入可以通过神经网络得到输出,输出和真实值可以反向矫正神经网络的参数,使得得到一个适合具体问题的神经网络。
前向传播
 Fig. 2 典型神经网络
Fig. 2 典型神经网络
 Fig. 3 多层神经网络
Fig. 3 多层神经网络
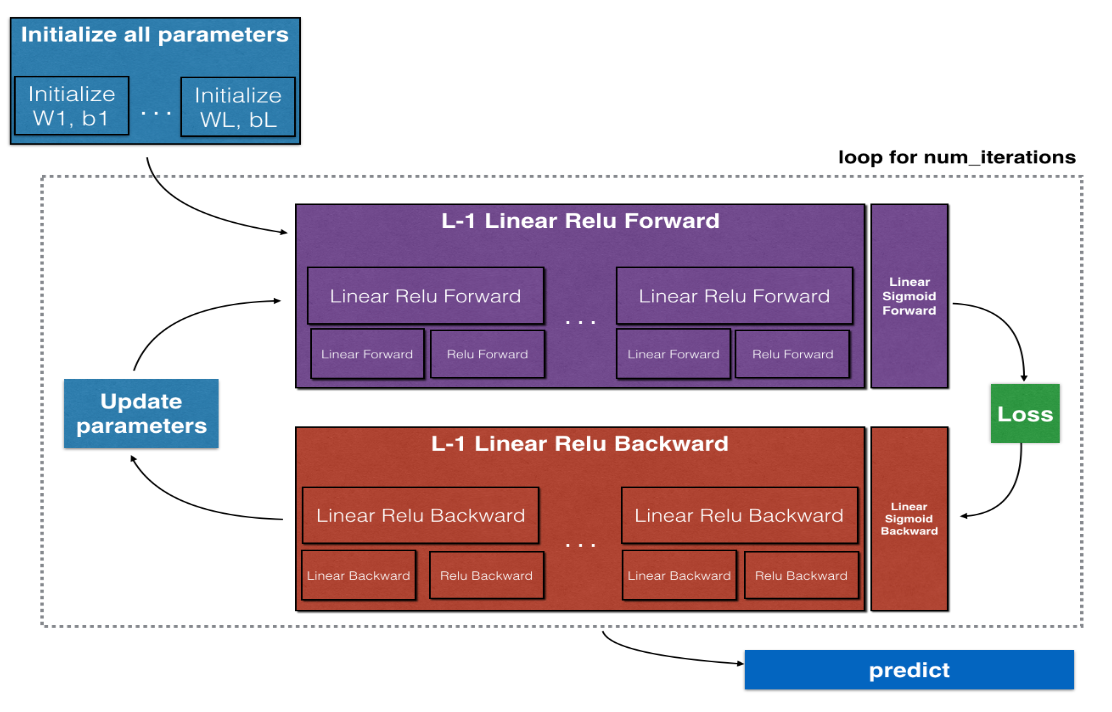 Fig. 4 正向反向传播示意图
Fig. 4 正向反向传播示意图
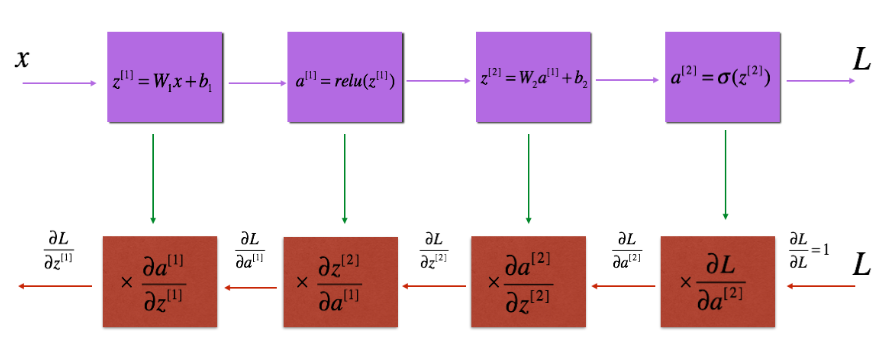 Fig. 5 反向传播
Fig. 5 反向传播
矢量化详解
从输入\(X\)开始,我们的每个输入\(X\)都有很多特征\(X = [x_1\,x_2\,x_3\,...\,x_n]^T\)而我们也会有很多的输入,我们组成新的输入\(X = [X^{(1)}\,X^{(2)}\,...\,X^{(m)}]\),因此\(X\)包含了所有的数据,每一列是一个数据,每个数据包含n个特征,一共有m个数据。因此\(Z = [z^{(1)}\,z^{(2)}\,...\,z^{(m)}]\),\(A = [a^{(1)}\,a^{(2)}\,...\,a^{(m)}]\)由此我们完成了矢量化。尽管使用了矢量化,正向传播的公式也没有变,\(b^{[l]}\)也可以通过python的广播来完成:
\begin{equation}
\vec{A}^{[l]} = W{[l]T}\vec{A} + b^{[l]}
\end{equation}
\begin{equation}
\vec{A}^{[l]} = g(\vec{Z}^{[l]})
\end{equation}
但是,因为参数\(W\in R^{l \times l-1}\)和\(b \in R^l\)的维度没有变化,当使用反向传播计算\(\frac{\partial L}{\partial W^{[l]}}\)和\(\frac{\partial L}{\partial b^{[l]}}\)的时候,我们需要乘\(\frac{1}{m}\):
\(\frac{\partial L}{\partial Z^{[l]}}A^{[l-1]T} = [dz^{[l](1)}\,...\,dz^{[l](m)}][a^{[l-1](1)}\,...\,a^{[l-1](m)}]^T\)
\(\frac{\partial L}{\partial Z^{[l]}}A^{[l-1]T} = dz^{[l](1)}a^{[l-1](1)} + ... +dz^{[l](m)}a^{[l-1](m)} = m\frac{\partial L}{\partial W^{[l]}}\)
同理,
\(\frac{\partial L}{\partial Z^{[l]}} = [dz^{[l](1)}\,...\,dz^{[l](m)}]\)
\(\frac{\partial L}{\partial b^{[l]}} = \frac{1}{m} \sum_{i = 1}^{m} dZ^{[l](i)}\)
反向传播公式
目前我们得到了:\(\frac{\partial L}{\partial b^{[l]}}\) = \(\frac{1}{m} \sum_{i = 1}^{m} dZ^{[l](i)}\),\(\frac{\partial L}{\partial W^{[l]}}\) = \(\frac{1}{m}\frac{\partial L}{\partial Z^{[l]}}A^{[l-1]T}\)(为什么\(A^{[l-1]}是要转置的呢?\)),但是为了计算\(\frac{\partial L}{\partial W^{[l]}}\)和\(\frac{\partial L}{\partial b^{[l]}}\),我们还需要求得\(\frac{\partial L}{\partial Z^{[l]}}\)。
正向传播公式:\(A^{[l]} = g(Z^{[l]})\),\(\vec{Z}^{[l]} = W^{[l]T}\vec{A}^{[l-1]} + b^{[l]}\)
\begin{equation}
dA^{[L]} = \frac{\partial loss}{\partial A^{[L]}}
\end{equation}
\begin{equation}
dZ^{[l]} = dA{[l]}\dot{g(Z)}
\end{equation}
\begin{equation}
dA^{[l-1]} = W{[l]T}dZ
\end{equation}
\begin{equation}
\frac{\partial L}{\partial W^{[l]}} = \frac{1}{m}\frac{\partial L}{\partial Z{[l]}}A
\end{equation}
\begin{equation}
\frac{\partial L}{\partial b^{[l]}} = \frac{1}{m} \sum_{i = 1}^{m} dZ^{[l] (i)}
\end{equation}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号