
Selenium学习:get_attribute()方法获取列表元素信息
text()方法可以获取单个元素的链接文本
如果想要列表里的全部元素的链接文本,可以使用get_attribute()方法
使用方法:
list = dr.find_elements_by_xpath("//*[@id='user-table']//tbody/tr[1]//ul/li/a") for i in list: print(i.get_attribute("textContent").strip())
get_attribute()还有get_attribute("innerHTML") 和get_attribute("outerHTML")方法
实践得出,get_attribute("textContent")和get_attribute("innerHTML")可获得链接文本
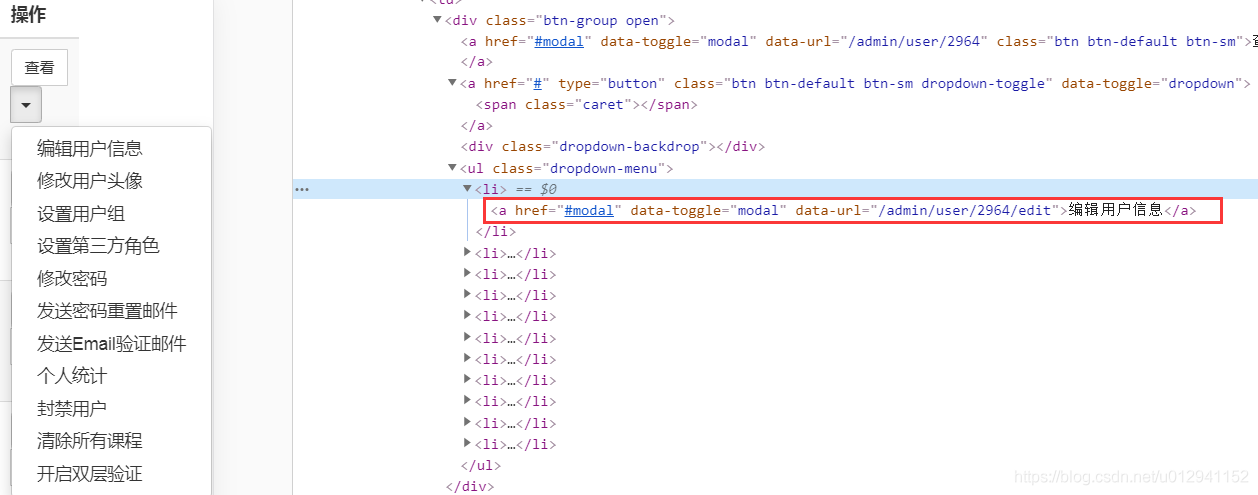
get_attribute("outerHTML")可获得a链接全部信息,如下图标出的 <a href="#modal" data-toggle="modal" data-url="/admin/user/2964/avatar">修改用户头像</a>
另外,对 a 标签中的每个属性进行 get_attribute 操作获取,如
element.get_attribute("class")
element.get_attribute("href")
elemnet.get_attribute("date-url")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号