
DirectX11 With Windows SDK--03 索引缓冲区、常量缓冲区
前言
一个立方体有8个顶点,然而绘制一个立方体需要画12个三角形,如果按照前面的方法绘制的话,则需要提供36个顶点,而且这里面的顶点数据会重复4次甚至5次。这样的绘制方法会占用大量的内存空间。
接下来会讲另外一种绘制方法,可以只提供立方体的8个顶点数据,然后用一个索引数组来指代使用哪些顶点,按怎样的顺序绘制。
在阅读本章之前,先要了解下面的内容:
| 章节 |
|---|
| 02 顶点/像素着色器的创建、顶点缓冲区 |
| HLSL中矩阵的内存布局和mul函数探讨 |
当然,我也建议你及早开始了解并上手图形调试器,以帮助寻找在CPU调试时无法察觉到的问题:
| 章节 |
|---|
| Visual Studio图形调试器详细使用教程 |
学习目标:
- 掌握索引缓冲区的创建、使用
- 掌握常量缓冲区的创建、更新、使用
- 根据索引绘制出第一个立方体
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
索引缓冲区(Index Buffer)
使用索引缓冲区进行替代指定顺序绘制,可以有效减少顶点缓冲区的占用空间,避免提供大量重复的顶点数据。
在使用索引缓冲区前,先讲初始化顶点数组,如下:
// ******************
// 设置立方体顶点
// 5________ 6
// /| /|
// /_|_____/ |
// 1|4|_ _ 2|_|7
// | / | /
// |/______|/
// 0 3
VertexPosColor vertices[] =
{
{ XMFLOAT3(-1.0f, -1.0f, -1.0f), XMFLOAT4(0.0f, 0.0f, 0.0f, 1.0f) },
{ XMFLOAT3(-1.0f, 1.0f, -1.0f), XMFLOAT4(1.0f, 0.0f, 0.0f, 1.0f) },
{ XMFLOAT3(1.0f, 1.0f, -1.0f), XMFLOAT4(1.0f, 1.0f, 0.0f, 1.0f) },
{ XMFLOAT3(1.0f, -1.0f, -1.0f), XMFLOAT4(0.0f, 1.0f, 0.0f, 1.0f) },
{ XMFLOAT3(-1.0f, -1.0f, 1.0f), XMFLOAT4(0.0f, 0.0f, 1.0f, 1.0f) },
{ XMFLOAT3(-1.0f, 1.0f, 1.0f), XMFLOAT4(1.0f, 0.0f, 1.0f, 1.0f) },
{ XMFLOAT3(1.0f, 1.0f, 1.0f), XMFLOAT4(1.0f, 1.0f, 1.0f, 1.0f) },
{ XMFLOAT3(1.0f, -1.0f, 1.0f), XMFLOAT4(0.0f, 1.0f, 1.0f, 1.0f) }
};
然后顶点缓冲区的创建和使用和之前一样:
// 设置顶点缓冲区描述
D3D11_BUFFER_DESC vbd;
ZeroMemory(&vbd, sizeof(vbd));
vbd.Usage = D3D11_USAGE_IMMUTABLE;
vbd.ByteWidth = sizeof vertices;
vbd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
vbd.CPUAccessFlags = 0;
// 新建顶点缓冲区
D3D11_SUBRESOURCE_DATA InitData;
ZeroMemory(&InitData, sizeof(InitData));
InitData.pSysMem = vertices;
HR(m_pd3dDevice->CreateBuffer(&vbd, &InitData, m_pVertexBuffer.GetAddressOf()));
// 输入装配阶段的顶点缓冲区设置
UINT stride = sizeof(VertexPosColor); // 跨越字节数
UINT offset = 0; // 起始偏移量
m_pd3dImmediateContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), &stride, &offset);
现在索引数组的初始化如下:
// 索引数组
DWORD indices[] = {
// 正面
0, 1, 2,
2, 3, 0,
// 左面
4, 5, 1,
1, 0, 4,
// 顶面
1, 5, 6,
6, 2, 1,
// 背面
7, 6, 5,
5, 4, 7,
// 右面
3, 2, 6,
6, 7, 3,
// 底面
4, 0, 3,
3, 7, 4
};
然后填充缓冲区描述信息并创建索引缓冲区:
// 设置索引缓冲区描述
D3D11_BUFFER_DESC ibd;
ZeroMemory(&ibd, sizeof(ibd));
ibd.Usage = D3D11_USAGE_IMMUTABLE;
ibd.ByteWidth = sizeof indices;
ibd.BindFlags = D3D11_BIND_INDEX_BUFFER;
ibd.CPUAccessFlags = 0;
// 新建索引缓冲区
InitData.pSysMem = indices;
HR(m_pd3dDevice->CreateBuffer(&ibd, &InitData, m_pIndexBuffer.GetAddressOf()));
ID3D11DeviceContext::IASetIndexBuffer方法--渲染管线输入装配阶段设置索引缓冲区
void ID3D11DeviceContext::IASetIndexBuffer(
ID3D11Buffer *pIndexBuffer, // [In]索引缓冲区
DXGI_FORMAT Format, // [In]数据格式
UINT Offset); // [In]字节偏移量
在装配的时候你需要指定每个索引所占的字节数:
| DXGI_FORMAT | 字节数 | 索引范围 |
|---|---|---|
| DXGI_FORMAT_R8_UINT | 1 | 0-255 |
| DXGI_FORMAT_R16_UINT | 2 | 0-65535 |
| DXGI_FORMAT_R32_UINT | 4 | 0-2147483647 |
于是我们可以这样:
// 输入装配阶段的索引缓冲区设置
m_pd3dImmediateContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0);
注意:当前更新将统一使用的索引类型为32位无符号整数。
常量缓冲区(Constant Buffer)
在HLSL中,常量缓冲区的变量类似于C++这边的全局常量,供着色器代码使用。下面是一个HLSL常量缓冲区示例:
cbuffer ConstantBuffer : register(b0)
{
matrix g_World;
matrix g_View;
matrix g_Proj;
}
cbuffer 用于声明一个常量缓冲区
matrix 等价于 float4x4,同样有vector等价于float4.其中D3D中的矩阵默认是行主矩阵形式,但是到了HLSL的matrix默认是列主矩阵形式。
register(b0) 指的是该常量缓冲区位于寄存器索引为0的缓冲区
而在C++应用层,常量缓冲区的对应结构体可以为:
struct ConstantBuffer
{
XMMATRIX world;
XMMATRIX view;
XMMATRIX proj;
};
目前常量缓冲区有两种运行时更新方式:
- 在创建资源的时候指定
Usage为D3D11_USAGE_DEFAULT,可以允许常量缓冲区从GPU写入,需要用ID3D11DeviceContext::UpdateSubresource方法更新。 - 在创建资源的时候指定
Usage为D3D11_USAGE_DYNAMIC、CPUAccessFlags为D3D11_CPU_ACCESS_WRITE,允许常量缓冲区从CPU写入,首先通过ID3D11DeviceContext::Map方法获取内存映射,然后再更新到映射好的内存区域,最后通过ID3D11DeviceContext::Unmap方法解除占用。
不仅常量缓冲区,一般的缓冲区和纹理资源更新都可以使用上述两种方式。前者适合更新不频繁(隔一段时间更新),或者仅一次更新的数据。而后者更适合于需要频繁更新,如每几帧更新一次,或每帧更新一次或多次的资源。
由于常量缓冲区大多数需要频繁更新,因此后续都将主要使用DYNAMIC更新。创建支持DYNAMIC更新的缓冲区过程如下:
D3D11_BUFFER_DESC cbd;
ZeroMemory(&cbd, sizeof(cbd));
cbd.Usage = D3D11_USAGE_DYNAMIC;
cbd.ByteWidth = sizeof(ConstantBuffer);
cbd.BindFlags = D3D11_BIND_CONSTANT_BUFFER;
cbd.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
// 新建常量缓冲区,不使用初始数据
HR(m_pd3dDevice->CreateBuffer(&cbd, nullptr, m_pConstantBuffer.GetAddressOf()));
注意:在创建常量缓冲区时,描述参数
ByteWidth必须为16的倍数,因为HLSL的常量缓冲区本身以及对它的读写操作需要严格按16字节对齐
现在来了解更新缓冲区的两种方法所需要用到的函数。
DYNAMIC更新
ID3D11DeviceContext::Map[1]函数--获取指向缓冲区中数据的指针并拒绝GPU对该缓冲区的访问
HRESULT ID3D11DeviceContext::Map(
ID3D11Resource *pResource, // [In]包含ID3D11Resource接口的资源对象
UINT Subresource, // [In]缓冲区资源填0
D3D11_MAP MapType, // [In]D3D11_MAP枚举值,指定读写相关操作
UINT MapFlags, // [In]填0,CPU需要等待GPU使用完毕当前缓冲区
D3D11_MAPPED_SUBRESOURCE *pMappedResource // [Out]获取到的已经映射到缓冲区的内存
);
D3D11_MAP枚举值类型的成员如下:
| D3D11_MAP成员 | 含义 |
|---|---|
| D3D11_MAP_READ | 映射到内存的资源用于读取。该资源在创建的时候必须绑定了 D3D11_CPU_ACCESS_READ标签 |
| D3D11_MAP_WRITE | 映射到内存的资源用于写入。该资源在创建的时候必须绑定了 D3D11_CPU_ACCESS_WRITE标签 |
| D3D11_MAP_READ_WRITE | 映射到内存的资源用于读写。该资源在创建的时候必须绑定了 D3D11_CPU_ACCESS_READ和D3D11_CPU_ACCESS_WRITE标签 |
| D3D11_MAP_WRITE_DISCARD | 映射到内存的资源用于写入,之前的资源数据将会被抛弃。该 资源在创建的时候必须绑定了D3D11_CPU_ACCESS_WRITE和 D3D11_USAGE_DYNAMIC标签 |
| D3D11_MAP_WRITE_NO_OVERWRITE | 映射到内存的资源用于写入,但不能复写已经存在的资源。 该枚举值只能用于顶点/索引缓冲区。该资源在创建的时候需要 有D3D11_CPU_ACCESS_WRITE标签,在Direct3D 11不能用于 设置了D3D11_BIND_CONSTANT_BUFFER标签的资源,但在 11.1后可以。具体可以查阅MSDN文档 |
最后映射出来的内存我们可以通过memcpy_s函数来更新。
默认情况下,若待访问资源仍在被GPU使用,CPU会阻塞直到能够访问该资源。
注意:千万不要对只支持写操作的映射内存区域进行读取操作!否则这会招致十分显著的性能损失。即便是像这样的C++代码:
*((int*)MappedResource.pData) = 0都会引发读操作从而触发性能损失。这在x86汇编表示为AND DWORD PTR [EAX], 0。
ID3D11DeviceContext::Unmap函数--让指向资源的指针无效并重新启用GPU对该资源的访问权限
void ID3D11DeviceContext::Unmap(
ID3D11Resource *pResource, // [In]包含ID3D11Resource接口的资源对象
UINT Subresource // [In]缓冲区资源填0
);
现在需要利用mBuffer结构体变量用于更新常量缓冲区,其中view和proj矩阵需要预先进行一次转置以抵消HLSL列主矩阵的转置,至于world矩阵已经是单位矩阵就不需要了:
m_CBuffer.world = XMMatrixIdentity(); // 单位矩阵的转置是它本身
m_CBuffer.view = XMMatrixTranspose(XMMatrixLookAtLH(
XMVectorSet(0.0f, 0.0f, -5.0f, 0.0f),
XMVectorSet(0.0f, 0.0f, 0.0f, 0.0f),
XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f)
));
m_CBuffer.proj = XMMatrixTranspose(XMMatrixPerspectiveFovLH(XM_PIDIV2, AspectRatio(), 1.0f, 1000.0f));
D3D11_MAPPED_SUBRESOURCE mappedData;
HR(m_pd3dImmediateContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData));
memcpy_s(mappedData.pData, sizeof(m_CBuffer), &m_CBuffer, sizeof(m_CBuffer));
m_pd3dImmediateContext->Unmap(m_pConstantBuffer.Get(), 0);
DEFAULT更新
ID3D11DeviceContext::UpdateSubresource方法[1]--更新缓冲区的数据
该方法可以用于更新允许GPU写入的资源:
void ID3D11DeviceContext::UpdateSubresource(
ID3D11Resource *pDstResource, // [In]需要更新的常量缓冲区
UINT DstSubresource, // [In]缓冲区资源填0
const D3D11_BOX *pDstBox, // [In]忽略,填nullptr
const void *pSrcData, // [In]用于更新的数据源
UINT SrcRowPitch, // [In]忽略,填0
UINT SrcDepthPitch); // [In]忽略,填0
该方法仅可以用于以D3D11_USAGE_DEFAULT或D3D11_USAGE_STAGE方式创建的资源,并且不能用于深度模板缓冲区和支持多采样的缓冲区。
ID3D11DeviceContext::UpdateSubresource的性能表现取决于是否出现与待更新缓冲区的资源竞争。例如,GPU正在执行绘制操作时占用了该缓冲区,然后CPU发出了对同一个缓冲区的UpdateSubresource操作。
- 当出现资源竞争时,
UpdateSubresource会对源数据进行2次拷贝。第一次是CPU拷贝一份资源在临时的内存空间让GPU命令缓冲能够访问它,发生在该方法被返回之前。然后第二次由GPU从内存拷贝到不可映射的显存区域。第二次拷贝通常是异步发生的,因为这是在GPU命令缓冲被刷新后执行的。 - 若没有出现资源竞争,
UpdateSubresource的行为取决于CPU认为怎样会更快:像第一步那样执行,或者直接从CPU拷贝到最终的显存资源位置。具体行为还是要依赖于系统。
该方法本身涉及到CPU的拷贝操作,CPU运行开销会比较大一些,而且还需要留有足够的显存空间。
注意:如果用于更新着色器的常量缓冲区,不能对其中的数据部分更新,必须完整地进行数据的更新。
使用该方法只需要一句代码就可以更新:
m_CBuffer.world = XMMatrixIdentity(); // 单位矩阵的转置是它本身
m_CBuffer.view = XMMatrixTranspose(XMMatrixLookAtLH(
XMVectorSet(0.0f, 0.0f, -5.0f, 0.0f),
XMVectorSet(0.0f, 0.0f, 0.0f, 0.0f),
XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f)
));
m_CBuffer.proj = XMMatrixTranspose(XMMatrixPerspectiveFovLH(XM_PIDIV2, AspectRatio(), 1.0f, 1000.0f));
m_pd3dImmediateContext->UpdateSubresource(m_pConstantBuffer.Get(), 0, nullptr, &m_CBuffer, 0, 0);
ID3D11DeviceContext::*SSetConstantBuffers方法--渲染管线某一着色阶段设置常量缓冲区
这里的*可以是V, H, D, C, G, P六种可编程渲染管线阶段,函数的形参都基本一致。
现在更新了数据后,我们还需要给顶点着色阶段设置常量缓冲区供使用。
void ID3D11DeviceContext::VSSetConstantBuffers(
UINT StartSlot, // [In]放入缓冲区的起始索引,例如上面指定了b0,则这里应为0
UINT NumBuffers, // [In]设置的缓冲区数目
ID3D11Buffer *const *ppConstantBuffers); // [In]用于设置的缓冲区数组
绑定常量缓冲区的操作通常只需要调用一次即可:
m_pd3dImmediateContext->VSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf());
HLSL代码
该例程所用的HLSL代码如下:
//Cube.hlsli
cbuffer ConstantBuffer : register(b0)
{
matrix World;
matrix View;
matrix Proj;
}
struct VertexIn
{
float3 posL : POSITION;
float4 color : COLOR;
};
struct VertexOut
{
float4 posH : SV_POSITION;
float4 color : COLOR;
};
// Cube_VS.hlsl
#include "Cube.hlsli"
VertexOut VS(VertexIn vIn)
{
VertexOut vOut;
vOut.posH = mul(float4(vIn.posL, 1.0f), gWorld); // mul 才是矩阵乘法, 运算符*要求操作对象为
vOut.posH = mul(vOut.posH, gView); // 行列数相等的两个矩阵,结果为
vOut.posH = mul(vOut.posH, gProj); // Cij = Aij * Bij
vOut.color = vIn.color; // 这里alpha通道的值默认为1.0
return vOut;
}
// Cube_PS.hlsl
#include "Cube.hlsli"
float4 PS(VertexOut pIn) : SV_Target
{
return pIn.color;
}
注意:在HLSL中,矩阵乘法不能用*运算符,该运算符要求两个矩阵行列数相同,运算的结果也是一个同行列数的矩阵,运算过程为:
Cij = Aij * Bij。应该使用mul函数进行替代。
GameApp::UpdateScene方法--逐帧更新数据
绘制之前我们得让立方体转起来,不然就只能看到立方体的正面。在这里我们让立方体同时绕X轴和Y轴旋转,修改世界矩阵即可(无需太在意旋转矩阵的设置是否合理,仅仅是为了演示效果):
void GameApp::UpdateScene(float dt)
{
static float phi = 0.0f, theta = 0.0f;
phi += 0.0001f, theta += 0.00015f;
m_CBuffer.world = XMMatrixTranspose(XMMatrixRotationX(phi) * XMMatrixRotationY(theta));
// 更新常量缓冲区,让立方体转起来
D3D11_MAPPED_SUBRESOURCE mappedData;
HR(m_pd3dImmediateContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData));
memcpy_s(mappedData.pData, sizeof(m_CBuffer), &m_CBuffer, sizeof(m_CBuffer));
m_pd3dImmediateContext->Unmap(m_pConstantBuffer.Get(), 0);
}
GameApp::DrawScene方法
ID3D11DeviceContext::DrawIndexed方法--根据顶点和索引缓冲区进行绘制
在输入装配阶段指定好了顶点缓冲区、索引缓冲区和原始拓补类型后,再绑定常量缓冲区到顶点着色阶段,最后就可以使用ID3D11DeviceContext::DrawIndexed方法来绘制:
void ID3D11DeviceContext::DrawIndexed(
UINT IndexCount, // 索引数目
UINT StartIndexLocation, // 起始索引位置
INT BaseVertexLocation); // 起始顶点位置
举个例子,如果按下述方式调用:
m_pd3dImmediateContext->DrawIndexed(6, 6, 4);
假设顶点缓冲区有12个顶点,索引缓冲区有12个索引,存放的值为{11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0},
上面的调用意味着顶点缓冲区我们从索引4作为我们的基准索引,然后索引缓冲区则是使用了索引6到11对应的索引值,即{5, 4, 3, 2, 1, 0},然后加上基准索引值4为最终取得的原来顶点缓冲区索引为{9, 8, 7, 6, 5, 4}的顶点。
现在我们要绘制12个三角形,构成立方体。GameApp::DrawScene方法实现如下:
void GameApp::DrawScene()
{
assert(m_pd3dImmediateContext);
assert(m_pSwapChain);
static float black[4] = { 0.0f, 0.0f, 0.0f, 1.0f }; // RGBA = (0,0,0,255)
m_pd3dImmediateContext->ClearRenderTargetView(m_pRenderTargetView.Get(), reinterpret_cast<const float*>(&black));
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthStencilView.Get(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 1.0f, 0);
// 绘制立方体
m_pd3dImmediateContext->DrawIndexed(36, 0, 0);
HR(m_pSwapChain->Present(0, 0));
}
效果如下:
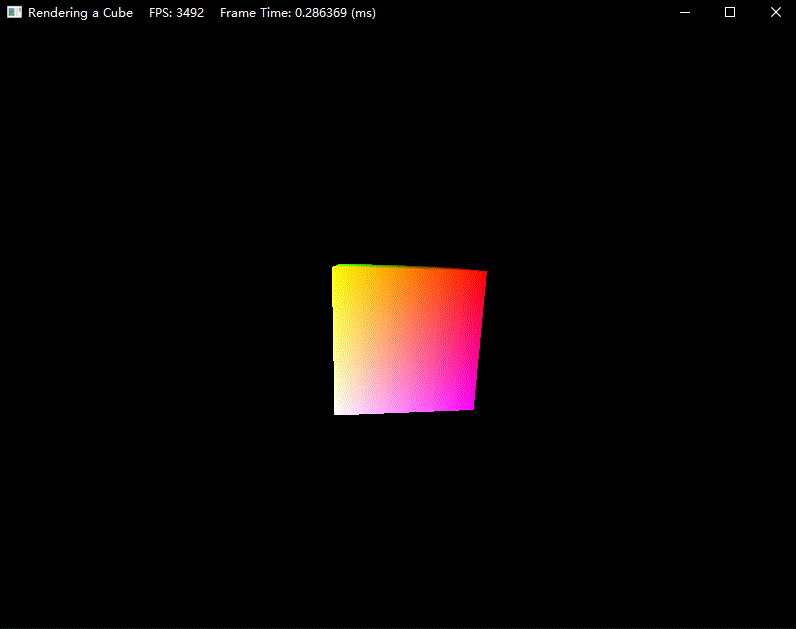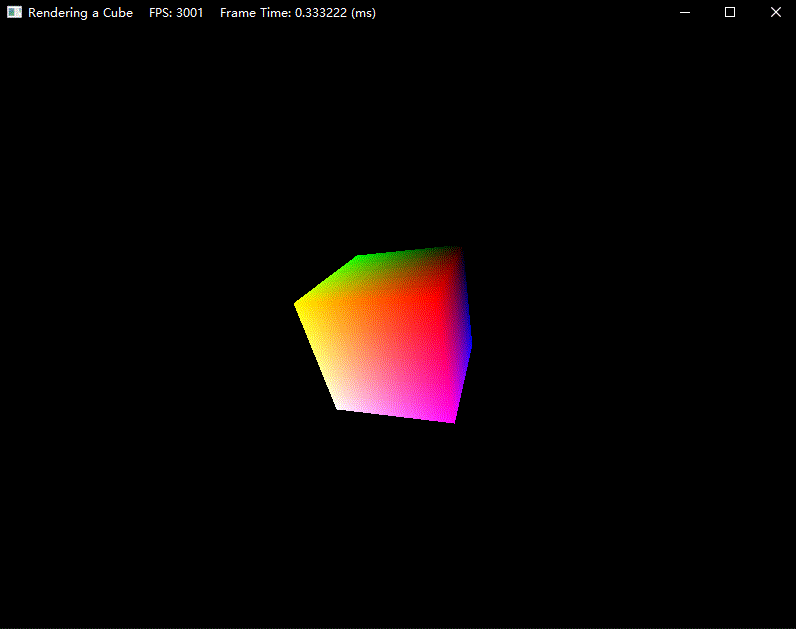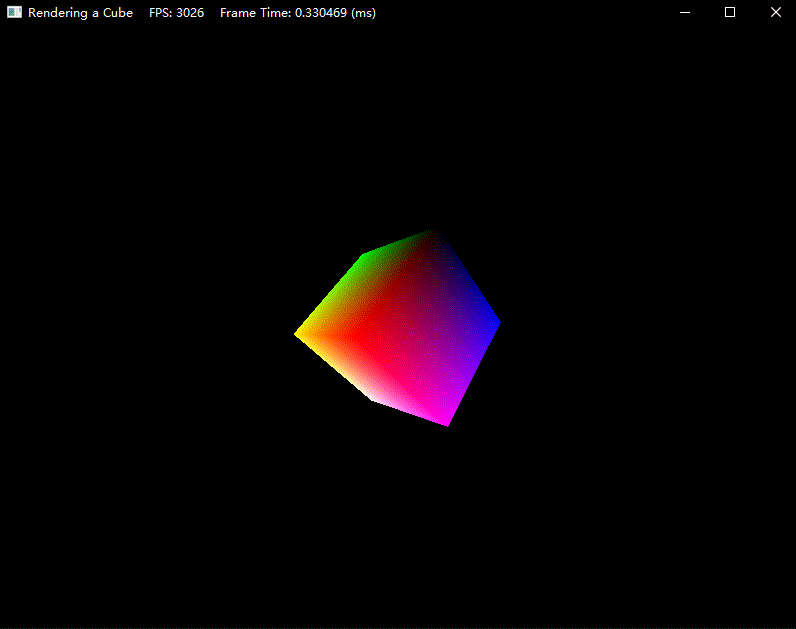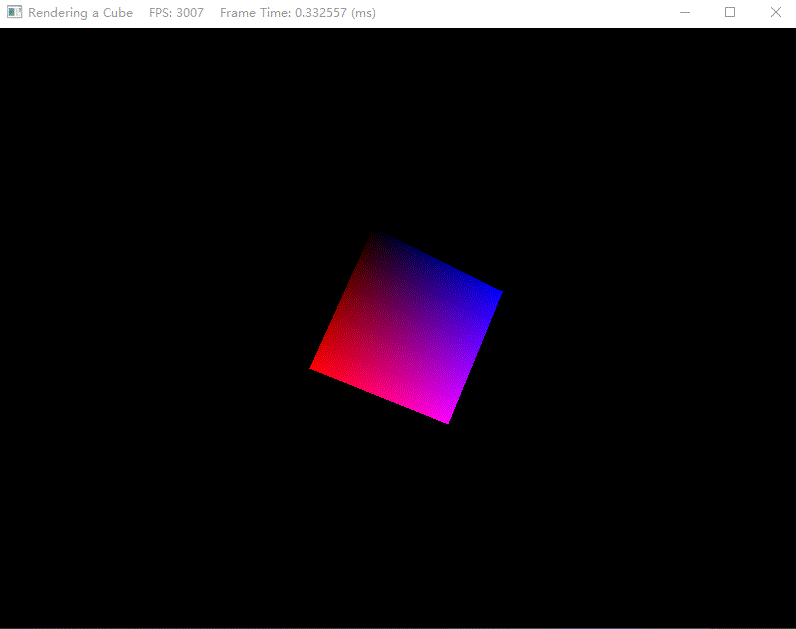
练习题
粗体字部分为自定义题目
- 尝试只用5个顶点绘制四棱锥
- 尝试将四棱锥、立方体的顶点数据放在同一个顶点缓冲区,索引数据也放在同一个索引缓冲区,然后使用这两个缓冲区来绘制出这两个物体(让四棱锥在左边,立方体在右边,可以修改顶点数据,也可以使用变换矩阵)
- 尝试创建动态顶点缓冲区,然后通过
Map和Unmap的方式给顶点缓冲区写入顶点数据。
关于资源的更新,具体可以了解下面两个链接:
how-to-use-updatesubresource-and-map-unmap
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号