稀疏自编码器一览表
以下是我们在推导sparse autoencoder时使用的符号一览表:
| 符号 | 含义 |
 |
训练样本的输入特征,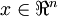 . . |
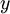 |
输出值/目标值. 这里 能够是向量.
在autoencoder中。 . . |
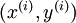 |
第  个训练样本 个训练样本 |
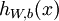 |
输入为 时的如果输出,当中包括參数 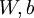 .
该输出应当与目标值 具有同样的维数. .
该输出应当与目标值 具有同样的维数. |
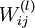 |
连接第 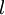 层 层  单元和第 单元和第 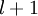 层 单元的參数. 层 单元的參数. |
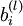 |
第 层 单元的偏置项.
也能够看作是连接第 层偏置单元和第 层 单元的參数. |
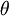 |
參数向量. 能够觉得该向量是通过将參数 组合展开为一个长的列向量而得到. |
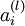 |
网络中第 层 单元的激活(输出)值.
另外,因为 |
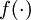 |
激活函数. 本文中我们使用 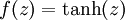 . . |
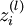 |
第 层 单元全部输入的加权和.
因此有 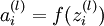 . . |
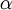 |
学习率 |
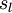 |
第 层的单元数目(不包括偏置单元). |
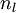 |
网络中的层数. 通常 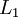 层是输入层, 层是输入层,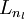 层是输出层. 层是输出层. |
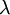 |
权重衰减系数. |
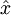 |
对于一个autoencoder,该符号表示其输出值;亦即输入值 的重构值.
与 含义同样. |
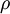 |
稀疏值,能够用它指定我们所需的稀疏程度 |
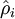 |
(sparse autoencoder中)隐藏单元 的平均激活值. |
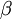 |
(sparse autoencoder目标函数中)稀疏值惩处项的权重. |
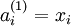 .
.
 浙公网安备 33010602011771号
浙公网安备 33010602011771号