
pytorch构建优化器
这是莫凡python学习笔记。
1.构造数据,可以可视化看看数据样子
import torch import torch.utils.data as Data import torch.nn.functional as F import matplotlib.pyplot as plt %matplotlib inline # torch.manual_seed(1) # reproducible LR = 0.01 BATCH_SIZE = 32 EPOCH = 12 # fake dataset x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1) y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) # plot dataset plt.scatter(x.numpy(), y.numpy()) plt.show()
输出
2.构造数据集,及数据加载器
# put dateset into torch dataset torch_dataset = Data.TensorDataset(x, y) loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
3.搭建网络,以相应优化器命名
# default network class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.hidden = torch.nn.Linear(1, 20) # hidden layer self.predict = torch.nn.Linear(20, 1) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x net_SGD = Net() net_Momentum = Net() net_RMSprop = Net() net_Adam = Net() nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
4.构造优化器,此处共构造了SGD,Momentum,RMSprop,Adam四种优化器
# different optimizers opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR) opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9) opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99)) optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
5.定义损失函数,并开始迭代训练
loss_func = torch.nn.MSELoss() losses_his = [[], [], [], []] # record loss # training for epoch in range(EPOCH): print('Epoch: ', epoch) for step, (b_x, b_y) in enumerate(loader): # for each training step for net, opt, l_his in zip(nets, optimizers, losses_his): output = net(b_x) # get output for every net loss = loss_func(output, b_y) # compute loss for every net opt.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients opt.step() # apply gradients l_his.append(loss.data.numpy()) # loss recoder
6.画图,观察损失在不同优化器下的变化
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam'] for i, l_his in enumerate(losses_his): plt.plot(l_his, label=labels[i]) plt.legend(loc='best') plt.xlabel('Steps') plt.ylabel('Loss') plt.ylim((0, 0.2)) plt.show()
输出
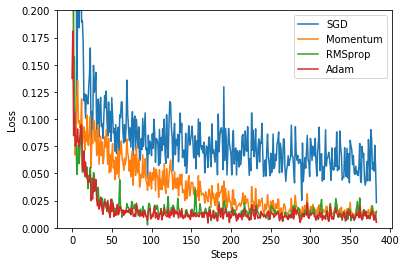
可以看到RMSprop和Adam的效果最好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号