【目标检测+域适应】CVPR18 CVPR19总结
域适应已经是一个很火的方向了,目标检测更不用说,二者结合的工作也开始出现了,这里我总结了CVPR18和CVPR19的相关论文,希望对这个交叉方向的近况有一个了解。
1. 2018_CVPR Domain Adaptive Faster R-CNN for Object Detection in the Wild
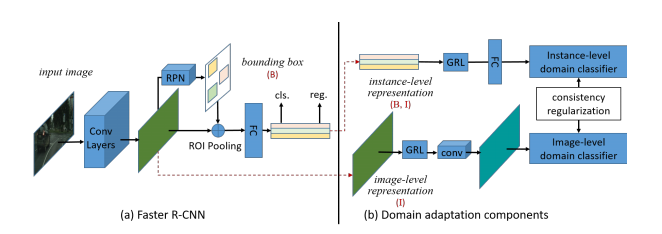
这篇可算是第一个工作,以faster rcnn为baseline,在其基础上添加判别器分支,附着到backbone输出的特征图和roi提取到的向量上,前者代表图像级别的域适应,后者代表物体级别的域适应(roi代表一个物体),分别训练两个判别器,使其无法区分两个域的图像,除此之外,还添加了一致性正则化损失项,保证两个层面的域分类结果一致。特别说明,源域数据没有标签,所以没有检测器的损失,只有域判别器的损失,所以最后的损失项:源域的检测器损失+源域的物体域判别损失+源域的图像域判别损失+源域的物体图像一致性损失+目标域的物体判别损失+目标域的图像判别损失+目标域的物体图像一致性损失
相关代码:
https://github.com/yuhuayc/da-faster-rcnn(官方 caffe)
https://github.com/krumo/Detectron-DA-Faster-RCNN(caffe2)
https://github.com/divyam02/dafrcnn-pytorch/tree/cleaning(pytorch)
https://github.com/tiancity-NJU/da-faster-rcnn-PyTorch (pytorch)
2. 2018_CVPR Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaption
这篇文章似乎出自东京大学?日本的科研能力依然世界前列啊。文章的任务设定与UDA(无监督域适应)略有不同,这篇文章处理的任务中,目标域有图像级标注(图像中有哪几类物体),没有实例级标注,所以文章的题目也说了,本文是弱监督任务。
这篇文章不能只介绍方法了,因为它还有另一大贡献,那就是深度学习最为倚重的数据集,作者直接制作了三个数据集,而且都有实例级标注,太赞了!,这是不小的工作量。
三个数据集都是卡通风格的,与自然图像相比域差异可以说是相当大了,分别是Clipart1K,Comic2K,Watercolor2K,从名字可以看出分别是1000,2000,2000张图片。
具体样子如下,说实话在我看来长的都差不多,为什么选择这几个数据集,可能日本人对漫画有天分和执着吧

说到方法,其实这篇论文的方法就是finetune,跟域适应的路子不太一样,没有域判别器之类的东西,然而,目标域没有实例标签,无法微调,所以作者想了两种方法产生可用来微调的数据-标签对。
1.在源域数据训练检测器
2. 利用cyclegan,将源域数据转换为目标域,然后微调
3. 对目标域数据生成伪标签,继续微调

cyclegan的方法无需多说,详情还得看cyclegan的东西,目标域生成伪标签的原理是用检测器检测出结果,然后只保留图像级标注中存在的物体类别,最后针对剩下的物体类,只取每一类中概率最高的一个检测结果,这样做是想尽量减少错误标注带来的影响吧
相关代码:
https://github.com/naoto0804/cross-domain-detection
3. 2019_CVPR Automatic adaptation of object detectors to new domains using self-training
这篇文章是跟上一篇有相同之处的,那就是都不是常规的域适应的路子,也是微调。不过本文没有用cyclegan生成假样本,只是采用了伪标签。相比于仅利用检测器生成伪标签,本文还利用跟踪器生成伪标签,跟踪器?没错,本文的伪标签数据来自视频,当然训练好的检测器可以用于视频也可用于图像。其中,跟踪器的作用是查缺补漏,以防检测器漏掉某些目标。
论文的贡献不止于上面的,另一个贡献在于对伪标签的处理,使用了软化的技术,软标签,具体内容不想讲了,只是记得如果要使用伪标签,可以考虑借鉴这篇论文的软标签处理方式。
相关代码:http://vis-www.cs.umass.edu/unsupVideo/
4. 2019_CVPR Strong-Weak Distribution Alignment for Adaptive Object Detection
这篇文章采用的是常规的域适应的路子,只是采用了foca loss,效果出奇的好
由于采用的是域适应的路子,可以与第一篇文章做一下比较,第一篇文章是在图像级和实例级两个层面进行域适应,而这篇文章是在低层次特征和高层次特征两个层面进行域适应,没有利用目标信息,只是在图像层面的域适应。
具体而言,选取两个特征图,一个层次低,一个层次高(backbone的最后特征图),接下来的思想是我比较认同的,在低层次特征进行强对齐,也就是标准的交叉熵损失,在高层次特征进行部分对齐(弱对齐),如何达到弱对齐,就是采用focal loss,降低易分类样本的损失权重,然后本文的核心东西就没了,思路简单,效果好
我觉得低层次编码的是域相关信息,比如cityscape和foggy cityscape,差别在于后者有雾,这是一个图像风格的问题,会在低层次进行编码,当然,低层次特征还包含物体的边,角等信息,而高层次特征编码语义信息,对于两个域而言,语义可能相同也可能不同,不该一味地强制语义对齐,所以采取弱对齐是合理的
相关代码:https://github.com/VisionLearningGroup/DA_Detection
5. 2019_CVPR Few-shot Adaptive Faster R-CNN
这篇文章是关于少样本学习的,这个方向不太了解,但是文章主要做的还是目标检测和域适应,要解决的问题是目标域只有少量样本的情况,但是目标域有标签,不是无监督的
它也是在图像级和实例级两个层面进行域适应,但是由于目标域样本少,作者采取了一种成对机制,具体来说,源域的特征图(图像级)切分成若干patch,与目标域的若干patch进行组队,按照两种方式组队,源域patch和源域patch,源域patch和目标域patch,然后训练分类器,这样可训练的样本就增多了,对于实例级也是同样策略,这就是这篇文章的核心思想。
相关代码: 尚未找到
6. 2019_CVPR Adapting Object Detectors via Selective Cross-Domain Alignment
这篇论文完全就是针对CVPR18李文的那篇,完全一样的三组实验,然后全部吊打,太惨了
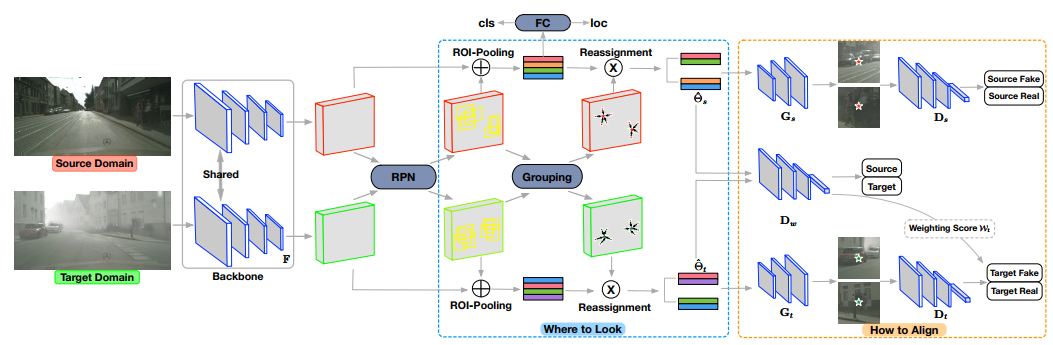
其实这篇论文的想法很合理,切中要害,文章只采用实例级对齐,但是抓住了实例对齐的问题,那就是RPN生成的proposal不准确,这种情况对不准确的区域对齐,产生的结果肯定是受干扰的
于是论文分两步走,第一步找到需要对齐的区域,第二步,对齐
具体来说,对RPN生成的若干proposal, 聚类成K个proposal,认为这K个聚类中心更有可能包含目标,我觉得这还是有道理的
接下来的操作就有些看不到懂了,对K个proposal的特征,进行重构,变成一张图片,这张生成的图片与K个proposal所在区域的真实图片,进行判别,这样就完成了两个域的适应?
我觉得讲不大清楚,上图吧,坦白讲,第一步我深表赞同,第二步摸不着头脑
相关代码:尚未找到
7. 2019_CVPR Towards Universal Object Detection by Domain Attention
这篇论文的思路跟上面所有的都不一样,其他人是进行域适应,在源域学习到的知识用于目标域,而这篇的目标是设计一个检测器,同时检测多个域,方法不是很新奇,就是多个域的数据都送入一个网络训练,当然,论文引入了注意力机制,SEnet等比较时髦的东西,其他的没什么好说的了。
相关代码:https://github.com/xuw080/towards-universal-objects-detection(目前似乎只有项目地址,还没放出代码)
8. 2019_CVPR Diversify and Match:A Domain Adaptive Representation Learning Paradigm for Object Detection
这篇论文我觉得很好,做法很简单,确实是,但是简单有效啊
说的直白点就是数据增强,但是增强的方式很有意思
利用cycle-gan在源域和目标域间生成多个中间域图像,跟源域共享一个标签,这样,可训练的数据就增多了,这些新的数据与源域和目标域一起送入faster rcnn,源域与新图像会计算检测loss,然后所有图像一起会送入域分类器,不同于通常的域适应中的域判别器,这里的分类器不是二分类,是多分类,最终的目的是希望学习到多个域之间的不变特征
至于多个新图像的产生细节,还是跟cycle-gan有关,添加不同的loss,产生不同风格的图像,具体得看论文了。

相关代码:尚未找到
然后对这些方法中的实验结果做个比对

 浙公网安备 33010602011771号
浙公网安备 33010602011771号