
01_服务器架构以及muduo目录
1. 并发服务器介绍
一个简单的C/S架构如下图:
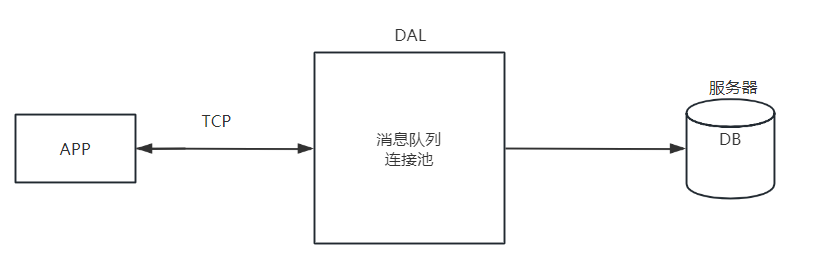
服务器瓶颈:瓶颈1:超出数据库最大连接数:比如服务器最大并发是10,但是此时来了1000个连接请求。由于会导致990个连接请求失效。
解决:引入一个DAL队列服务(消息队列+连接池)。这样子下一次连接就不需要重新创建和数据库的连接,而是在连接池种拿出一个空闲的连接。

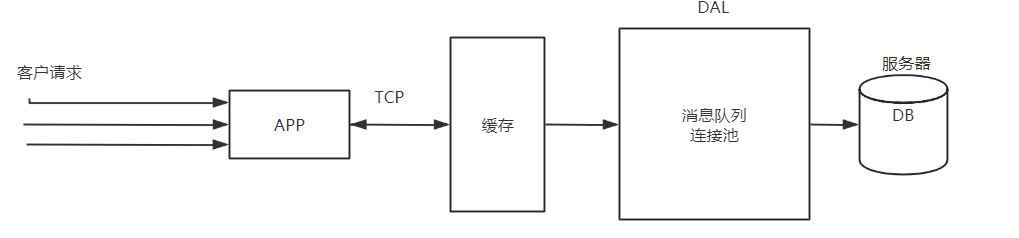
瓶颈2:超出连接时间限制:数据库并发连接数10个,一秒钟最多能处理1000个。如果此时有10000个请求,那么会出现一个0-10秒的延迟等待。如果设置5秒超时断开连接,那么这10000个数据库连接会有5000个连接失效。
解决:引入缓存。减轻数据库的压力,思路是尽可能将业务逻辑处理放到应用服务部分。让数据库少做逻辑处理,只让数据库做一些辅助处理,这是因为数据库层次计算能力远远不如在操作系统层次的计算能力。一个具体的实现是引入缓存(Cache)。
并且这个Cache为了维持伸缩性,要保证既可以和服务器A部署到同一台机器,也可以部署到不同的机器。如果只是部署到服务器A上,那么这个缓存就是一个局部的缓存而不是一个全局的缓存。当此时服务器有多台时,服务器B访问这个缓存比较困难。所以可以使用分布式的缓存,让这些缓存部署到独立的机器上,让所有的服务器都可以访问到。
引入缓存导致问题1:缓存同步问题。方案1:可以使用一个缓存失效时间,当缓存失效之后需要重新去数据库查询让缓存和数据库中的数据一致,但是这种方法实时性比较差。方案2:如果客户需要对数据进行改写,此时客户去直接去数据库进行改写,然后让缓存进行一个相应的更新,这种方式时效性比较高。引入缓存导致问题2:当缓存数据比较大时,可以将一些热点数据放入缓存,一些不热点数据放置磁盘,也就是缓存换页(LRU最近最少使用)。
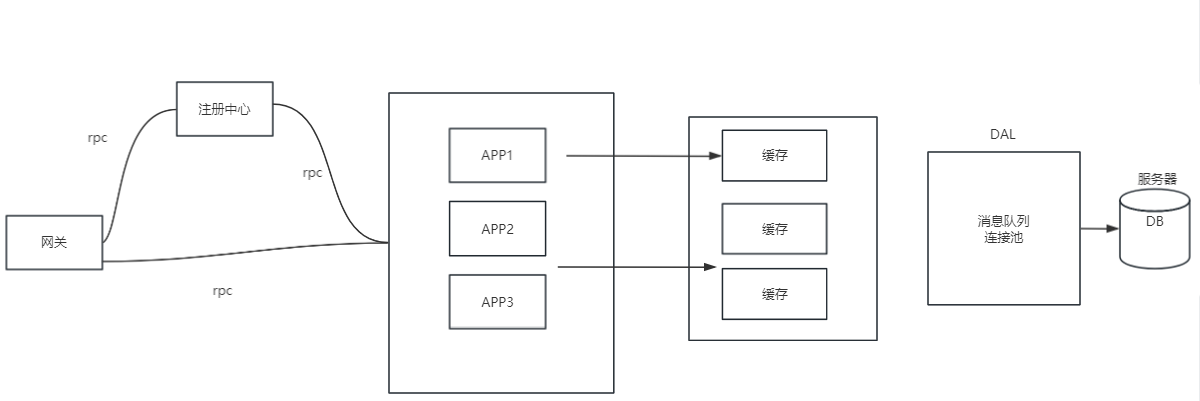
瓶颈3:如果此时出现大量的客户端请求数据库,并且包括了读写操作。这里的写操作会将数据库给锁住,让读操作被阻塞。
解决:读写分离策略。对大多数应用来说,读操作次数一般都会高于写操作次数。对数据库进行一个负载均衡。比如replication机制,也就是主从机制,让一些数据库只进行读操作,一些数据库进行写操作。此时当执行写操作时,执行写操作的数据库执行完后,还需要将读操作的数据库中的数据进行同步。
瓶颈4:当数据库的数据量太大的时。
解决:数据分区。分库(垂直分区)或者分表(水平分区)。分库是数据库按照一定的逻辑将表存至不同数据,比如系统的用户表、业务表、基础表可以放到三个不同的数据库。分表就是将一张表的数据放到不同的数据库,比如将用户表中记录的一部分放到一个数据库,其他记录按照一定逻辑分到其他数据库。注意这两种都需要改写DAL服务逻辑。
瓶颈5:应用层次服务器出现瓶颈。可以将应用层的业务进行分割,也就是微服务模式。
2. 网站架构演变过程
原生架构:Web服务器和数据库服务器在同一个机器上。
2.1 Web服务器和数据库服务器分离。
这是为了避免原生架构中Web服务器或者数据库服务器任一出现瓶颈都会影响网站的访问速度。并且分离之后Web服务器可以进行一个动静分离。这也保证了高可用性。
动静分离:静态资源比如html、css等。动态资源比如jsp、Node.js。可以部署静态资源服务器(Apache/Nginx),动态资源服务器(Tomcat)。
缓存处理:客户端(浏览器)缓存网站资源,减少对Web服务器的访问。其他包括前端页面缓存、页面片段缓存、本地数据缓存。
Web Server集群+读写分离。Web Server集群可以分为前端服务器和后端服务器。数据库也可以采用读写分离。前端负载均衡可以使用DNS负载均衡,在NDS服务器中,可以将多个网络地址配置同一个域名,这样子不同的客户机访问同一个域名,得到的是不同的服务器网络地址。也可以使用反向代理,使用代理服务器将请求均衡的发送给多台内部web服务器之一,从而达到负载均衡效果。
CDN、分布式缓存、分库分表。CDN是内容分发网络,让不同地区访问网站的速度得到提升。分布式缓存是在本地缓存的改进,本地缓存不对其他机器共享,而分布式缓存是对所有机器共享。分库(垂直分库)。
多数据中心+分布式存储:将一些对一致性要求比较的低的数据存放到分布式文件系统计算架构建立数据中心,可以使用nosql,可以将这些nosql数据库放到一些廉价的服务器。这里涉及到DFS、KV-DB、Map/Reduce技术。
3. muduo介绍
线程安全、原生支持多核多线程。
只支持Linux,跨平台导致代码量、宏定义一些混乱。
只支持TCP,不支持UDP。
支持局域网,不考虑广域网应用。
打包方式是静态库而不是动态库。
基于对象的编程,也就是boost bind/function。不通过虚函数暴漏接口。
框架和库的区别:框架提供用户注册一些回调函数,让框架能够调用我们编写的回调函数,这就让控制反转了。也就是主动权/调用权在框架手里,而不是程序员。所有可以使用muduo当成一个框架来使用,但是作者陈硕把muduo当成一个库而不是一个框架。
4. 面向对象编程风格
muduo只暴露具体类,不暴露抽象类,也不虚函数作为接口。这说明muduo不使用面向对象的编程思想,而是使用基于对象的编程思想。这二者有什么区别吗?以下是使用面向对象的思想对线程库thread的做法。
5. muduo_base库源码分析
5.1 目录结构
Muduo的目录结构如下:

Muduo的基础库base主要内容如下:

5.2 Timestamp源码剖析
- 继承基类:
class Timestamp :
public muduo::copyable,//空基类,标识类。只要继承该类则说明这个类是值语义,可以拷贝的,并且拷贝之后与原对象脱离关系。对象语义要么是不能拷贝,要么就是拷贝之后与原对象仍然存在一定关系,比如共享底层资源(要实现自己的拷贝构造函数)
public boost::equality_comparable<Timestamp>,//模板类,要求我们实现==操作符。提供相等性比较
public boost::less_than_comparable<Timestamp>//这是一个模板类,要求我们实现小于符号'<',当我们实现了'<',可自动实现大于符号,大于等于符号等比较操作符,这样子我们就可以只需要实现一个即可,其他通过小于符号推到,这种编程也叫做模板元编程思想。
-
数据成员:microSecondsSinceEpoch_:表示距离1970-01-01 00:00:00相差的微秒数。
-
构造函数有两个:
//无参构造,microSecondsSinceEpoch_设置为0 Timestamp() : microSecondsSinceEpoch_(0) { } //有参构造,microSecondsSinceEpoch_由传递进来的参数赋值 explicit Timestamp(int64_t microSecondsSinceEpochArg) : microSecondsSinceEpoch_(microSecondsSinceEpochArg) { } -
成员方法
//除了重写基类的<和==操作运算符之外 /* timeDifference:两个时间戳之间的相差距离(以秒为单位)。 addTime:增加了多少秒。 几个静态成员函数: static Timestamp now():当前时间 static Timestamp invalid():获取失效的时间 string toFormattedString():转换位字符串的时间:里面有一个函数 gmtime_r(&seconds, &tm_time);这里有_r表示是线程安全,这是将秒数转换为一个结构体,这个结构体包含了年月日等等信息。 */Timestamp Timestamp::now() { struct timeval tv; gettimeofday(&tv, NULL);//获取一个timeval的结构体,第二个是时区,当前不需要所以返回一个空指针。 int64_t seconds = tv.tv_sec;//获取秒数(距离1970-01-01 00:00:00) return Timestamp(seconds * kMicroSecondsPerSecond + tv.tv_usec);//加上微秒数即可。 } -
额外知识
//这是一个编译时断言,区别与assert(运行时断言),在编译时就会去检查是否为true还是false。下面是判断Timestamp的大小等于int64_t的大小,这是因为它只有一个数据成员microSecondsSinceEpoch_,并且类型是int64_t。 static_assert(sizeof(Timestamp) == sizeof(int64_t); //这里是为了方便跨平台。比如int64_t在32位系统中是long long int,也就是lld。但是在64位就是long int,也就是ld。 printf("%d" PRld64 "\n", value);//这表示在64位等价于ld,32位系统等价于lld写法。
