Drbd+Heatbeat实现NFS共享文件存储高可用
一、Drbd与Heartbeat简介
1.1 Drbd简介:
Drbd是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像。与心跳连接结合使用,也可以把它看作是一种网络RAID;简单的说使用drbd镜像技术实现后台两台服务器数据同步。
1.2 Drbd工作机制:
Drbd负责接收数据,把数据写到本地磁盘,然后发送给另一个主机。另一个主机再将数据存到自己的磁盘中。目前,drbd每次只允许对一个节点进行读写访问,这对于通常的故障切换高可用性集群来讲已经足够用了。以后的版本将支持两个节点进行读写存取。
1.3 Drbd的三种协议:
A 数据一旦写入磁盘并发送到网络中就认为完成了写入操作
B 收到接收确认就认为完成了写入操作
C 收到写入确认就认为完成了写入操作
2.1 Heartbeat简介:
Heartbeat是Linux-HA 工程的一个组成部分,它实现了一个高可用集群系统。心跳服务和集群通信是高可用集群的两个关键组件,在 Heartbeat 项目里,由 heartbeat 模块实现了这两个功能。heartbeat最核心的包括两个部分,心跳监测部分和资源接管部分,心跳监测可以通过网络链路和串口进行,而且支持冗余链路,它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运行在对方主机上的资源或者服务,keepalived主要控制IP飘移,配置应用简单,而且分层,layer3,4,5,各自配置极为简单,heartbeat不但可以控制IP飘移,更擅长对资源服务的控制,配置,应用比较复杂。
2.2 Heartbeat工作原理:
通过修改Heartbeat的配置文件,可以指定哪台Heartbeat服务器作为主服务器,则另一台服务器自动成为热备服务器,然后在热备服务器上配置Heartbeat守护程序来监听来自主服务器的心跳消息。如果热备服务器在指定的时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务的所有权,接替主服务器继续不间断的提供服务,从而达到资源及服务高可用性的目的。以上描述是heartbeat主备的模式,heartbeat还支持主主模式,即两台服务器互为主备,这时它们之间会相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的心跳报文,那么,一方就会认为对方失效或者宕机了,这每个运行正常的主机就会启动自身的资源接管模块来接管运行在对方主机上的资源或者服务,继续为用户提供服务。一般情况下,可以较好的实现一台主机故障后,企业业务仍能不间断的持续运行。注意:所谓的业务不间断,在故障转移期间也是需要切换时间的<例如:停止数据库及存储服务等>heartbeat的主备高可用的切换时间一般是在5-20秒左右(服务器宕机的切换比人工切换要快)。另外,和keepalived高可用软件一样,heartbeat高可用是操作系统级别的,不是服务(软件)级别的,可以通过简单的脚本控制,实现服务级别的高可用。
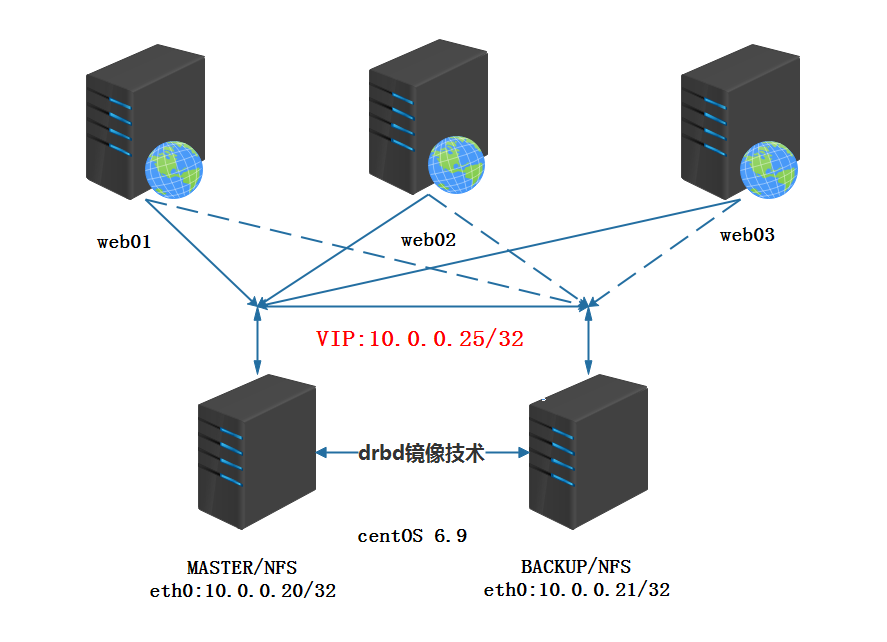
二、架构图
三、Drbd环境搭建
1.hosts解析
vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.0.20 drbd01 10.0.0.21 drbd02
2.同步时间
#time sync by oldboy at 2018-10-12 */5 * * * * /usr/sbin/ntpdate ntp1.aliyun.com &>/dev/null

3.安装drbd
3.1安装依赖环境,编译环境
yum install -y gcc make automake pkgconfig flex kernel-devel-$(uname -r) kernel-headers
3.2编译安装drbd内核驱动
curl -O https://www.linbit.com/downloads/drbd/8.4/drbd-8.4.11-1.tar.gz tar xvf drbd-8.4.11-1.tar.gz -C /usr/local/src cd /usr/local/src/drbd-8.4.11-1 make && make install
3.3 加载模块,验证
modprobe drbd lsmod |grep -i drbd

加载成功!添加开机自加载
echo "modprobe drbd" >> /etc/rc.local
3.4添加附加库
rpm -Uvh http://www.elrepo.org/elrepo-release-6-8.el6.elrepo.noarch.rpm

3.5安装Drbd
yum -y install drbd84-utils kmod-drbd84
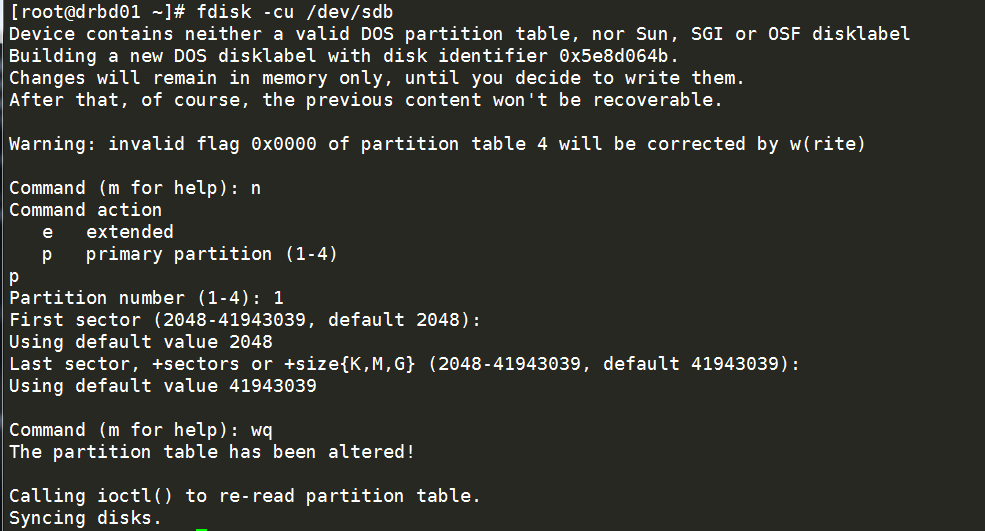
4.两台服务器上的分区/dev/sdb1作为drbd的网络mirror分区
5.开始配置NFS
yum -y install nfs-utils

创建共享目录
mkdir -p /backup echo "/backup *(rw,no_root_squash,no_all_squash,sync)" >/etc/exports
NFS开机设置
/etc/init.d/rpcbind start chkconfig rpcbind on chkconfig nfs off
注意:NFS不需要启动,也不需要设置成开机启动,这些都将由后面的Heartbeat来完成。

7.开始配置Drbd
配置drbd配置文件(两个节点)
vim /etc/drbd.d/global_common.conf
global {
usage-count yes; #是否参加DRBD使用者统计
}
common {
protocol C; #使用drbd的第三种同步协议
disk {
on-io-error detach;
}
syncer {
rate 100M; #100M传输速度
}
}
resource nfs {
on drdb01 { #主机名称
device /dev/drbd1; #drbd网络磁盘
disk /dev/sdb1; #本地需要挂载的磁盘
address 10.0.0.20:7899; #主ip地址加drbd端口
meta-disk internal;
}
on drdb02 {
device /dev/drbd1;
disk /dev/sdb1;
address 10.0.0.21:7899;
meta-disk internal;
}
}
简化配置文件
global {
usage-count yes; #是否参加DRBD使用者统计
}
common {
protocol C; #使用drbd的第三种同步协议
disk {
on-io-error detach;
}
syncer {
rate 100M; #100M传输速度
}
}
resource nfs {
device /dev/drbd1; #drbd网络磁盘
disk /dev/sdb1; #本地需要挂载的磁盘
meta-disk internal;
on drdb01 { address 10.0.0.20:7899; }
on drdb02 { address 10.0.0.21:7899; }
}
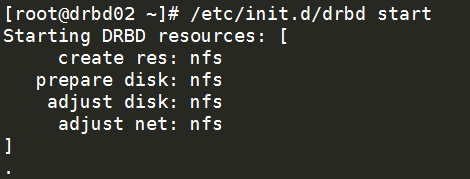
8.启动Drbd
激活前面配置的Drbd资源nfs
drbdadm create-md nfs

启动drbd
/etc/init.d/drbd start
加入开机自启
chkconfig drbd on
查看运行状态,两台设备都处于Secondary/Secondary状态.
cat /proc/drbd

初始化主机(这几步只在主节点上操作)
drbdadm primary all #这台设备成为所有资源的主。
如果命令失败,执行下一条
drbdadm -- --overwrite-data-of-peer primary all #把此节点设置为主节点,且从头开始同步数据
查看格式化进度
watch -n1 'cat /proc/drbd'

说明:
cs:两台数据连接状态
ro:两台主机的状态
ds:磁盘状态是“UpToDate/UpToDate”,同步状态。
9.Drbd的使用
mkfs.ext4 /dev/drbd1 #在主上执行 mount /dev/drbd1 /backup #挂载在backup文件上
注意:secondary节点上不允许对DRBD设备进行任何操作,包括只读。所有的读写操作只能在主节点上进行,只有当主节点挂掉时,secondary节点才能提升为主节点,继续进行读写操作。
四、Heatbeat环境搭建
1.hearbeat依赖epl源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
2.主从安装hearbeat
yum -y install heartbeat
3.修改配置
cd /usr/share/doc/heartbeat-3.0.4/ cp authkeys ha.cf haresources /etc/ha.d/ cd /etc/ha.d
修改authkeys
一共有三种认证方式供选择,第一种是CRC循环冗余校验,第二种是SHA1哈希算法,第三种是MD3哈希算法,其中他们的密码可以任意设置,但是两边密码必须保持一致。
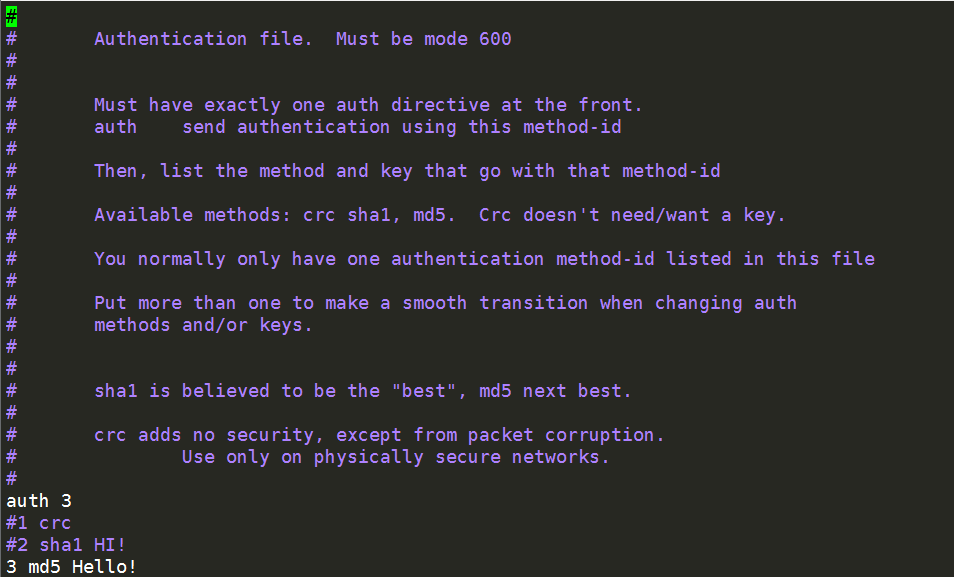
授权authkeys
chmod 600 authkeys
修改haresources文件,在最后一行加入VIP
echo "drdb01 IPaddr::10.0.0.25/32/eth0 drbddisk::nfs Filesystem::/dev/drbd1::/backup::ext4 nfs" >>haresources
drdb01 IPaddr::10.0.0.25/32/eth0 #主机名 后跟虚拟IP地址、接口
drbddisk::nfs #管理drbd资源的名称
Filesystem::/dev/drbd1::/backup::ext4 nfs #文件系统::挂载的目录及格式::后跟nfs资源脚本
4.修改ha.cf文件
debugfile /var/log/ha-debug #设定debug文件目录 logfile /var/log/ha-log #设定日志文件目录 logfacility local0 #利用系统日志打印日志 keepalive 2 #设定检查时间间隔为1s deadtime 30 #设定在10s内没有心跳信号,则立即切换服务 warntime 10 #设定告警时间为5s(5s内没有收到对方的回应就报警) initdead 120 #设定初始化时间为60s udpport 694 #设定集群节点间的通信协议及端口为udp694监听端口(该端口可以修改) ucast eth0 10.0.0.21 #设定心跳方式使用单播方式,并且是在eth0接口上进行单播,ip地址为对方的IP(网卡名称要一致性的IP)从机要改成主机的IP auto_failback off #当主节点恢复后,是否自动切回,一般都设为off node drdb01 #指定两个节点 node drdb02 ping 10.0.0.254 #两个IP的网关 respawn hacluster /usr/lib64/heartbeat/ipfail #使用这个脚本去侦听对方是否还活着(使用的是ICMP报文检测)
5.启动Heartbeat(先主后从)
/etc/init.d/heartbeat start chkconfig heartbeat on netstat -tunlp|grep hear

主库上查看
查看VIP ip a|grep eth0

查看磁盘 df -h

从库上查看
查看VIP,没看到VIP是对的,只有主宕了才会切。

查看磁盘,没有挂载盘是对的,主宕了才会挂载过来。

6.测试目录是否能够共享
实验挂载盘的服务器:10.0.0.25,进入对应的要挂载的目录下创建同名的目录
挂载到VIP上
showmount -e 10.0.0.25 #showmount -e 挂载的VIP地址
将共享文件的目录挂载到10.0.0.25的/backup上
mount -t nfs 10.0.0.25:/backup /backup
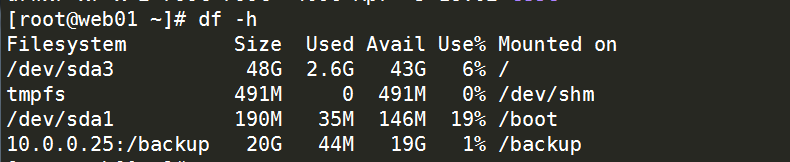
挂在完成,实现共享存储。
7.测试高可用
1.进到主服务器上,把服务关了看看。

查看VIP是否释放 ip a|grep eth0 可以看到Vip已经释放

查看drbd资源是否释放df -h 可以看到资源已经释放。

查看资源状态变cat /proc/drbd 查看资源状态变为从

2.进到从服务器查看状态
VIP是否漂移过来ip a|grep eth0 已看到VIP飘移成功

查看drbd资源df -h Drbd资源切换成功,并挂载
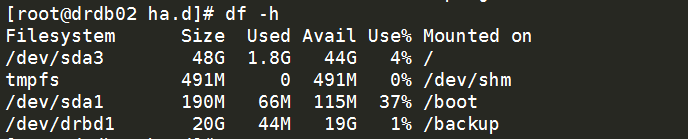
查看资源状态变cat /proc/drbd 查看资源状态变为主

主从切换完成,到此Drbd+Heartbeat实现Nfs的高可用至此结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号