NumPy 简单操作
NumPy 简单操作
参考自:
https://www.runoob.com/numpy/numpy-tutorial.html
https://www.bilibili.com/video/BV1Jt4y1h7Vt?p=33&vd_source=5ea526e05548d953b6378f5fbd5c1e6d
安装:
pip install numpy
导入:
import numpy as np
创建数组
np.array
numpy.array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
返回一个 NumPy 的数组
- object:一个序列对象
- dtype:可选。设置数组的数据类型,一个数组只能存放同一种类型的数据。
- copy:可选。
True则返回一个当前 object 的副本。False则会返回同一个对象。- order:可选。用哪种内存布局创建数组,可选项为:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序
- ndmin:可选。设置数组的维度
- subok:可选。为 True,返回的对象则和 object 的数据类型一样。False 则会返回基础的 np.array 类型。
譬如:
import numpy as np
a = np.array([1, 2, '3'])
b = np.array([1.1, 2, 3])
print(a) # ['1' '2.1' '3']
print(b) # [1.1 2. 3. ]
array 会自动设置数据类型。并且一个数组只能存放一种类似的数据。
譬如第一个序列
a中包含字符串和数字,最终将所有的数字也存放成字符串第二个序列
b中包含了浮点型数字,则将所有的数据全部设置成了浮点数
设置数据类型:
a = np.array([1, 2.1, '3'], dtype='float') # 浮点数
b = np.array([1.1, 2, '3'], dtype='int') # 整数
是否复制:
a = np.array([1, 2.1, '3'])
b = np.array(a, copy=False)
c = np.array(a)
print(a is b) # True
print(a is c) # False
维度:
a = np.array([1, 2.1, '3'], ndmin=3)
print(a) # [[['1' '2.1' '3']]]
print(a.ndim) # 3
print(a.shape) # (1, 1, 3)
a.shape可以查看数组的形状:第一维度有 1 个元素,第二维度有 1 个元素,第三维度有 3 个元素。
手动创建多维度的数组:
a = np.array([[1,2], [3,4]])
print(a) # [[1 2] [3 4]]
print(a.ndim) # 2
print(a.shape) # (2, 2)
subok:
import numpy as np
a = np.mat('1 2; 3 5') # 创建一个 matrix 对象
b = np.array(a, subok=True) # 返回的数据对象会和 a 类型一样
c = np.array(a)
print(type(a)) # <class 'numpy.matrix'>
print(type(b)) # <class 'numpy.matrix'>
print(type(c)) # <class 'numpy.ndarray'>
np.asarray
和 np.array 类似,只是参数少了一些。
np.asarray(obj, dtype=None, order=None)
它可以将 obj 转换成数组。obj 可以是列表,元组,嵌套的元组,多维数组等。
a = (2,3,4)
a = np.asarray(a)
print(a)
np.frombuffer / np.fromiter
可以从缓存,或者从可迭代对象来生成数组:
np.frombuffer(buffer, dtype=float, count=-1, offset=0)
np.fromiter(iterable, dtype, count=-1)
- buffer:任意对象,会以流的形式读取
- count:读取的数据量。-1 代表读取所有数据
- offset:读取的起始位置。默认为 0
- iterable:一个可迭代对象。
import numpy as np
s = b'Hello World'
a = np.frombuffer(s, dtype = 'S1')
list = range(5)
it = iter(list)
x = np.fromiter(it, dtype=float)
np.ones / np.zeros / np.empty
np.ones(shape, dtype)
np.zeros(shape, dtype)
np.empty(shape, dtype)
zeros 可以生成一个自定义形状的、填充值为 0 的数组
ones 可以生成一个自定义形状的、填充值为 1 的数组
empty 可以生成一个自定义形状的、填充值为任意随机数的数组
a = np.zeros((2, 3), int) # 定义一个 2行3列,int 类型的数组
b = np.ones((3, 3), float)
c = np.empty((3,3))
print(a)
print(b)
print(c)
np.full
np.full(shape, value)
可以根据 value,来填充数组
譬如:
import numpy as np
x = np.full((2,3), 10) # 全部填充成 10
y = np.full((2,3), [1,2,3]) # 每行填充成 [1,2,3]
print(x)
print(y)
"""
[[10 10 10]
[10 10 10]]
[[1 2 3]
[1 2 3]]
"""
np.arange 数字区间
np.arange(start, stop, step, dtype)
和 python 的 range 函数类似,用来生成一组数据
- start:起始值。默认 0
- stop:终止值(生成的序列不包含这个数,开区间)
- step:步长,默认 1
- dtype:数据类型,默认是自动识别(指定类型时要小心,因为可能结果会超出你的预期)
a = np.arange(10)
b = np.arange(0, 5)
c = np.arange(0, 5, 0.5)
print(a) # [0 1 2 3 4 5 6 7 8 9]
print(b) # [0 1 2 3 4]
print(c) # [0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5]
一些奇怪现象:
a = np.arange(0, 10, 0.5, dtype=int)
print(a) # [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
上面的结果很奇怪,是因为它的计算公式是:
dtype(start + step) - dtype(start),即int(0 + 0.5) - int(0),所以结果就变成了上面那样,因此不要轻易主动修改数据类型,尤其是当数据类型和实际想生成的序列类型不一样时。
np.linspace 等差数列
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
它会自动将
start到stop划分成num份的等差数列
- start:起始值
- stop:终止值
- num:数列的长度,最终要生成多少个
- endpoint:True 时包含 stop 的值(闭区间);False 不包含
- retstep:为 True 时,返回 (
samples,step),即将步长也返回- dtype:数据类型
>>> np.linspace(2.0, 3.0, num=5)
array([2. , 2.25, 2.5 , 2.75, 3. ])
>>> np.linspace(2.0, 3.0, num=5, endpoint=False)
array([2. , 2.2, 2.4, 2.6, 2.8])
>>> np.linspace(2.0, 3.0, num=5, retstep=True)
(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
np.logspace
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
从
base的start次方开始,到base的stop次方为止,划分num份等比序列
- start:起始值
- stop:终止值
- num:数列的长度,最终要生成多少个
- endpoint:True 时包含 stop 的值(闭区间);False 不包含
- base:对数 log 的底数
- dtype:数据类型
a = np.logspace(1, 5, num=5, base=2)
print(a) # [ 2. 4. 8. 16. 32.]
从 2^1 到 2^5 次方,按照等比的方式,划分 5 份
数据的属性
a = np.array([1, 2, 3])
print(a.ndim) # 维度
print(a.shape) # 数组的维度
print(a.dtype) # 数据类型
print(a.itemsize) # 每个元素的大小,字节为单位
print(a.size) # 元素的总个数
数组操作
数组切片和索引
一维数组
一维数组的切片和 python 的列表切片是一样的,结构都是:[start:stop:step]
a = np.arange(10)
print(a[:]) # 整个列表所有元素
print(a[5:]) # 从索引 5 到最后
print(a[1:5]) # 从索引 1 到 5
print(a[1:5:2]) # 从索引 1 到 5,步长为 2
print(a[2]) # 获取索引为 2 的元素
二维数组
一维数组的切片,也适用于二维数组。
a = np.arange(20).reshape((4, 5))
print(a)
print("前两行:", a[1:3])
print("第2行的第2个元素:", a[1][1])
但是二维数组还有一些其他的切片方式:
[rows, cols]
- 逗号之前用来选取行(第一个维度),逗号之后用来选取列(第二个维度);数组有几个维度,就可以有
维度-1个逗号。- rows, cols 是切片的表达式,譬如:
...代表所有行/列。:也可以表示所有行/列。1:3表示索引第 1-3 行/列。
实例:
a = np.arange(20).reshape((4, 5))
print(a)
print("所有行的第二列:")
print(a[..., 1]) # 等同于 a[:, 1]
print("前两行的第一列")
print(a[:2, 0])
print("前两行的所有列")
print(a[:2, ...]) # 等同于 a[:2]
多维数组
和二维类似:
a = np.arange(20).reshape((2,2,5)) # 三维数组
# 意思是:第一个维度取所有值,第二个维度取所有值,第三个维度取第2列
print(a[..., :, 1])
更高级的索引
上面我们讲了 [rows, cols] 这种切片方法。其实 rows, cols 还可以写成列表的形式,譬如:
a = np.arange(20).reshape((4, 5))
print(a)
print("会获取:第0行的第0个元素,第1行的第2个元素,第2行的第4个元素:")
print(a[[0, 1, 2], [0, 2, 4]])
当写成
obj[list1, list2]这种形式时,它会将 list1 和 list2 的元素一一对应,在数组上找到相应的元素。
而且,这些不同的取值方式,可以随意搭配:
a[:3, [2, 4]] # 前三行的第 2,4 索引列
a[..., [2, 4]] # 所有行的 2,4 索引列
a[[1,2,3]] # 索引为 1,2,3 的三行
总之,在切片取值时:
,之前的表达式用来取行,逗号之后用来取列...代表取所有的 行/列:是切片的用法,也代表所有的 行/列2:3代表取行/列的范围[]列表代表选取特定的 行/列 的索引
布尔索引
广播简介
讲布尔索引,先讲讲广播。譬如我们对一个切片进行赋值:
a = np.arange(20).reshape((4, 5))
a[1:] = 100
print(a)
"""
[[ 0 1 2 3 4]
[100 100 100 100 100]
[100 100 100 100 100]
[100 100 100 100 100]]
"""
可以看到,我们给一个切片赋值了一个整数,结果切片中,每一个子元素都变成了这个数。这就是广播:它会自动将你做的赋值这种操作,根据一定规则,应用到整个区域内。
除了赋值操作符以外, 比较操作符如:>, < 也支持广播,譬如:
a = np.arange(20).reshape((4, 5))
print(a>10)
"""
[[False False False False False]
[False False False False False]
[False True True True True]
[ True True True True True]]
"""
布尔索引介绍
好了,现在我们讲讲布尔索引。所谓布尔索引,就是可以把 布尔值 作为索引,来获取索引位置的值:
a = np.arange(20).reshape((4, 5))
index = a > 10 # index 是一个 bool 类型的数组
print(a[index]) # [11 12 13 14 15 16 17 18 19]
上面的例子中,它会将 index 数组中的每个元素,和 a 这个数组中的每个元素一一对应,过滤掉布尔值为 False 的元素,留下布尔值为 True 的元素。
布尔索引取反
~ 符号可以对一个布尔数组取反
a = np.arange(20).reshape((4, 5))
index = a > 10
print(a[~index]) # [ 0 1 2 3 4 5 6 7 8 9 10]
布尔索引逻辑 & |
a = np.arange(20).reshape((4, 5))
print(a[(a>5) & (a<10)]) # [6 7 8 9]
切片赋值
在获取到切片后,我们可以对其进行赋值:
a = np.arange(20).reshape((4, 5))
a[1:] = 100 # 从第二行开始,后续每一行中的值都是 100
# a[1::2] = 100 # 当然也可以每隔一行,赋值成 100
print(a)
"""
[[ 0 1 2 3 4]
[100 100 100 100 100]
[100 100 100 100 100]
[100 100 100 100 100]]
"""
获取满足条件的索引位置
a = np.arange(10).reshape((5, 2))
print(a)
print('='*10)
y = np.argwhere(a>5) # 获取满足条件 a>5 的元素的索引
print(y)
"""
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
==========
[[3 0] # 代表行索引为3,列索引为0 的元素,它>5
[3 1]
[4 0]
[4 1]]
"""
reshape
reshape() 可以重塑数组的形状和维度。
a = np.arange(10)
b = a.reshape((2, 5)) # 改成 2行5列,返回一个新的对象。原来的对象不会改变。
print(b)
"""
[[0 1 2 3 4]
[5 6 7 8 9]]
"""
reshape 时,需要注意总个数。譬如上面的例子:
a.reshape((2, 3))就会失败,因为a有 10 个元素,而(2, 3)只有 6 个元素,长度不匹配。reshape 还有一个特殊的用法:
-1,譬如:np.arange(10).reshape(2, -1),它会自动将-1计算出来,变成2行5列
resize
调整数组的长度和形状。
ndarray.resize
数组自身的调整大小的方法,如果调整的长度大于现有的长度,会用 0 来填充。
a = np.arange(10)
a.resize((3, 5)) # 调整成 3行5列,共15个元素。不足的部分会自动填充成 0
print(a)
"""
[[0 1 2 3 4]
[5 6 7 8 9]
[0 0 0 0 0]]
"""
np.resize
numpy 的方法,可以调整一个数组的大小,如果长度大于现有的长度,会用数组自身的元素来填充不足的部分。
a = np.arange(10)
b = np.resize(a, (3,5)) # 使用 np.resize() 可以调整一个对象的大小,它会使用自身的元素填充不足的长度部分。
print(b)
"""
[[0 1 2 3 4]
[5 6 7 8 9]
[0 1 2 3 4]] # 最后这一行,是使用的自身的元素来填充的,即第一行的元素。
"""
数组展开
flatten
将多维度的数组,展开成一维数组
a = np.arange(10).reshape((2, 5))
print(a.flatten()) # [0 1 2 3 4 5 6 7 8 9]
ravel
ravel 也可以展开数组,区别是它返回的是原数组的视图。你对展平的数组进行修改,原数组也会跟着改动。
a = np.arange(20).reshape((4, 5))
b = a.ravel()
b[1]= 1000
print(a) # a 中的数据也会跟着变成 1000
数组转置
arr.T # 它可以将 arr 这个数组,行变成列,列变成行
这个方法等同于
numpy.transpose(arr)
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
print(a)
print(a.T)
"""
[[1 3 2 7 5]
[9 4 1 2 6]]
[[1 9]
[3 4]
[2 1]
[7 2]
[5 6]]
"""
数组复制
arr.copy(order="C") # 按照某种顺序,返回一个数组副本
order: 可选项为:{'C', 'F', 'A', 'K'},即是以行优先的顺序来存储元素,还是以列优先的顺序存储元素。这个参数反映的是元素在内存中的存储方式。
C代表了行优先,F代表列优先
a = np.arange(10).reshape((2, 5))
b = a.copy()
print(a is b) # False
添加数据
np.append(array, values, axis=None)
- array:数组对象,会将 Values 添加到这个对象的副本后面
- values:要添加的内容
- axis:如果是 None,会将
array和values展开,作为一维数组进行添加和返回。
直接添加
不指定 axis 参数,会先展开所有的维度,然后再添加:
a = np.arange(6).reshape((2, 3))
b = np.append(a, [0, 0, 0])
print(b) # [0 1 2 3 4 5 0 0 0]; 上面没有指定 axis,会展开
添加到行
a = np.arange(6).reshape((2, 3))
# 第一:values 参数的维度要和 a 维度一致。第二:指定 axis=0
b = np.append(a, [[0, 0, 0]], axis=0)
print(b)
"""
[[0 1 2]
[3 4 5]
[0 0 0]]
"""
添加到列
a = np.arange(6).reshape((2, 3))
b = np.append(a, [[0, 0, 0], [1,1,1]], axis=1)
print(b)
"""
[[0 1 2 0 0 0]
[3 4 5 1 1 1]]
"""
合并数组的快捷方式
对于二维数组而言, r_ 和 c_ 分别表示上下合并和左右合并:
np.r_[np.zeros((2,3)),np.zeros((2,3))] # 合并两个数组,列方向,即添加成多行数据
np.c_[np.zeros((2,3)),np.zeros((2,3))] # 行方向,水平添加多列
插入数据
np.insert(arr, index, values, axis)
- arr:一个 array-like 对象
- index:可以是整数,切片或者序列。这个参数代表索引值,会在该索引之前插入数据
- values:array-like 对象,代表要插入的数据
- axis:轴的方向。默认是 None,会展平维度后插入。
不使用 axis ,会展开所有的维度:
a = np.zeros((2,3))
b = np.insert(a, 2, [1,1]) # 没指定 axis,会将二维展平,变成一维数组
print(b) # [0. 0. 1. 1. 0. 0. 0. 0.]
插入到行
a = np.zeros((2,3))
b = np.insert(a, 2, [1,1,1], axis=0) # 在索引2之前插入一行
c = np.insert(a, [0,1], [2,2,2], axis=0) # 在索引0,1之前各插入一行
d = np.insert(a, slice(0,2), [3,3,3], axis=0) # 使用切片,同样是在索引0,1之前各插入一行
print(b)
print(c)
插入到列
a = np.zeros((2,3))
b = np.insert(a, 2, [1,1], axis=1)
c = np.insert(a, [0,1], [2,2], axis=1)
print(b)
print(c)
删除数据
np.delete(arr, index, axis=None)
- arr:一个 array-like 对象
- index:可以是整数,切片或者序列。这个参数代表索引值,会在该索引位置删除数据
- axis:轴的方向,默认是 None,会展平维度后删除。
a = np.arange(10).reshape((5, 2))
b = np.delete(a, 2) # 会展平,然后删除索引为2的元素
print(b) # [0 1 3 4 5 6 7 8 9]
删除行
a = np.arange(10).reshape((5, 2))
b = np.delete(a, 1, axis=0) # 删除第二行
print(b)
"""
[[0 1]
[4 5]
[6 7]
[8 9]]
"""
删除列
a = np.arange(10).reshape((5, 2))
b = np.delete(a, 1, axis=1) # 删除第二列
print(b)
"""
[[0]
[2]
[4]
[6]
[8]]
"""
删除重复数据
unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None, *, equal_nan=True)
返回一个已经排完序的不重复的数组。
- ar:array-like 对象
- return_index:会额外返回新数组元素在原数组中的索引
- return_inverse:会额外返回原数组元素在新数组中的索引
- return_counts:会额外返回新数组元素在原数组中的个数
a = np.array([1,2,3,4,5,5,6,6,7,6,7])
x = np.unique(a, return_index=True) # 同时返回新数组元素在原数组中的索引
print(x)
x = np.unique(a, return_inverse=True) # 同时返回原数组元素在新数组中的索引
print(x)
x = np.unique(a, return_counts=True) # 同时返回新数组元素在原数组中的个数
print(x)
"""
(array([1, 2, 3, 4, 5, 6, 7]), array([1, 0, 2, 3, 4, 6, 8], dtype=int64))
(array([1, 2, 3, 4, 5, 6, 7]), array([1, 0, 2, 3, 4, 4, 5, 5, 6, 5, 6], dtype=int64))
(array([1, 2, 3, 4, 5, 6, 7]), array([1, 1, 1, 1, 2, 3, 2], dtype=int64))
"""
拼接数组
np.concatenate
np.concatenate(arrs, axis=None)
- arrs:一组 array,可以将这些数组拼接起来
- axis:轴的方向。默认是添加到行。
import numpy as np
a = np.zeros((2, 3))
b = np.ones((2, 3))
print(np.concatenate((a,b))) # 默认拼接到行
print(np.concatenate((a,b), axis=0)) # 拼接到行
print(np.concatenate((a,b), axis=1)) # 拼接到列
"""
[[0. 0. 0.]
[0. 0. 0.]
[1. 1. 1.]
[1. 1. 1.]]
[[0. 0. 0.]
[0. 0. 0.]
[1. 1. 1.]
[1. 1. 1.]]
[[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]]
"""
np.stack
也是用来拼接数组,但是它返回的数据,维度会多一层。
import numpy as np
a = np.zeros((2, 3))
b = np.ones((2, 3))
print(np.stack((a, b))) # 二维变成三维,行方向堆叠
print(np.stack((a, b), axis=0)) # 二维变成三维,行方向堆叠
print(np.stack((a, b), axis=1)) # 二维变成三维,列方向堆叠
"""
[[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]]]
[[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]]]
[[[0. 0. 0.]
[1. 1. 1.]]
[[0. 0. 0.]
[1. 1. 1.]]]
"""
np.hstack
水平方向堆叠,即添加列。等同于 np.concatenate(arrs, axis=1)
import numpy as np
a = np.zeros((2, 3))
b = np.ones((2, 3))
print(np.hstack((a, b)))
"""
[[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]]
"""
np.vstack
垂直方向堆叠,即添加行。
import numpy as np
a = np.zeros((2, 3))
b = np.ones((2, 3))
print(np.vstack((a, b)))
"""
[[0. 0. 0.]
[0. 0. 0.]
[1. 1. 1.]
[1. 1. 1.]]
"""
数组分割
| 函数 | 数组及操作 |
|---|---|
split |
将一个数组分割为多个子数组 |
hsplit |
将一个数组水平分割为多个子数组(按列) |
vsplit |
将一个数组垂直分割为多个子数组(按行) |
np.split
np.split(ary, indices_or_selections, axis=0)
- ary:要分割的数组
- indices_or_selections:整数或一维数组。用来指示将数组划分成几份或者指示从哪些索引位置切分数组
- axis:轴
import numpy as np
a = np.zeros((6, 4))
b = np.split(a, 2, axis=1) # 按照列分割成2份
c = np.split(a, 2, axis=0) # 按照行分割成2份
print(b)
print(c)
"""
[array([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]]),
array([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]])]
[array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]),
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])]
"""
使用特定索引位置划分:
a = np.zeros((6, 4))
c = np.split(a, [1, 5], axis=0)
print(c)
"""
[array([[0., 0., 0., 0.]]),
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]),
array([[0., 0., 0., 0.]])]
"""
np.hsplit
用法和 split 一样,只是不能指定轴,会切割成多列
import numpy as np
a = np.zeros((6, 4))
c = np.hsplit(a, 2)
print(c)
"""
[array([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]]),
array([[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]])]
"""
np.vsplit
用法同上。会垂直方向切割(按照行切割)
数组排序
np.sort(a, axis=-1, kind=None, order=None)
- a:array 对象
- axis:指定沿着哪个轴排序。默认 -1 沿着最后一个轴排序(可以理解为按照行排序),0 代表按照列排序,1 代表按照行排序。如果设置为 None,则会将数组展平后排序。
- kind:排序方法,可选项为:
- order:如果数组是结构化的、带有字段的数组,可以使用字符串或字符串列表来指定按照那几列排序。
按照行排序
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
x = np.sort(a)
print(x)
"""
[[1 2 3 5 7]
[1 2 4 6 9]]
"""
按照列排序
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
x = np.sort(a, axis=0)
print(x)
"""
[[1 3 1 2 5]
[9 4 2 7 6]]
"""
根据字段排序
dt = np.dtype([("name", 'S10'), ("age", 'i1')])
a = np.array([("wang", 25), ("zhang", 23)], dtype=dt)
print(np.sort(a, order="age")) # [(b'zhang', 23) (b'wang', 25)]
多字段排序
lexsort(keys, axis=None) 可以按照给定的 keys 来排序。
import numpy as np
dt = np.dtype([("name", 'S10'), ("chinese", int), ('math', int), ('total', int)])
# 记录了(人名,语文成绩,数学成绩,总成绩)的数组
score = np.array([("wang", 10, 30, 40), ('zhang', 20, 50, 70),
("li", 50, 40, 90), ('zhao', 10, 60, 70)], dtype=dt)
# 先按照总成绩排序,总成绩相同的情况下继续按照数学成绩排序,然后继续按照语文成绩排序(优先级越高,越放在后面)
index = np.lexsort((score['name'], score['chinese'], score['math'], score["total"]))
for i in index:
print(score[i])
"""
(b'wang', 10, 30, 40)
(b'zhang', 20, 50, 70)
(b'zhao', 10, 60, 70)
(b'li', 50, 40, 90)
"""
获取排序的索引
argsort 的参数和 sort 一样。它可以对数组进行排序,然后返回排序后的元素索引数组
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
x = np.argsort(a)
print(x)
"""
[[0 2 1 4 3]
[2 3 1 4 0]]
"""
迭代数组
np.nditer(arr)
np.nditer(arr)
示例:
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
for x in np.nditer(a):
print(x)
指定读取顺序:
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
for x in np.nditer(a, order='F'): # order 指定读取顺序,F代表列优先,会先从上往下读取第一列的数据,然后第二列...
print(x)
迭代并修改数组:
默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write
a = np.array([[1,3,2,7,5], [9,4,1,2,6]])
for x in np.nditer(a, op_flags=['readwrite']):
x[...] = 2*x # [...] 这种写法是获取原数组的元素,x 本身只是一个副本
print(a)
arr.flat
返回一个迭代器
a = np.arange(20).reshape((4, 5))
for i in a.flat:
print(i)
数据类型
数组类型转换
obj.astype(type) 可以将一个序列对象的类型转换成另一种格式
a = np.arange(10)
b = a.astype(str) # 转换成字符型,返回新类型的对象。原对象类型不变
print(a.dtype, b.dtype) # int32 <U11
numpy 中的数据类型
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
每种内建的类型都有一个唯一定义它的字符代码,如下:
字符 对应类型
b 布尔型
i (有符号) 整型
u 无符号整型 integer
f 浮点型
c 复数浮点型
m timedelta(时间间隔)
M datetime(日期时间)
O (Python) 对象
S, a (byte-)字符串
U Unicode
V 原始数据 (void)
每种数据类型,都有相应的字符代码,我们可以使用字符代码来指定数据类型,譬如字符串
i2可以代表int16类型, 因为2代表了2个字节。
dtype 对象
数据类型对象用来描述与数组对应的内存区域是如何使用的。它描述了如下内容:
- 数据类型(整数?浮点?...)
- 数据的大小(如多少字节)
- 数据字节顺序(大端表示法或者小端表示法)
<意味着小端法,>表示大端表示法 - 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,那么它的形状和数据类型是什么。
import numpy as np
# 使用标量类型
dt = np.dtype(np.int32)
print(dt)
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
dt = np.dtype('i4')
print(dt)
# 字节顺序标注
dt = np.dtype('<i4')
print(dt)
结构化数据类型
import numpy as np
# 设置了两个字段,每个字段拥有自己的数据类型
student = np.dtype([('name', str, 5), ('age', 'i1')])
# 创建了两组数据,每组数据都有两个值,分别对应上面的两个数据类型
a = np.array([('abc', 21),('xyz', 18)], dtype=student)
print(a) # [(b'abc', 21) (b'xyz', 18)]
print(a["name"]) # 获取 name 字段; [b'abc' b'xyz']
print(a["age"]) # age 字段;[21 18]
如上,我们可以使用
np.dtype([("字段名", 字段类型, 字节数)])的格式来定义结构化的数据类型。
广播机制
Broadcast 是 numpy 对两个甩手是进行数值计算的一种方式。比如针对两个 shape 相同的数组进行相加,则将两个数组对应位置元素相加即可。譬如:
a = np.ones((3,4))
b = np.arange(12).reshape((3, 4))
print(a)
print(b)
print(a+b)
"""
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 1. 2. 3. 4.]
[ 5. 6. 7. 8.]
[ 9. 10. 11. 12.]]
"""
如果两个数组的 shape 不相同。则会根据一定的规则,尝试将较短的数组进行补齐,达到 shape 相同,然后进行计算,如下图:
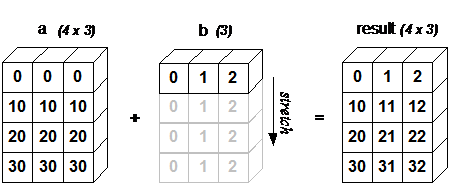
如果两个数组 shape 不同, 并且无法补齐,则无法进行广播,也就无法进行计算了。
数学统计
mean 平均值
a = np.arange(20).reshape(4,5)
print(a.mean()) # 总的平均值
print(a.mean(axis=1)) # 按照行,求每行的平均值
print(a.mean(axis=0)) # 按照列,求每列的平均值
median 中位数
a = np.arange(20).reshape(4,5)
x = np.median(a)
print(x)
std 标准差
a = np.arange(20).reshape(4,5)
x = np.std(a)
print(x)
var 方差
a = np.arange(20).reshape(4,5)
x = np.var(a)
print(x)
max/min 最大值/最小值
a = np.arange(20).reshape(4,5)
print(a.max(), a.min())
还有
numpy.amax(array, axis), numpy.amin(array, axis)这种方式,也能求最大值和最小值
argmax 和 argmin
分别返回最大和最小元素的索引
import numpy as np
a = np.array([[30, 40, 70], [80, 20, 10], [50, 90, 60]])
print('我们的数组是:')
print(a)
print('\n')
print('调用 argmax() 函数:')
print(np.argmax(a)) # 不指定轴,会展开数组成一维
print(np.argmax(a, axis=1))
"""
我们的数组是:
[[30 40 70]
[80 20 10]
[50 90 60]]
调用 argmax() 函数:
7
[2 0 1]
"""
numpy.where()
返回输入数组中满足给定条件的元素的索引
import numpy as np
x = np.arange(9.).reshape(3, 3)
print('我们的数组是:')
print(x)
print('大于 3 的元素的索引:')
y = np.where(x > 3)
print(y)
print('使用这些索引来获取满足条件的元素:')
print(x[y])
"""
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
大于 3 的元素的索引:
(array([1, 1, 2, 2, 2], dtype=int64), array([1, 2, 0, 1, 2], dtype=int64))
使用这些索引来获取满足条件的元素:
[4. 5. 6. 7. 8.]
"""
where 是一种条件函数,还可以指定满足条件与不满足条件位置对应的填充值:
In [80]: a = np.array([-1,1,-1,0])
In [81]: np.where(a>0, a, 5) # 对应位置为 True 时填充 a 对应元素,否则填充 5
Out[81]: array([5, 1, 5, 5])
numpy.extract()
根据某个条件从数组中抽取元素,返回满条件的元素。
import numpy as np
x = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
# 定义条件, 选择偶数元素
condition = np.mod(x,2) == 0
print ('按元素的条件值:')
print (condition)
print ('使用条件提取元素:')
print (np.extract(condition, x))
"""
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
按元素的条件值:
[[ True False True]
[False True False]
[ True False True]]
使用条件提取元素:
[0. 2. 4. 6. 8.]
"""
average 加权平均值
np.average(a, axis=None, weights=None, returned=False)
- a:一个 array-like 对象
- axis:指定轴的方向。默认是 None,会统计所有数据
- weights:权重的 array-like 对象,代表了各个元素的权重。
- returned:如果是 True,会返回 (
average,sum_of_weights), 否则只会返回average
np.average(np.arange(1, 11), weights=np.arange(10, 0, -1))
np.ptp
求数组中最大值和最小值的差值。
import numpy as np
a = np.arange(10).reshape((2, 5))
print(np.ptp(a, axis=1))
百分位数
np.percentile(a, q, axis)
- a:array
- q:一个介于 0~100 的数,这是要设置的百分位数
- axis:沿着哪个轴
比如,假设某个考生在入学考试中的语文部分的原始分数为 54 分。相对于参加同一考试的其他学生来说,他的成绩如何并不容易知道。但是如果原始分数54分恰好对应的是第70百分位数,我们就能知道大约70%的学生的考分比他低,而约30%的学生考分比他高。
import numpy as np
a = np.arange(10).reshape((2, 5))
print(a)
print(np.percentile(a, 50))
print(np.percentile(a, 100))
"""
[[0 1 2 3 4]
[5 6 7 8 9]]
4.5 # 50 分位数值是 4.5
9.0 # 100 分位数是 9
"""
quantile 分位数
target = np.arange(5) # array([0, 1, 2, 3, 4])
x = np.quantile(target, 0.5) # 0.5分位数
print(x) # 2.0
数学计算
sum 求和
a = np.arange(20).reshape(4,5)
print(a.sum(axis=0))
三角函数 sin/cos/tan
import numpy as np
a = np.array([0, 30, 45, 60, 90])
print('不同角度的正弦值:')
# 通过乘 pi/180 转化为弧度
print(np.sin(a * np.pi / 180))
print('\n')
print('数组中角度的余弦值:')
print(np.cos(a * np.pi / 180))
print('\n')
print('数组中角度的正切值:')
print(np.tan(a * np.pi / 180))
around
四舍五入函数,向上取值,可以选择保留几位小数。
around(a, decimals=0)
decimals:指定小数位,默认值 0 代表不进行舍入。正数代表保留几位小数,负数代表舍入到小数点左侧
a = np.array([1.0, 5.55, 123, 0.567, 25.532])
print('原数组:')
print(a)
print('\n')
print('舍入后:')
print(np.around(a))
print(np.around(a, decimals=1))
print(np.around(a, decimals=-1))
"""
原数组:
[ 1. 5.55 123. 0.567 25.532]
舍入后:
[ 1. 6. 123. 1. 26.] # 原封不动,没有舍入
[ 1. 5.6 123. 0.6 25.5] # 保留 1 位小数
[ 0. 10. 120. 0. 30.] # 小数点左侧1位向上舍入
"""
floor / ceil
floor 向下取整,ceil 向上取整
import numpy as np
a = np.array([1.0, 5.55, 123, 0.567, 25.532])
print('原数组:')
print(a)
print('\n')
print('向下取整:')
print(np.floor(a))
print('\n')
print("向上取整:")
print(np.ceil(a))
"""
原数组:
[ 1. 5.55 123. 0.567 25.532]
向下取整:
[ 1. 5. 123. 0. 25.]
向上取整:
[ 1. 6. 123. 1. 26.]
"""
加减乘除
import numpy as np
a = np.arange(9, dtype=np.float_).reshape(3, 3)
print('第一个数组:')
print(a)
print('\n')
print('第二个数组:')
b = np.array([10, 10, 10])
print(b)
print('\n')
print('两个数组相加:')
print(np.add(a, b))
print('\n')
print('两个数组相减:')
print(np.subtract(a, b))
print('\n')
print('两个数组相乘:')
print(np.multiply(a, b))
print('\n')
print('两个数组相除:')
print(np.divide(a, b))
求倒数
import numpy as np
a = np.array([0.25, 1.33, 1, 100])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 reciprocal 函数:')
print (np.reciprocal(a))
"""
我们的数组是:
[ 0.25 1.33 1. 100. ]
调用 reciprocal 函数:
[4. 0.7518797 1. 0.01 ]
"""
求幂
import numpy as np
a = np.array([10, 100, 1000])
print('我们的数组是;')
print(a)
print('\n')
print('求二次方')
print(np.power(a, 2))
print('\n')
print('第二个数组:')
b = np.array([1, 2, 3])
print(b)
print('\n')
print('根据第二个数组求幂')
print(np.power(a, b))
求余
numpy.mod 和 numpy.remainder 都可以用来求余数
import numpy as np
a = np.array([10, 20, 30])
b = np.array([3, 5, 7])
print('第一个数组:')
print(a)
print('\n')
print('第二个数组:')
print(b)
print('\n')
print('调用 mod() 函数:')
print(np.mod(a, b))
print('\n')
print('调用 remainder() 函数:')
print(np.remainder(a, b))
IO
savetxt()
savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
- fname: 文件名
- X:一维或者二维数组
- fmt:存储的数据格式
- delimiter:数据间的分隔符
- newline:行分隔符
- header:字符串形式的文本,会写在文件开头
- footer:字符串形式的文本,会写在文件尾
- comments:注释的起始字符。会将其加在 header 和 footer前面
- encoding:编码
savetxt() 函数是以简单的文本文件格式存储数据,对应的使用 loadtxt() 函数来获取数据。
import numpy as np
a = np.array([1, 2, 3, 4, 5])
np.savetxt('out.txt', a)
b = np.loadtxt('out.txt')
print(b)
loadtxt
从 text 文件中加载数据
loadtxt(fname, dtype=float, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None, *, quotechar=None, like=None)
- fname:要读取的数据来源。可以是文件对象,字符串格式,pathlib.Path, 字符串列表,文件名等等格式。
- dtype:数据类型
- comments:可以是字符或字符列表。用来指定注释行的开头字符。
- delimiter:字符串类型的分隔符,用来分割文本中每行的字段。
- converters:字典或者 callable。用来将所有列的字符转换成期望的数据类型。如果是字典格式,可以针对特定的列进行转换,譬如:
{0: lambda s: float(s.strip() or 0)}会将第 0 列的字段转换成数字。- skiprows:跳过前几行数据,默认 0
- usecols:数字或者序列。用来指示读取哪几列数据。譬如:
(1, 3, 5)会读取第 2,4,6列数据。- unpack:如果是 True,会主动解包。譬如:
x, y, z = loadtxt(...)- ndmin:设置最小维度
- encoding:设置编码格式
- max_rows:在
skiprows后,要读取多少行文件。默认读取全部文件
假设现有 data.txt :
name age
wang 20
zhang 23
li 32
我们可以这样读取它:
import numpy as np
dt = np.dtype([("name", "S10"), ("age", "i1")])
data = np.loadtxt('data.txt', dtype=dt, delimiter=' ', skiprows=1)
print(data) # [(b'wang', 20) (b'zhang', 23) (b'li', 32)]
numpy.save / load
numpy.save() 函数将数组保存到以 .npy 为扩展名的文件中。
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
- file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上。
- arr: 要保存的数组
- allow_pickle: 可选,布尔值,允许使用 Python pickles 保存对象数组,Python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化。
- fix_imports: 可选,为了方便 Pyhton2 中读取 Python3 保存的数据。
import numpy as np
a = np.array([1,2,3,4,5])
# 保存到 outfile.npy 文件上
np.save('outfile.npy',a)
# 保存到 outfile2.npy 文件上,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上
np.save('outfile2',a)
使用 load 加载文件:
import numpy as np
b = np.load('outfile.npy')
print (b)
np.savez
numpy.savez() 函数将多个数组保存到以 npz 为扩展名的文件中。
numpy.savez(file, *args, **kwds)
- file:要保存的文件,扩展名为 .npz,如果文件路径末尾没有扩展名 .npz,该扩展名会被自动加上。
- args: 要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为 arr_0, arr_1, … 。
- kwds: 要保存的数组使用关键字名称。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = np.arange(0, 1.0, 0.1)
c = np.sin(b)
# c 使用了关键字参数 sin_array
np.savez("test.npz", a, b, sin_array = c)
r = np.load("test.npz")
print(r.files) # 查看各个数组名称
print(r["arr_0"]) # 数组 a
print(r["arr_1"]) # 数组 b
print(r["sin_array"]) # 数组 c,使用关键字:sin_array
随机函数
| 函数 | 功能 | 参数 |
|---|---|---|
| rand(int1, [int2, int3, ...]) | 生成 [0,1) 的随机数 | (2,3)代表生成2行3列的 0-1的随机数 |
| randn(int1, [int2, ...]) | 生成标准正态分布的随机数 | 同上 |
| randint(low, [hight, size, dtype]) | 随机整数 | |
| sample(size) | 生成 [0,1) 的随机数 |
np.random.rand
会按照你给定的维度,创建 [0, 1) 之间的随机数,包含 0,不包含1
x = np.random.rand(4, 2, 5)
print(x)
np.random.randn
按照给定的维度,创建符合正态分布的值。
用法同 np.random.rand
np.random.randint
按照给定的取值范围(从 low 到 high,包含 low,不包含 high)和数组维度,创建整数
randint(low, high=None, size=None, dtype=None)
- low:生成的数的最小值
- high:生成的数的最大值,如果 high 是None,则取值范围是 [0, low)
- size:数组的长度(多少个元素),默认是 None,代表只返回一个数据。
- dtype:数据类型
x = np.random.randint(2, 10, 8) # 生成8个从2到10之间的整数(包含2,不包含10)
print(x)
np.random.sample
根据给定的 size,返回随机的浮点数:[0.0, 1.0)
x = np.random.sample(5)
print(x)
np.random.normal
自定义一个正态分布
# 生成一个 均值为2.5,标准差为2的,长度为5正态分布
x = np.random.normal(2.5, 2, 5)
print(x)
随机种子
当使用了相同的种子以后,总会生成相同的随机数:
np.random.seed(1)
x = np.random.randn(1, 2, 2)
print(x)
你可以多次运行上面的代码,会发现每次运行,产生的随机数是一样的
字符串函数
| 函数 | 描述 |
|---|---|
add() |
对两个数组的逐个字符串元素进行连接 |
| multiply() | 返回按元素多重连接后的字符串 |
center() |
居中字符串 |
capitalize() |
将字符串第一个字母转换为大写 |
title() |
将字符串的每个单词的第一个字母转换为大写 |
lower() |
数组元素转换为小写 |
upper() |
数组元素转换为大写 |
split() |
指定分隔符对字符串进行分割,并返回数组列表 |
splitlines() |
返回元素中的行列表,以换行符分割 |
strip() |
移除元素开头或者结尾处的特定字符 |
join() |
通过指定分隔符来连接数组中的元素 |
replace() |
使用新字符串替换字符串中的所有子字符串 |
decode() |
数组元素依次调用str.decode |
encode() |
数组元素依次调用str.encode |
add
import numpy as np
a = np.array([["AAA", "BBB"]])
b = np.array([["aaa", 'bbb']])
print(np.char.add(a,b)) # [['AAAaaa' 'BBBbbb']]
multiply
import numpy as np
a = np.array([["AAA", "BBB"]])
b = np.array([["aaa", 'bbb']])
print(np.char.multiply(a, 3)) # [['AAAAAAAAA' 'BBBBBBBBB']]
center
a = np.array([["AAA", "BBB"]])
b = np.array([["aaa", 'bbb']])
print(np.char.center(a, 20, fillchar='*'))
# [['********AAA*********' '********BBB*********']]
capitalize / title
a = np.array([["AAA", "BBB"]])
b = np.array([["aaa", 'bbb']])
print(np.char.capitalize(a)) # [['Aaa' 'Bbb']]
print(np.char.title(a)) # [['Aaa' 'Bbb']]
lower / upper
a = np.array([["AAA", "BBB"]])
b = np.array([["aaa", 'bbb']])
print(np.char.lower(a)) # [['aaa' 'bbb']]
print(np.char.upper(b)) # [['AAA' 'BBB']]
split / splitlines
print(np.char.split("www.baidu.com", sep='.', maxsplit=1))
print(np.char.splitlines("www.baidu.com\nwww.google.com",))
"""
['www', 'baidu.com']
['www.baidu.com', 'www.google.com']
"""
strip
strip 用来移除头尾处的字符。不指定移除的字符,则移除空白字符。
a = np.array([["AAA", "ABCC"]])
b = np.array([["aaa", 'bbb']])
print(np.char.strip(a, 'BC')) # 从字符串的头尾移除 B,C
join
a = np.array([["AAA", "ABC"]])
b = np.array([["aaa", 'bbb']])
print(np.char.join(['.', '-'], a)) # [['A.A.A' 'A-B-C']]
replace
replace(array, old_str, new_str, count=None)
将字符串替换。count 用来设置替换几次
a = np.array([["AAA", "ABC"]])
b = np.array([["aaa", 'bbb']])
print(np.char.replace(a, 'A', 'a', count=2)) # [['aaA' 'aBC']]
encode / decode
a = np.array([["AAA", "ABC"]])
c = np.char.encode(a, 'utf-8')
d = np.char.decode(c, 'utf-8')
print(c)
print(d)
向量和矩阵
向量内积 dot
a⋅b=∑iaibi
即 a*b = a[0] * b[0] + a[1] * b[1] + a[2] * b[2] + ...
In [122]: a = np.array([1,2,3])
In [123]: b = np.array([1,3,5])
In [124]: a.dot(b)
Out[124]: 22
其他函数
any, all
any 指当序列至少 存在一个 True 或非零元素时返回 True ,否则返回 False all 指当序列元素 全为 True 或非零元素时返回 True ,否则返回 False
In [86]: a = np.array([0,1])
In [87]: a.any()
Out[87]: True
In [88]: a.all()
Out[88]: False
cumprod, cumsum, diff
cumprod, cumsum 分别表示累乘和累加函数,返回同长度的数组, diff 表示和前一个元素做差,由于第一个元素为缺失值,因此在默认参数情况下,返回长度是原数组减1
In [89]: a = np.array([1,2,3])
In [90]: a.cumprod()
Out[90]: array([1, 2, 6], dtype=int32)
In [91]: a.cumsum()
Out[91]: array([1, 3, 6], dtype=int32)
In [92]: np.diff(a)
Out[92]: array([1, 1])


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构