【面试题】Java OOP 面试题
1.short s1 = 1; s1=s1+1; 有错吗? short s1 = 1; s1+=1; 有错吗?
首先我们需要了解大的数据类型向小的数据类型转换需要强制类型转换
第一条语句中 s1=s1+1; 中的 "1" 是 int 类型,而s1 是 short类型,所以 s1+1 会自动转换为int类型,把s1+1 赋值给 s1,是把一个int类型的数赋值给一个short类型的数,需要强制类型转换,所以,这条语句是错误的,应该为:s1 = (short) (s1+1);
第二条语句s1+=1; 是正确的,因为这条语句等价为 s1 = (short) (s1+1); 其中包含了强制类型转换
2.重载和重写的区别
重载:指的是在同一个类中,方法名相同,但参数不同(参数的类型、个数、顺序),重载的返回值和访问修饰符可以相同也可以不同。
重写:子类继承父类后,重写父类的方法,方法名和参数必须和父类的相同。重写返回值范围必须小于等于父类,抛出的异常必须小于等于父类,访问修饰符要大于等于父类。
3.数组实例化有几种方式
数组实例化有三种方式:
-
静态实例化:在数组创建的时候就给数组中的元素赋值
int[] num = {1,2,3}; int[] num2 = new int[]{4,5,6} -
动态实例化:实例化数组时,只指定数组的长度,在后面的代码中指定元素的值
int[] num = new int[3]; num[0] = 0; num[1] = 1; -
默认初始化:数组是引用类型,它的元素相当于类的实例变量,因此数组已经分配空间,其中的每个元素也按照实例变量的方式被隐式初始化,也就是在声明并且创建了数组后,并未给其赋值,那么它的每个元素的值都是默认值,如果是 int 类型,默认值就是0,char类型,默认值就是null
4.Java中各种数据的默认值
就像上题中所说,初始化时不给数组赋值,每个元素的值就是它的类型的默认值,下面看一下java中各种类型的默认值
八大基本类型中
-
整数类型 byte、short、int、long 默认值都是 0
-
浮点类型 float、double 默认值 是 0.0
-
布尔值 boolean 默认值是 false
-
字符类型 char 默认值是 "" (空)
除了八大基本类型之外,都是 引用类型,默认值为 null
5.Object类常用方法有哪些
Object类叫做基类或超类,所有的类都直接或间接继承了Object,它是所有类的父类,所以所有的类都具备Object类的方法。
Object类可以作为参数和返回值类型
常用方法:
-
getClass() 返回实际的对象类型,通常用于判断两个对象是否是同一类型
-
hashCode() 返回对象的哈希值,相同的对象哈希值相同
-
toString() 返回该对象的字符串表示,不重写的话,返回的是类名+哈希值 ,一般我们会根据需要重写toString()
-
equals() 默认实现为(this==obj) ,即比较两个对象的地址是否相同,从而比较两个对象的引用是否相同,可以进行重写,来比较对象的属性是否相同
-
finalize() 当对象为垃圾对象时,由JVM 自动调用该方法,标记垃圾对象并回收
6.java中是值传递还是引用传递
值传递:是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数

代码在内存中的执行流程:
1、首先加载main方法;

2、接下来int number = 100;

3、输出调用前的number,结果为100;

4、调用change方法;

5、在change方法中传参,传的是number,值为100;

6、在change方法中对其number修改其值为200;

虽然方法中的number的确改为200,但是main方法中的number的值是没有改变的。
7、change方法调用完毕,然后就从栈内存消失;

8、接下来输出number,而number在main方法中的值还是100;

9、main方法结束,从栈内存中消失

引用传递:在调用函数时,将实际参数的地址传递到函数中,那么在函数中对参数进行修改,将会影响到实际参数

代码在内存中的执行流程:
1、加载main方法;

2、定义int类型的数组,=左边的加载到栈内存,=右边的加载到堆内存,堆内存中地址001给栈内存;

3、 输入arr[1],在栈内存中通过001地址找到堆内存中001,再通过索引找到arr[1]的值为20,在输出其值为20;

4、调用change方法,change方法加载到占内存,再将形参int[ ] arr加载到change方法中,形参int[ ] arr是有main方法中传递过来的,传递的是地址001,再去修改arr[1]的值,通过在栈中的地址001,找到堆内存中的地址001,通过索引找到其对应的值,并修改其值为200

5、change方法调用完毕,在栈内存中消失;

6、接下来输出调用change方法后的值,这时值已经改变,输出的值为200;

7、main方法结束,从栈内存中消失;

从上面的例子可以看出,当传递的值是基本类型时是值传递,传递的值是引用类型时是引用传递,但结果真的是这样吗?
在分析这个问题前,我们先了解一下在变量在jvm中是怎么存储的
首先看基本类型,这个很简单,变量在栈中直接存的是值,传到change()方法的是这个变量的拷贝,因此对拷贝的变量修改不会影响原变量的值。
接着看引用类型,变量在栈中存储的是引用地址,这个地址指向堆中具体的值,如下图:
当调用change()方法传入变量时,也是拷贝变量,但是这里的拷贝只是栈中的引用地址,并不会拷贝堆中的数据,因此会变成下图这样:
虽然变量是拷贝,但是指向的地址是同一个,因此对变量中的数据修改时,还是会影响到原来真实的变量,但是,如果我们修改的是变量在栈中的地址,则不会影响原变量,例如下面这段代码:
public void test() {
User user = new User();
user.setAge(18);
change(user);
System.out.println("年龄:" + user.getAge());
}
private void change(User user) {
user = new User(); //修改了 user 在栈中的地址
user.setAge(19);
}
// 输出
年龄:18这种是修改变量在栈中的地址,则不会影响原变量。
所以java是值传递,当传的是基本类型时,传的是值的拷贝,当传的是引用类型时,传的是引用地址的拷贝,但拷贝的地址和真实的地址指向的都是同一个真实数据,所以可以修改原变量的值,当传的是String 类型时,虽然传的也是拷贝地址,但String的值不能被修改,所以无法修改原String变量的值
本题参考于:
7.形参与实参的区别
形参:形参全称是“形式参数”,又因为它不是实际存在的变量,所以又称为虚拟变量,形参是在定义函数时使用的参数,目的是用来接收调用该函数时传入的参数。
实参:全称是“实际参数”,在调用有参函数时,函数名后面的括号中就是实参,实参必须有明确的值,可以是变量、常量、表达式、函数,需要注意的是实参的个数和类型必须和形参一一对应,以便将值传给形参,在调用函数的过程中形参和实参发生的数据传递,常称为“虚实结合”。
区别:
-
本质不同:形参本质只是一个名字,不占用内存空间。实参是一个变量,占用内存空间
-
作用域不同:形参的作用域是整个函数,离开这个函数形参则无法使用。实参出现在主函数中,一进入被调函数,实参便无法使用,这时实参将值传递给了形参。
-
声明周期不同:形参在函数被调用时才分配内存单元(栈空间),在调用结束后立刻释放内存单元
如果形参和实参不是指针类型,在运行函数时,它们是不同的变量,在内存中处于不同的位置,形参是将实参的值复制一份,所以在函数中修改形参并不会改变实参的值
如果函数的参数是指针类型,在调用函数时,传入的是实参的地址,在函数内部使用的是实参的地址,所以修改的也是实参的值。 即上题中的 引用传递
8.构造方法能否重写?能否重载?
构造方法不能够重写,但是能够重载
构造方法分为两种:一类是无参构造,一类是有参构造
在一个类中,可以有多个构造方法,但参数不同(属性的个数),即重载
如果一个类没有手动定义构造方法,在java被编译时,会自动写入一个无参构造,但如果手动定义了有参构造,那么必须手动定义无参构造。
在继承关系中,父类的构造方法不能被子类重写。在子类的构造方法中,会自动写入super()方法,这个super() 就代表了父类的构造方法,如果显式定义super(),必须放在子类构造方法的第一行
9.内部类和静态内部类的区别
内部类:内部类就是定义在一个类内部的类
静态内部类:用static修饰的内部类
区别:
-
普通内部类可以访问到外部类的所有属性和方法(包括私有属性和方法),静态内部类不能访问外部类的非静态成员,只能访问静态成员。
-
创建方式不同:普通内部类在创建时,必须先创建外部类,然后通过外部类来创建内部类。静态内部类可以直接创建
public class InnerClass { public class IninnerClass { } public static class IninnerstaticClass{ } } class OutClass{ public static void main(String[] args) { //普通内部类 InnerClass innerClass = new InnerClass(); InnerClass.IninnerClass ininnerClass = innerClass.new IninnerClass(); //静态内部类 InnerClass.IninnerstaticClass ininnerstaticClass = new InnerClass.IninnerstaticClass(); } } -
普通内部类不能有静态的成员,静态内部类可以有静态成员
-
普通内部类持有对外部类的引用,静态内部类没有外部类的引用。
什么是对外部类的引用呢?
public class OuterClass { // 普通成员变量 private String outField = "out field"; // 静态成员变量 private static String outStaticField = "out static field"; // 普通内部类 public class InnerClassA{ } // 静态内部类 public static class InnerStaticClassB{ } }我们可以通过反编译这个类,来查看
编译后,出现了了三个class文件,我们对这三个class文件反编译,如下
public class OuterClass { private String outField = "out field"; private static String outStaticField = "out static field"; }import com.yy.demo15_innerClass.OuterClass; public class OuterClass$InnerClassA { // $FF: synthetic field final OuterClass this$0; public OuterClass$InnerClassA(OuterClass this$0) { this.this$0 = this$0; } }package com.yy.demo15_innerClass; public class OuterClass$InnerStaticClassB { }我们可以发现,反编译之后的普通内部类的构造方法的参数是外部类对象,而静态内部类却没有引用外部类对象。
因为普通内部类里面有外部类的引用,所以只要内部类一直运行,外部类就不会被回收。
10.static关键字有什么作用
static是java的一个关键字,用来修饰成员变量、成员方法、构造静态代码块、实现静态内部类、静态导包等。
-
修饰成员变量
用static修饰的变量叫做静态变量或类变量,因为它是属于类的,只要静态变量所在的类被加载,这个静态变量就被分配了空间,可以直接用 类.变量 来调用。
而实例变量与静态变量不同,它是属于对象的,只有对象被创建,实例变量才会被分配空间,并且使用时,必须先创建对象,然后通过对象去调用。
下面的例子展示了静态变量在内存中的构造:
public class Person { private String name; private Integer age; public Person(String name, Integer age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; }首先我们创建了一个实体类,它有两个成员变量都是普通的实例变量,没有用static修饰,然后我们创建通过构造方法创建两个对象
Person p1 = new Person("Tom",21); Person p2 = new Person("Marry",20); System.out.println(p1.toString());//Person{name='Tom', age=21} System.out.println(p2.toString());//Person{name='Marry', age=20}这两个对象在内存中的存储结构如下:
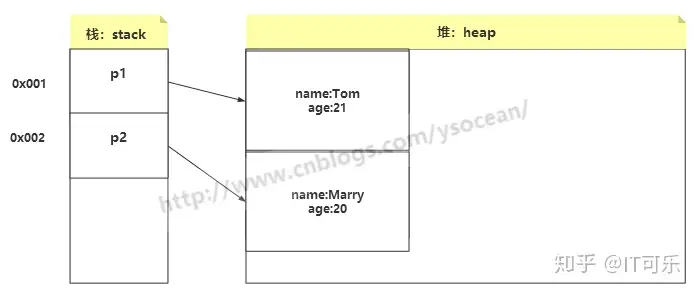
从上图可知,我们创建的两个对象都是存放在堆中,但是它们的引用地址存放在栈中,并且这两个对象相互独立,我们修改其中任意一个对象的属性,另一个对象的属性不会发生改变。
下面我们将属性age 改为static修饰,即静态变量
private static Integer age;然后再去创建对象
Person p1 = new Person("Tom",21); Person p2 = new Person("Marry",20); System.out.println(p1.toString());//Person{name='Tom', age=20} System.out.println(p2.toString());//Person{name='Marry', age=20}我们会发现对象p1的age也变成了20,下面是在内存中的存储现象:
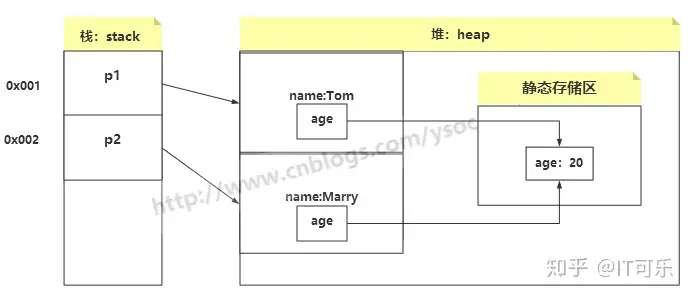
原因是jvm会在堆中开辟一块空间,专门用来存放静态变量,称为静态存储区,所以无论我们创建几个对象,用static修饰的成员变量只有一份存储在静态存储区中,该静态变量的值以最后一次修改的值为准,也就解释了为什么两个对象的age都是20。
引申:在JDK1.8之前,静态存储区是存放在方法区中的,而方法区不属于堆,在JDK1.8之后,才取消了方法区,并且将静态存储区放在堆中
从上面的例子我们可以看出,静态变量只有一个,被所有对象所共享,而实例变量是每个对象都各自拥有的。
static不能修饰局部变量,因为局部变量是定义在方法中的,无论是不是静态方法,都不能修饰局部变量。
-
修饰成员方法
与静态变量相同,static修饰的成员方法叫做静态方法,是在类加载的时候,就创建了,所以在静态方法中,不能使用 this和super关键字,不能调用非静态变量和非静态方法,原因就是在静态方法被创建时,还没有创建对象,非静态的变量和方法只能通过创建对象去调用,this和super也是如此。
-
静态代码块
用static来修饰的代码块叫做静态代码块,静态代码块不能被放在方法中,jvm在加载类时就执行了静态代码块,并且在构造方法之前,并且只执行一次。
静态代码块用来初始化类
-
静态内部类
用static修饰的内部类,详见第9题
-
静态导包
当我们想要使用Arrays工具类中的方法时,需要先将Arrays类导入,然后再调用它的方法
import java.util.Arrays; ... int[] arrays = {23,54,6557,4322,67}; Arrays.sort(arrays);我们可以使用静态导包,import static java.util.Arrays.*; 然后就可以省略包名去调用Arrays下的所有方法,但静态导包并不会提升性能,只是降低了程序员的代码量。
-
用于单例模式
单例模式即只有一个实例,将类的构造方法设置为私有,然后再共有的方法里面实例化对象,把这个方法设置为static
class Singleton{ private static Singleton instance=null; private Singleton(){} public static Singleton getInstance(){ if(instance==null){ instance=new Singleton(); } return instance; } } -
与final关键字搭配
再java中,static常与final关键字搭配使用,用来修饰成员变量,类似于c/c++中的全局变量,对于用static final修饰的变量只表示为一个值,不可修改,并且通过类名可以直接访问,我们可以把经常用到的不变的一个值设置到一个类中,并且用static final 来修饰。
用 static final修饰的方法不可被重写和覆盖。
11.final在Java中的作用,有哪些用法
final的含义是最终的,final可以用来修饰类、方法、变量
-
修饰类
用final修饰的类,不可被继承,如String、System类等,
类中的方法都被隐式地修饰为final方法
-
修饰方法
用final修饰的方法,不能被重写,但是可以重载
-
修饰变量
-
修饰成员变量
如果final修饰的是类变量,只能在静态代码块初始化或声明该类变量时初始化
final static int a; //类变量可以声明的时候初始化 static{ a = 10; //类变量也可以在静态代码块中初始化 }如果final修饰的是成员变量,可以在声明该变量、静态代码块、构造方法中进行初始化
final String name; //成员变量可以在声明的时候初始化 // { // name = "李四"; //成员变量也可以在非静态代码块中初始化 // } public Demo02(String name) { this.name = name; //也可以在构造方法中初始化 } -
修饰局部变量
由于系统不会给局部变量初始化(如果没有初始化,就给它默认值),所以使用final修饰局部变量时,可以在定义时指定默认值(后边不可更改),也可以在后面的代码中给它指定默认值,但是只能指定一次
public static void main(String[] args) { final int aa; //局部变量可以在声明时初始化 aa = 0; //也可以选择不在声明时初始化,而在后面的代码中初始化 //aa = 1; //但是只能初始化一次,第二次就会报错 } -
修饰基本数据类型和引用数据类型
如果是修饰基本数据类型的变量,其数值在初始化后就不可改变
如果是修饰引用数据类型,即对象,在初始化后不能使其在指向别的对象,但是可以修改它的值
final Person p1 = new Person(); p1.setAge(10); //p1 = new Person(); //会报错 final int[] arr = {12,23,45,89}; arr[2] = 54; //arr = null; //会报错
-
在java8之后,如果你没有使用final修饰局部变量,那么在编译时会自动使用final修饰局部变量
如下例:这是一个局部内部类,我们调用了局部变量a和b,但是没有用final修饰他们
class TestFinal{
public static void main(String[] args) {
int b = 10;
testFinals(b);
}
public static void testFinals(int b) {
int a = 0;
new Person(){
public void test(){
System.out.println(a);
System.out.println(b);
}
}.test();
}
}下面是对class文件反编译后
class TestFinal {
TestFinal() {
}
public static void main(String[] args) {
int b = 10;
testFinals(b);
}
public static void testFinals(final int b) {
final int a = 0;
(new Person() {
public void test() {
System.out.println(a);
System.out.println(b);
}
}).test();
}
}我们可以发现,局部变量a和b都使用了final修饰
为什么局部内部类和匿名内部类只能访问局部final变量?
也就是局部内部类和匿名内部类想要访问局部变量,那么这个局部变量必须用final修饰
首先需要注意的是:内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就随着方法的执行完毕就销毁,而是不被使用后才被销毁
这里就会产生一个问题:外部类执行完毕,它的局部变量会随之被销毁,但内部类没有执行完毕,它还要使用外部类的局部变量,这时就会产生一个矛盾,内部类调用了一个不存在的局部变量
为了解决这一问题,JVM提供了一种机制,将外部类的局部变量复制一份作为内部类的成员变量,这样当外部类的局部变量被销毁后,内部类依然可以使用局部变量的“copy”,但是必须要保证这个“copy”的值和局部变量的值保持一致,所以把局部变量用final来修饰,保证内部类不能去修改这个“copy”,从而保证了一致性。
12.String str="aaa" 与 String str =new String("aaa")一样吗
首先给出答案,是不一样的
这是两种创建字符串的方式:
-
String str = "aaa"; -- 字面量的方式
-
String str = new String("aaa") -- 构建对象的方式
在了解这两种方式之前,首先我们需要先知道 字符串常量池
在JVM中,为了减少字符串对象的重复创建,维护了一块特殊的内存空间,这块内存空间就被称为字符串常量池。
在JDK1.6及之前,字符串常量池存放在方法区中(Perm区),在JDK1.7之后,就从方法区移除,改放到堆中(Java Heap),原因是Perm区大小只有4M,太小,JDK1.8直接废弃了Perm区,取而代之的是一个叫元空间(Metaspace)的区域。
现在我们来看一下这两种创建字符串的方式
-
字面量的方式创建 String str = "aaa";
首先JVM会在字符串常量池中找是否有 "aaa" 字面量的引用,如果没有,就在堆中创建一个对象,在常量池中存放这个对象的引用。然后返回这个对象的地址给str
如果再来一个 String str2 = "aaa"; JVM在常量池中找"aaa"字面量的引用,发现找到了,然后就返回这个引用给str2,所以 str和str2指向同一个对象
工作原理:
当一个.java文件被编译成.class文件时,和所有的常量一样,每个字符串字面量都通过特殊的方式被记录下来。当一个.class文件被加载时,JVM在.class文件寻找字符串字面量,当找到一个时,JVM会检查是否有相同的字符串在常量池中存放了堆中引用,如果找不到,就会在堆中创建一个对象,然后将他的引用存放在常量池中的一个常量表中,一旦一个字符串对象的引用在常量池中被创建,这个字符串在程序中的所有字面量引用都会被常量池中已经存在的那个引用替代。
-
new一个对象 String str = new String("aaa");
JVM 会创建两个对象,一个是 new 出来的对象,一个是"aaa"在堆中的对象

intern()方法
对于使用 new 来创建的对象,如果想要将这个对象的引用加到字符串常量池中,就可以用intern()
这个方法的执行:首先在字符串常量池中查找是否有这个对象的引用,如果有就什么都不做,没有就将这个引用加到字符串常量池中。
下面看两个例子:
例1:
String str = new String("a") + new String("bc");
str.intern();
String str2 = "abc";
System.out.println(str==str2);打印的结果是 true,下面是图示
-
String str = new String("a") + new String("bc");

第一步,有三个对象在堆中被创建,分别是“abc”、“a“、”bc“
-
str.intern();

在常量池中找有没有 ”abc“的引用?结果是没有,所以把 ”abc“的引用加到常量池中
-
String str2 = "abc";

在常量池中找有没有 ”abc“ 的引用,结果发现有,那么就将”abc“的引用返回给str2,也就是str
所以str 和 str2的指向是相同的,所以返回值为true
例2:
String str1 = new String("abc");
str1.intern();
String str2 = "abc";
System.out.println(str1==str2);返回的结果是 false,下面是图示
-
String str1 = new String("abc");

有两个对象被创建,new 出来的对象,一个是字面量的对象
-
str1.intern();
在常量池中找是否有“abc”的引用?结果是有,那么什么都不做
-
String str2 = "abc";

在常量池中找有没有“abc”的引用,结果是有,就把这个引用给str2
从过程看出,str1 和 str2 的指向是不相同的,所以返回的结果是false
网上对于字符串常量池的说法,基本分为两类,一类是常量池中既存放引用,又存放对象,另一类是常量池中只存放引用,该文是根据 常量池中只存在引用来分析的,固有不妥,望指正。
参考博客:
13.讲下Java中的Math类有哪些常用方法
Math类是在java.long包下,这个类里面有一些static方法,可以直接使用类名调用,用来进行一些数学计算。
-
Math.abs(a); 获得a的绝对值 参数可以是int、long、float、double,返回值与传入的参数相同
int a = -20; Math.abs(a); -
Math.max(a,b)、Math.min(a,b) 返回a、b之间的最大值最小值
long a = -2147483649l; long b = -2147483650l; System.out.println("最大值:"+Math.max(a,b)); System.out.println("最小值:"+Math.min(a,b)); -
Math.random() 产生0-1之间的随机数,包括0不包括1
如果我们想要生成[min,max) 之间的随机数,公式为:Math.random()*(max-min)+min
生成[min,max] 之间的随机数,公式为:Math.random()*(max-min+1)+min
int num = (int) (Math.random()*(23-22)+22); int num1 = (int) (Math.random()*(23-22+1)+22); System.out.println(num); System.out.println(num1); -
Math.pow(a,b) 返回 a的 b次方,a和b都是double类型,返回值也是double类型
double pow = Math.pow(2,16); System.out.println(pow); -
Math.sqrt(a) 获得a的平方根
double sqrt = Math.sqrt(9); System.out.println(sqrt);如果参数是负数,会返回NAN
-
Math.cbrt(a) 获得a的立方根
double cbrt = Math.cbrt(27); System.out.println(cbrt); -
Math.ceil(a) 获得大于等于a的最小整数
double ceil = Math.ceil(25.6); System.out.println(ceil); -
Math.floor(a) 获得小于等于a的最大整数
double floor = Math.floor(25.6); System.out.println(floor); -
Math.rint(a) 四舍五入,在小数位为0.5时,返回的结果是偶数
double rint = Math.rint(12.5); System.out.println(rint); //12 double rint1 = Math.rint(11.5); System.out.println(rint1); //12 -
Math.rount(a) 真正意义上的四舍五入
long round = Math.round(16.5); System.out.println(round); int round1 = Math.round(16.5f);参数为float类型时,返回值是int,参数是double,返回值是long
14.char类型能不能转成int类型?能不能转成String类型?能不能转成double类型?
char是基本数据类型之一,用于存放单个字符。
char类型可以转成int类型,是由小类型转换为大类型,是自动转换,不需要强制类型转换
转换后的值是字符对应的ACSII 码的值
char a = 'w';
int num = a;
System.out.println(num); //119char也可以转换为double,同样也是隐式转换
char转换为String类型不能够隐式转换
将char类型转换为String类型大致有4种方法
-
String str = String.valueOf('w');
-
String str = Character.toString('w');
-
String str = "str" + 'w';
-
String str = new String(new char[]{'w'});
一般使用第一种,效率最高
15.什么是拆装箱
在了解拆装箱之前,我们需要知道什么是包装类?
包装类:基本数据类型所对应的引用数据类型就是包装类
基本数据类型都存在栈中,而引用数据类型是在堆中存放,它们的地址存放在栈中
包装类和其他引用数据类型相同 返回值是null
八大基本数据类型都对应了其包装类,如下图:

在了解了包装类后,我们再来看装箱和拆箱
-
装箱:把基本数据类型转换成引用类型
有两种方式:
-
通过包装类的构造方法
int num = 100; Integer integer = new Integer(num); -
通过valueOf() 方法
int num = 100; Integer integer1 = Integer.valueOf(num);
-
-
拆箱:把引用类型转换为基本数据类型
通过xxxValue() 方法
int num = 100; Integer integer1 = Integer.valueOf(num); int i = integer1.intValue();
JDK1.5之后,提供了自动装箱、拆箱
int num = 100;
Integer integer = num; //自动装箱
Integer integer1 = Integer.valueOf(num);
int i = integer1; //自动拆箱虽然不用我们手动去做装箱和拆箱的工作,但是在class文件中,依旧是使用valueOf() 方法实现装箱
装箱和拆箱的作用:
在某些场景下,一些方法的参数是Object类型,但是我们需要向这个方法传入一个值,这时我们就需要装箱
在泛型中,基本数据类型不能做泛型参数,我们要使用它的包装类来做泛型参数
16.java中的包装类都是哪些
见第15题
17.一个Java类中包含哪些内容
-
属性 静态和非静态
-
方法 静态非静态
-
构造方法
-
内部类
-
块 静态代码块、普通代码块
18.针对浮点型数据运算出现的误差,你怎么解决
首先我们来看一下,浮点型运算的误差例子
double a = 1.0;
double b = 0.9;
System.out.println(a-b);在我们的认知里,结果应该为0.1,但实际结果如下

造成这种结果的原因就是 double/float 采用的是近似值的存储方式,意思是我们存的是1.0,实际上在内存中存的是0.999999999999999,所以计算结果会出现一定的误差。
如果我们想要计算更为精确的结果,就不能使用浮点型去计算,而是使用 BigDecimal类
BigDecimal 是精确存储,你存1.0,它在内存中就存1.0
现在我们用这个类,来解决上面的问题
首先需要new 两个BigDecimal对象,传入的参数必须是字符串,因为传入浮点型依然是近似值存储
然后减数对象调用 subtract() 方法,参数是被减数,得到的结果依旧是 BigDecimal对象,可以直接输出
BigDecimal bigDecimal1 = new BigDecimal("1.0");
BigDecimal bigDecimal2 = new BigDecimal("0.9");
BigDecimal subtract = bigDecimal1.subtract(bigDecimal2);
System.out.println(subtract);BigDecimal 的其他方法:add() 加法 multiply() 乘法 divide() 除法
在除法这里还需要注意,当遇到除不尽的情况 如 10/3,会报错
这时我们要用divide() 的重载方法 divide(BigDecimal d2, int scale, int roundingMode)
int scale 表示保留几位小数
int roundingMode 表示保留的方式,这里BigDecimal提供了几个常量,表示四舍五入等
public final static int ROUND_UP = 0;
public final static int ROUND_DOWN = 1;
public final static int ROUND_CEILING = 2;
public final static int ROUND_FLOOR = 3;
public final static int ROUND_HALF_UP = 4;
public final static int ROUND_HALF_DOWN = 5;
public final static int ROUND_HALF_EVEN = 6;
public final static int ROUND_UNNECESSARY = 7;
19.面向对象的特征有哪些
-
封装
-
继承
-
多态
为什么这三大特征可以帮助我们更好地写代码?
封装增加了代码的复用性,封装好的东西可以重复使用
继承增加了代码的复用性
多态增加了代码地可移植性、健壮性、灵活性
20.访问修饰符 public、private、protected以及不写(默认)时的区别
-
public(公有的):对所有包中的所有类可见
使用对象:类、接口、变量和方法
-
protected(受保护的):对同一个包内的所有类包括子类可见
在其他包的子类不能访问父类的protected修饰的方法或属性
使用对象:变量和方法
-
default(默认):对同一个包内的类可见,如果子类和父类不在同一个包下,那么父类的default的属性和方法是不能被子类访问的,如果在一个包下,是可以被访问的
使用对象:类、接口、方法和变量
-
private(私有的):不能被其他类访问
使用对象:方法和变量
| 修饰符 | 当前类 | 同一个包 | 同包子类 | 不同包子类 | 不同包 |
|---|---|---|---|---|---|
| public | √ | √ | √ | √ | √ |
| protected | √ | √ | √ | × | × |
| default | √ | √ | √ | × | × |
| private | × | × | × | × | × |
21.接口有什么特点
接口是一系列方法的声明,是一些方法特征的集合。接口是对行为的抽象化,只有方法的特征,没有方法的实现。
-
使用interface 来声明接口
-
在接口中的方法默认是 public abstract
-
在JDK1.8之后,接口中可以有默认方法 即使用 default定义的方法
-
接口中的属性默认是 public static final 都是常量
-
接口不能实例化,因为接口没有构造方法
-
类 可以通过 implement 来实现接口
-
类实现了接口,必须重写结构中的所有抽象方法
-
一个类可以实现多个接口
-
类既可以实现接口,也可以继承父类,但是继承要在实现接口前面
-
接口和实现类的关系就和父类和子类的关系一样
-
可以通过多态,实现类的实例指向接口的引用
为什么需要接口?
在Java中不允许多继承,所以如果要实现多个类的方法,可以通过实现多个接口
提高程序的复用率、增加程序的可维护性、可扩展性
有利于代码的规范
22.抽象类和接口的区别
什么是抽象类?
抽象类是使用abstract来修饰的类,抽象方法是用abstract修的方法,抽象方法只有定义没有实现,抽象类中不一定含有抽象方法,但抽象方法一定存在于抽象类中。
抽象类中可以有方法的实现也可以有抽象方法
抽象类不能被实例化,只能靠子类去实现
抽象类在编译后,自动定义了构造方法,为了使子类的构造器中的 super() 能够执行,还有一个作用是初始化抽象类内部声明的通用变量。
抽象类的使用场景?
当一个类既被复用,又用于多态,可以把这个类变为抽象类,比如:
有一个Dog类,它有睡觉的行为,同时也有一个Cat类,也有睡觉的行为,现在我们突然要加一个业务,Dog和Cat都有一个吃饭的行为,但Dog吃的是骨头,Cat吃的是鱼,这样既有复用(睡觉),又又多态(Dog吃骨头,Cat吃鱼),这时优先考虑抽象类。
抽象类中可以写 睡觉方法的实现,还有吃饭的抽象方法
子类中可以直接调用睡觉方法,然后重写吃饭方法就好了
使用接口同样可以实现,但是如果使用接口,在子类中必须重写所有的方法,会造成代码的重复
抽象类和接口的异同?
相同点:
-
代表系统的抽象层
-
都不能被实例化
-
都包含抽象方法
不同点:
-
抽象类可以提供某些方法的具体实现,而接口不可以
-
抽象类的子类只能继承一个抽象类,但可以实现多个接口
-
抽象类中的抽象方法可以使用public、protected、default等,接口中的抽象方法只能是public
23.HashCode的作用
什么是HashCode?
hashCode() 方法返回对象的哈希码值,根据一定的规则将与对象相关的信息(比如对象的存储地址、对象的字段等)映射成一个数值,这个数值称为散列值或哈希值
作用:
Java中的集合有两类,一类是List,一类是Set,前者集合中的元素有序并且可以重复,后者元素无序不可重复。使用equlas() 方法来保证元素不可重复,每增加一个元素就要检查一次,如果集合中已经有10000个元素,那么当第10001个元素加入集合时,需要调用10000次equals()方法,效率很低,所以JAVA采用了哈希表的原理
哈希算法也称之为散列算法,是将数据依照特定的算法直接指定到一个地址上,这样,当加入一个新的元素,先调用这个元素的HashCode方法,一下就定位到了它应该放的物理位置上
-
如果这个位置没有元素,它可以直接存储在这个位置上。不用进行比较
-
如果这个位置已经有元素了,就调用它的equals()方法与新元素进行比较,相同的话就不存了
-
不相同的话,就发生了Hash key相同导致的冲突,那么,那么就在这个Hash key的地方产生一个链表,将所有产生相同HashCode的对象放到这个单链表上。这样一来降低了equals() 方法的调用
HashCode 配合于散列集合一起使用,散列结合主要有:HashSet、HashMap、HashTable
24.深拷贝和浅拷贝的区别
什么是拷贝?
对象拷贝指的是将一个对象的所有属性拷贝到另一个具有相同属性的对象中去
浅拷贝:
浅拷贝对于基本数据类型就是直接进行值传递,在栈中的另一个地方,存放这个基本类型的数据,修改这个值,不会影响原来的值。
对于引用数据类型,浅拷贝会创建一个新的对象。修改新的对象的属性,不会对原属性有影响。
代码:
package com.javaoop;
public class CopyTest {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person("张三",20);
Person p2 = (Person) p1.clone();
System.out.println(p1.getName().equals(p2.getName()));
p2.setName("李四");
System.out.println(p1.getName().equals(p2.getName()));
System.out.println(p1.hashCode());
System.out.println(p2.hashCode());
}
}
class Person implements Cloneable{
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public Object clone()throws CloneNotSupportedException{
return super.clone();//浅拷贝
}
}
但是对于该对象的对象,传递的则是引用。如下,我们修改克隆后对象的children对象,发现克隆前的children的属性也被修改。
package com.javaoop;
public class CopyTest {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person("张三",20);
p1.children = new Children();
p1.children.setChildname("小张三");
p1.children.setChildage(5);
Person p2 = (Person) p1.clone();
//System.out.println(p1.getName().equals(p2.getName()));
p2.setName("李四");
// System.out.println(p1.getName().equals(p2.getName()));
// System.out.println(p1.hashCode());
// System.out.println(p2.hashCode());
p2.children.setChildname("小李四");
System.out.println(p1.children.childname.equals(p2.children.childname));
System.out.println(p1.children.childname);
}
}
class Person implements Cloneable{
public String name;
public int age;
Children children;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public Object clone()throws CloneNotSupportedException{
return super.clone();//浅拷贝
}
}
class Children{
public String childname;
public int childage;
public String getChildname() {
return childname;
}
public void setChildname(String childname) {
this.childname = childname;
}
public int getChildage() {
return childage;
}
public void setChildage(int childage) {
this.childage = childage;
}
}
深拷贝:
深拷贝就是复制一切,拷贝前后两个对象互不影响
我们使Children也实现Cloneable接口
class Person implements Cloneable{
...
@Override
public Object clone()throws CloneNotSupportedException{
Person personClone = (Person) super.clone();
personClone.children = (Children) this.children.clone();
return personClone;
}
}
class Children implements Cloneable{
...
@Override
public Object clone()throws CloneNotSupportedException{
return super.clone();//浅拷贝
}
}
结果可以发现,我们在修改克隆后的对象的children对象,并不会改变克隆前的对象的children属性
总结:
实则浅拷贝和深拷贝只是相对的,如果一个对象内部只有基本数据类型,那用 clone() 方法获取到的就是这个对象的深拷贝,而如果其内部还有引用数据类型,那用 clone() 方法就是一次浅拷贝的操作。
25.JDBC操作的步骤
JDBC是:
SUN公司为了简化开发人员对数据库的统一操作,提供了一个(Java操作数据库)规范,称为JDBC
使用JDBC需要导入 mysql-connector-java jar包
步骤:
-
加载驱动
-
定义数据库用户信息和url
-
连接数据库
-
执行sql对象
-
sql对象执行sql
-
释放连接
详见:
26.什么时候用assert
什么是assert?
assert的中文意思是断言。
断言在软件开发中是一种常用的调试方式,断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为true,如果表达式的值为false,那么系统就会报告一个AssertionError。
断言通常在开发和测试中开启,为了保证程序的执行效率,在软件发布后断言通常是关闭的。
断言的使用
断言通常有两种形式:
assert Expression1;
assert Expression1:Expression2;Expression1 是可以产生布尔值的表达式
Expression2 是用于显示自定义错误的字符串
要在运行时启动断言,可以在启动JVM时使用 -enableassertions 或 -ea来标记,要在运行时禁用断言,可以在启动JVM时使用 -da 或 -disableassertions标记,要在系统类中启用或禁用断言,可使用 -esa或 -dsa标记,还可以在包的基础上启用或禁用断言。
断言默认是关闭的,使用时需要自行开启,断言不具有继承性,父类禁用,子类可以启用
public class AssertTest {
public static void main(String[] args) {
boolean isTrue = 1==2;
assert isTrue;
System.out.println(isTrue);
}
}开启断言前,会打印出 false,开启断言后,抛出错误

自定义错误:
public static void main(String[] args) {
boolean isTrue = 1==2;
assert isTrue:"错误:1不等于2";
System.out.println(isTrue);
}
assert的应用范围
-
检查控制流
-
检查参数是否有效
-
检查函数结果是否有效
-
检查程序不变量
assert相当于一个if判断语句
if(表达式成立){
程序正常执行
}else{
报错&&终止程序
}但是如果使用if判断语句,可能会出现所有的代码都在if中,if语句的括号从文件头到文件尾。但大多数情况下,我们要进行的验证只是偶然性时间,或我们只是想测试一下最坏情况是否发生,所以使用if不太合适,我们就可以使用assert
assert的缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。
设置断言的使用范围
-
-ea java -ea 打开所有用户类的assertion -da java -da 关闭所有用户类的assertion -ea: java -ea:MyClass1 打开MyClass1的assertion -da: java -da: MyClass1 关闭MyClass1的assertion -ea: java -ea:pkg1 打开pkg1包的assertion -da: java -da:pkg1 关闭pkg1包的assertion -ea:… java -ea:… 打开缺省包(无名包)的assertion -da:… java -da:… 关闭缺省包(无名包)的assertion -ea:… java -ea:pkg1… 打开pkg1包和其子包的assertion -da:… java -da:pkg1… 关闭pkg1包和其子包的assertion -esa java -esa 打开系统类的assertion
27.数组有没有 length()这个方法? String 有没有 length()这个方法
数组中没有length() 方法,有length属性
length属性返回数组的元素的数量
int[] arrays = {12,45,98,36,85,22};
System.out.println(arrays.length);String中有length()方法,返回字符串的长度
String str = "字符串长度";
int length = str.length();在String的源码中,把字符串当作char类型的数组,length()方法实际上返回的是char数组的length属性
private final char value[];
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
public int length() {
return value.length;
}
28.用最有效率的方法算出 2 乘以 8 等于几?
使用位运算中的左移
0000 0000 0
0000 0001 1
0000 0010 2
0000 0011 3
0000 0100 4
0000 1000 8
0001 0000 16
由此可以看出 2 左移 3 位变成 16
2<<3 = 16
int num = 0;
num = 2<<3;
System.out.println(num);
29.String 和 StringBuilder、StringBuffer 的区别
-
String是final修饰的,不可变,每次操作都会产生新的String对象,由于String的不可变性,程序运行时会产生一些无用的字符串,运行的效率也比较低
-
StringBuffer: 可变长字符串,由JDK1.0提供,运行效率慢,线程安全
-
会事先开辟缓冲区,之后在缓冲区上面操作
-
由于线程安全,它的运行效率较慢
-
-
StringBuilder:可变长字符串,由JDK5.0提供,运行效率快,线程不安全
-
它与StringBuffer在使用上完全一样,就是线程不安全
-
它的运行效率比StringBuffer要快
-
-
这两个类效率比String 高,比String节省内存
具体详见:
30.接口是否可继承(extends)接口?抽象类是否可实现(implements)接口?抽象类是否可继承具体类(concreteclass)?
-
接口可以继承接口,并且一个接口可以继承多个接口,子接口可以重写父接口中的方法
-
抽象类可以实现接口
-
抽象类可以继承具体类
31.一个”.java”源文件中是否可以包含多个类(不是内部类)?有什么限制?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!