
浅谈负载均衡
负载均衡
负载均衡概念
负载均衡(Load Balance)指由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务而无须其他服务器的辅助。
通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某一台服务器上,而接收到请求的服务器独立地回应客户的请求。
使用负载均衡除了个节点共同分担请求外,还有以下好处:
- 提高性能
- 提高吐出量
- 提高系统可用性
- 提高扩展性,加减机器比较容易
- 提高系统的可维护性,摘除异常机器简单
...
负载均衡方式
- 软件负载均衡:常见的负载均衡软件有Nginx、LVS、HAProxy。
- 硬件负载均衡:常见的负载均衡硬件有Array、F5。
负载均衡算法
前置说明
为演示Demo,我们定义一个服务器列表:
ips: [
"192.168.0.1",
"192.168.0.2",
"192.168.0.3",
"192.168.0.4",
],
下面运行结果统一是:执行100次,然后分别统计服务器的调用次数
const resMap = {};
//执行100次
for (let i = 0; i < 100; i++) {
const ip = getServer();
console.log(ip);
if (!resMap[ip]) {
resMap[ip] = 1;
} else {
resMap[ip]++
}
}
console.log(resMap);
随机算法-RandomLoadBalance
function getServer() {
return ips[Math.floor(Math.random() * (ips.length))];
}
运行结果:
192.168.0.4
192.168.0.3
192.168.0.2
...
192.168.0.3
192.168.0.3
192.168.0.4
{
'192.168.0.4': 26,
'192.168.0.3': 20,
'192.168.0.2': 22,
'192.168.0.1': 32
}
当调用次数比较少时,Random 产生的随机数可能会比较集中,此时多数请求会落到同一台服务器上,只有在经过多次请求后,才能使调用请求进行“均匀”分配。调用量少这一点并没有什么关系,负载均衡机制就是为了应对请求量多的情况,所以随机算法也是用得比较多的一种算法。
但是,上面的随机算法适用于每台机器的性能差不多的时候。实际上,生产中可能某些机器的性能更高一点,它可以处理更多的请求,所以,我们可以对每台服务器设置一个权重。
比如设置为每台服务器设置对应权重:
weightMap: {
"192.168.0.1": 1,
"192.168.0.2": 1,
"192.168.0.3": 3,
"192.168.0.4": 5,
}
简单思路是把每个服务器按它所对应的权重进行复制,具体看代码更加容易理解。
function getServerWithWeight() {
const newIps = [];
for (const k in weightMap) {
const weight = weightMap[k];
for (let i = 0; i < weight; i++) {
newIps.push(k);
}
}
return newIps[Math.floor(Math.random() * (newIps.length))];
}
运行结果:
192.168.0.2
192.168.0.1
192.168.0.4
...
192.168.0.4
192.168.0.4
192.168.0.4
{
'192.168.0.2': 5,
'192.168.0.1': 12,
'192.168.0.4': 55,
'192.168.0.3': 28
}
这种实现方法在遇到权重之和特别大的时候就会比较消耗内存,因为需要对ip地址进行复制,权重之和越大那么上文中的ips就需要越多的内存。
下面介绍另外一种实现思路。
假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的次数大约为5000次,服务器 B 被选中的次数约为3000次,服务器 C 被选中的次数约为2000次。
function getServerWithWeight2() {
const totalWeight = Object.values(weightMap).reduce((p, c) => p + c);
//在 0-totalWeight 范围内取随机数
let index = Math.floor(Math.random() * (totalWeight));
for (const ip in weightMap) {
const weight = weightMap[ip];
if (index < weight) {
return ip;
}
index -= weight;
}
return ips[index];
}
运行结果:
192.168.0.3
192.168.0.4
192.168.0.4
...
192.168.0.4
192.168.0.3
192.168.0.4
{
'192.168.0.3': 25,
'192.168.0.4': 54,
'192.168.0.1': 11,
'192.168.0.2': 10
}
轮询算法-RoundRobinLoadBalance
轮询算法顾名思义,就是一直重复有序循环。
//模拟简单轮询,不考虑并发
let index = 0;
function getServer() {
if (index >= ips.length) {
index = 0;
}
let ip = ips[index];
index++;
return ip;
}
运行结果:
192.168.0.1
192.168.0.2
192.168.0.3
192.168.0.4
...
192.168.0.1
192.168.0.2
192.168.0.3
192.168.0.4
{
'192.168.0.1': 25,
'192.168.0.2': 25,
'192.168.0.3': 25,
'192.168.0.4': 25
}
这种算法很简单,也很公平,每台服务轮流来进行服务,但是有的机器性能好,所以能者多劳,和随机算法一样,加上权重这个维度之后,其中一种实现方法就是复制法,这里不在演示了,缺点也是当权重之和很大的时候,会比较消耗内存。
这里介绍另外一种加权算法:
这个算法需要加入一个概念:调用编号,比如第1次调用为1, 第2次调用为2, 第100次调用为100,调用编号是递增的,所以我们可以根据这个调用编号推算出服务器。
假设我们有三台服务器 servers = [A, B, C],对应的权重为 weights = [2, 5, 1], 总权重为8,我们可以理解为有8台“服务器”,这是8台“不具有并发功能”,其中有2台为A,5台为B,1台为C,一次调用过来的时候,需要按顺序访问,比如有10次调用,那么服务器调用顺序为AABBBBBCAA,调用编号会越来越大,而服务器是固定的,所以需要把调用编号“缩小”,这里对调用编号进行取余,除数为总权重和,比如:
1号调用,1%8=1
2号调用,2%8=2
3号调用,3%8=3
...
97号调用,97%7=1
98号调用,98%8=2
99号调用,99%8=3
100号调用,100%8=4
于是可以把调用编号缩小为0-7之间这8个数字,类似随机算法坐标轴法,即可确认调用编号对应的服务器。
//模拟调用编号
let sequenceNum = 0;
function getSequence() {
return ++sequenceNum;
}
function getServerWithRobin() {
const currentSequence = getSequence()
const totalWeight = Object.values(weightMap).reduce((p, c) => p + c);
let pos = currentSequence % totalWeight;
if (pos === 0) {
pos = totalWeight;
}
for (const ip in weightMap) {
const weight = weightMap[ip];
if (pos <= weight) {
return ip;
}
pos -= weight;
}
}
运行结果:
192.168.0.1
192.168.0.2
192.168.0.3
...
192.168.0.4
192.168.0.4
192.168.0.4
{
'192.168.0.1': 10,
'192.168.0.2': 10,
'192.168.0.3': 30,
'192.168.0.4': 50
}
但是这种算法有一个缺点:分布不均匀,一台服务器的权重特别大的时候,他需要连续的的处理请求。比如假设我们有三台服务器 servers = [A, B, C],对应的权重为 weights = [5, 1, 1] , 总权重为7,那么上述这个算法的结果是:AAAAABC,那么如果能够是这么一个结果:AABACAA,把B和C平均插入到5个A中间,这样是比较均衡的了。
这里可以改成平滑加权轮询。
思路:每个服务器对应两个权重,分别为 weight 和 currentWeight。其中 weight 是固定的,currentWeight 会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的 currentWeight 加上自身权重。遍历完成后,找到最大的 currentWeight,并将其减去权重总和,然后返回相应的服务器即可。
以上述为例子,有三台服务器 servers = [A, B, C],对应的权重为 weights = [5, 1, 1] , 总权重为7。
| 调用编号 | currentWeight 数组 (currentWeight += weight) | 选择结果(max(currentWeight)) | 减去权重总和后的currentWeight 数组(max(currentWeight) -= sum(weight)) |
|---|---|---|---|
| 1 | [5,1,1] | A | [-2,1,1] |
| 2 | [3,2,2] | A | [-4,2,2] |
| 3 | [1,3,3] | B | [1,-4,3] |
| 4 | [6,-3,4] | A | [-1,-3,4] |
| 5 | [4,-2,5] | C | [4,-2,-2] |
| 6 | [9,-1,-1] | A | [2,-1,-1] |
| 7 | [7,0,0] | A | [0,0,0] |
如上,经过平滑性处理后,得到的服务器序列为 [A, A, B, A, C, A, A],相比之前的序列 [A, A, A, A, A, B, C],分布性要好一些。初始情况下 currentWeight = [0, 0, 0],第7个请求处理完后,currentWeight 再次变为 [0, 0, 0]。
const totalWeight = Object.values(weightMap).reduce((p, c) => p + c);
//把currentWeight数组初始赋值为weight
let currentWeight = ips.map(v => weightMap[v] ? weightMap[v] : 0);
function getServerWithRobin2() {
//找currentWeight中的最大值所对应的服务器
const MaxPos = currentWeight.indexOf(Math.max(...currentWeight));
const ip = ips[MaxPos];
//currentWeight中的最大值减去总权重
currentWeight[MaxPos] -= totalWeight;
//所有的ip的currentWeight统一加上原始权重
currentWeight = currentWeight.map((v, i) => v + weightMap[ips[i]]);
return ip;
}
运行结果:
192.168.0.4
192.168.0.3
192.168.0.4
...
192.168.0.4
192.168.0.3
192.168.0.4
{
'192.168.0.4': 50,
'192.168.0.3': 30,
'192.168.0.1': 10,
'192.168.0.2': 10
}
一致性哈希算法-ConsistentHashLoadBalance
服务器集群接收到一次请求调用时,可以根据根据请求的信息,比如客户端的ip地址,或请求路径与请求参数等信息进行哈希,可以得出一个哈希值,特点是对于相同的ip地址,或请求路径和请求参数哈希出来的值是一样的,只要能再增加一个算法,能够把这个哈希值映射成一个服务端ip地址,就可以使相同的请求(相同的ip地址,或请求路径和请求参数)落到同一服务器上。
因为客户端发起的请求情况是无穷无尽的(客户端地址不同,请求参数不同等等),所以对于的哈希值也是无穷大的,所以我们不可能把所有的哈希值都进行映射到服务端ip上,所以这里需要用到哈希环。如下图:
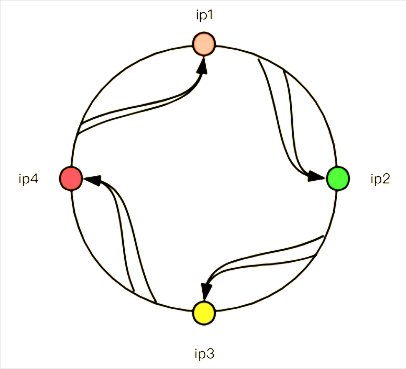
上面这情况是比较均匀情况,如果出现ip4服务器不存在,那就是这样了:
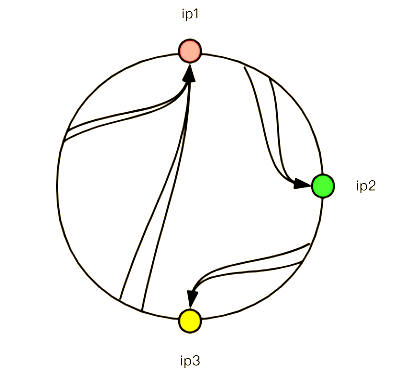
会发现,ip3和ip1直接的范围是比较大的,会有更多的请求落在ip1上,这是不“公平的”,解决这个问题需要加入虚拟节点,比如:
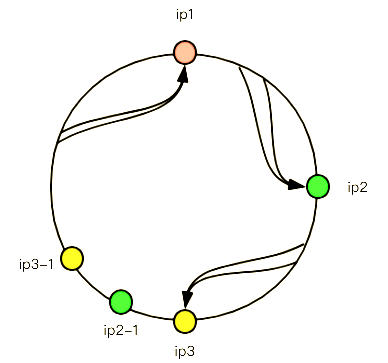
其中ip2-1, ip3-1就是虚拟结点,并不能处理节点,而是等同于对应的ip2和ip3服务器。实际上,这只是处理这种不均衡性的一种思路,实际上就算哈希环本身是均衡的,你也可以增加更多的虚拟节点来使这个环更加平滑,比如:
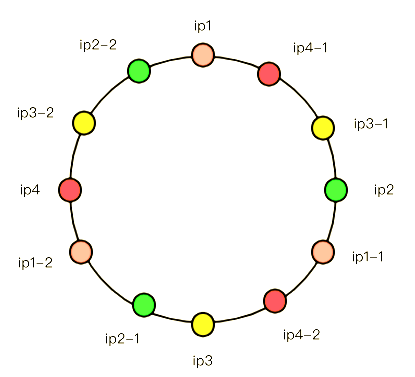
这个彩环也是“公平的”,并且只有ip1,2,3,4是实际的服务器ip,其他的都是虚拟ip。
那么如何实现呢?
对于我们的服务端ip地址,我们肯定知道总共有多少个,需要多少个虚拟节点也有我们自己控制,虚拟节点越多则流量越均衡,另外哈希算法也是很关键的,哈希算法越散列流量也将越均衡。
const VIRTUAL_NODE_NUM = 160;
const VIRTUAL_NODES = new Map();
// 对每个真实节点添加虚拟节点,虚拟节点会根据哈希算法进行散列
for (const ip of ips) {
for (let i = 0; i < VIRTUAL_NODE_NUM; i++) {
const hash = getHash(`${ip}VN${i}`);
VIRTUAL_NODES.set(hash, ip);
}
}
function getServer(client) {
const hash = getHash(client);
const arr = Array.from(VIRTUAL_NODES);
// 得到大于该Hash值的Map,且按key升序
let subArr = arr.filter(item => item[0] > hash);
subArr = subArr.sort((a, b) => a[0] - b[0]);
// 大于该hash值的第一个元素的位置,若不存在,返回第一个虚拟节点
const nodeIndex = subArr[0] ? subArr[0] : VIRTUAL_NODES[0];
const subMap = new Map(subArr);
return subMap.get(nodeIndex[0]);
}
/**
* 改进的32位FNV算法1
* @param {String} str 字符串
* @returns {Number}
*/
function getHash(str) {
const p = 16777619
let hash = Number("2166136261L");
for (let i = 0; i < str.length; i++) {
hash = (hash ^ str.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return hash < 0 ? Math.abs(hash) : hash;
}
运行结果:
192.168.0.3
192.168.0.2
192.168.0.1
...
192.168.0.4
192.168.0.2
192.168.0.1
{
'192.168.0.3': 21,
'192.168.0.2': 26,
'192.168.0.1': 24,
'192.168.0.4': 29
}
最小活跃数算法-LeastActiveLoadBalance
前面几种方法主要目标是使服务端分配到的调用次数尽量均衡,但是实际情况是这样吗?调用次数相同,服务器的负载就均衡吗?当然不是,这里还要考虑每次调用的时间,而最小活跃数算法则是解决这种问题的。
活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。在具体实现中,每个服务提供者对应一个活跃数。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。除了最小活跃数,最小活跃数算法在实现上还引入了权重值。所以准确的来说,最小活跃数算法是基于加权最小活跃数算法实现的。举个例子,在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,则会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可。
//模拟当前服务器的活跃数
const ACTIVICY_LIST = {
"192.168.0.1": 5,
"192.168.0.2": 4,
"192.168.0.3": 3,
"192.168.0.4": 3
};
function getServer() {
//获取最小活跃数
const minActivityIps = [];
const minValue = Math.min(...Object.values(ACTIVICY_LIST));
for (const ip of Object.keys(ACTIVICY_LIST)) {
if (ACTIVICY_LIST[ip] === minValue) {
minActivityIps.push(ip);
}
}
// 最小活跃数的ip有多个,则根据权重来选,权重大的优先
if (minActivityIps.length > 1) {
// 过滤出对应的ip和权重
const weightList = [];
for (const ip in weightMap) {
if (minActivityIps.includes(ip)) {
weightList.push(weightMap[ip]);
}
}
const totalWeight = weightList.reduce((p, c) => p + c);
//在 0-totalWeight 范围内取随机数
let index = Math.floor(Math.random() * (totalWeight));
for (const ip of minActivityIps) {
const weight = weightMap[ip];
if (index < weight) {
return ip;
}
index -= weight;
}
} else {
return minActivityIps[0];
}
}
运行结果:
192.168.0.4
192.168.0.3
192.168.0.4
...
192.168.0.3
192.168.0.4
192.168.0.4
{ '192.168.0.4': 63, '192.168.0.3': 37 }
这里因为不会对活跃数进行操作,所以结果是相对固定的。
负载均衡策略对比
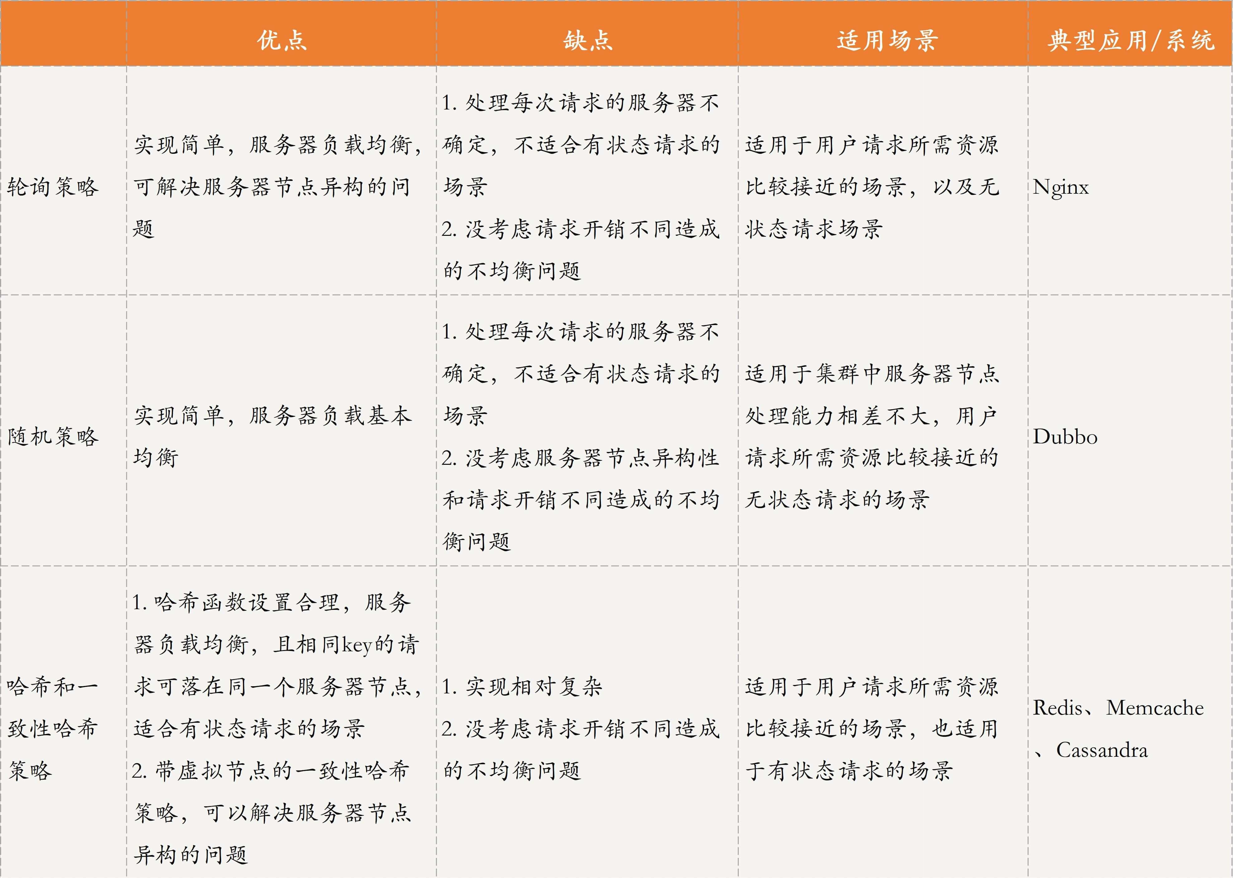
负载均衡运用
像在 kubernetes 中运用了多种负载均衡,比如提供四层负载均衡的 kube-proxy,在 iptables 模式下默认的负载均衡算法是随机(Random balancing);而在 ipvs 模式下默认是轮询(Round Robin);
提供七层负载均衡的 Ingress,以 traefik 为例,同样也支持轮询(Round Robin)和加权轮询(Weighted Round Robin)的负载均衡策略;
在 nginx 中同样也支持了多种负载均衡算法,比如随机、简单轮询、加权轮询、hash(按IP、URL或其他字段)、最快响应、最少连接数等。
还有很多场景下会用 haproxy + keepalived 来实现服务的高可用、负载均衡或代理,比如数据库、高负载的web站点。
在各种业务场景下,对于如何选择哪种负载均衡策略,需要结合实际场景考虑比如请求数、请求所需资源数,算法没有最好,只有更合适的。
本文作者:Ashin5800
本文链接:https://www.cnblogs.com/wzs5800/p/16255378.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2020-05-10 mongo 使用聚合合并字段