
Oracle-3 - :超级适合初学者的入门级笔记--用户权限,set运算符,高级子查询
上一篇的内容在这里 第二篇内容,
用户权限:创建用户,创建角色,使用grant 和 revoke 语句赋予和回收权限,创建数据库联接
创建用户:create user xxx identified by pass: xxx为 新创建用户的用户名,pass 为密码
在这里强调的是 oracle 12c版本 必须创建用户以C##开头,也可以更改,详见百度 ,哈哈
但是新创建的用户并没有create session 权限,见图,登陆被拒绝
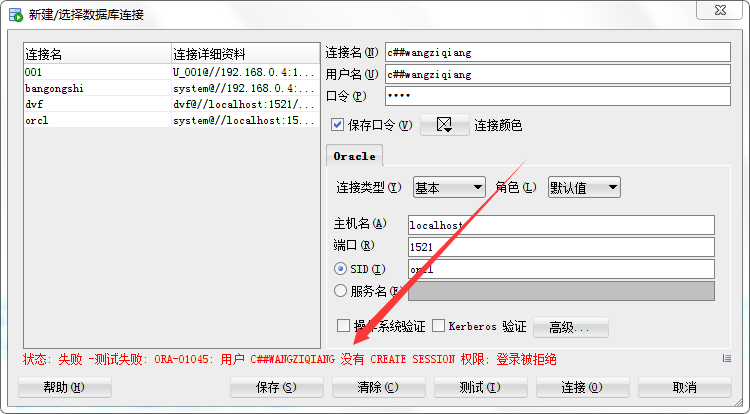
授予用户权限 :grant 权限 to 用户
由于他没有create session 权限,我们可以赋予其权限 :grant create session to c##wangziqiang; 这时候就可以登录了
后续的需要的权限自己赋予即可,大神贴
创建表create table emp(id number(10),name varchar2(20)); 这时候会提示权限不足 。

赋予create table 的权限:grant create table to c##wangziqiang; 这时候就可以进行创建表了
如果提示表空间错误,可以进行更改表空间: alter user userName quota unlimited on users;这里是为userName创建了一个不限大小的表空间,如果限制表空间的话,需要 把unlimited 改成自己想设置的值 例如: 5m 即 五兆的大小
更改自己密码 :alter user c##wangziqiang identified by 123;
创建角色:角色集成一个或多个权限,把某角色给某用户,用户就拥有了该角色的所有权限,相当于一个头衔,
create role c##myrole;创建了一个名为myrole 的角色
grant create table,create view ... to c##myrole:为角色赋予权限
grant c##myroleto user:将角色赋予用户
将自己的对象的相关权限赋予 他人:就是把自己表视图等的增删改查的权限赋给别人,
如图wangziqiang用户没有dvf 用户jobs表的相关权限,当查询时会提示,表或视图不存在
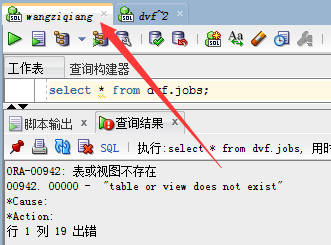
我们来给wangziqiang用户赋予dvf用户的jobs表的查询权限,
grant select --相关权限,用逗号分隔
on dvf.jobs -- 哪个用户的那个表
to c##wangziqiang; --赋给谁
这时候再次查询就会出现jobs表的信息
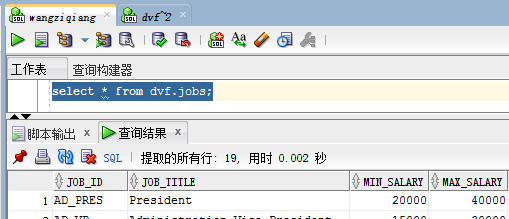
当A授予B用户自己的表的相关权限,默认的是B不能再把A给B的权限赋给别人。通过末尾加上 with grant option ,来设置B也可以赋给别人A的表的相关权限
当一张表需要所有人都拥有此表的相关权限的时候,我们可以用public 来为所有用户分配该表得权限:grant select --相关权限,用逗号分隔
on dvf.jobs -- 哪个用户的那个表
to public; --赋给所有用户
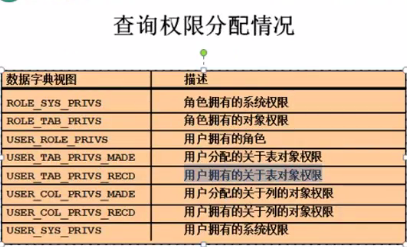
命令:select * from user_tab_privs_recd; 在wangziqiang用户下查询用户拥有的关于表对象权限,如下图,此用户拥有 dvf用户的jobs表的select权限

删除相关权限:revoke select on dvf.jobs from c##wangziqiang; 删除select权限 在 dvf用户的jobs表上的,从c##wangziqiang这里收回,就是从c##wangziqiang用户这收回dvf的jobs表的查询权限,
命令运行完,再查wangziqing用户下的拥有的关于表对象的权限,这时候相关的权限已经取消掉了

set操作符
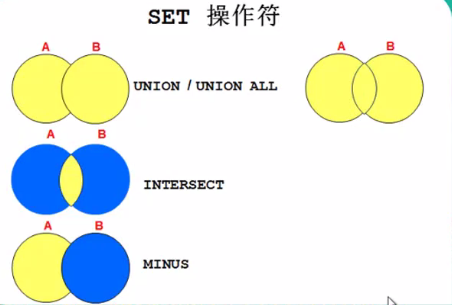
如上图 union代表 去除两个集合中相同的元素,只取出两个集合不同的元素。
union all 代表 去除两个集合中的元素,包括两个集合中重复的元素
intersect 代表取两个集合中的交集、
minus 代表 A minus B就是 先从A集合中取出与B集合中相同的元素,再取出A中剩下的所有元素,不取出B
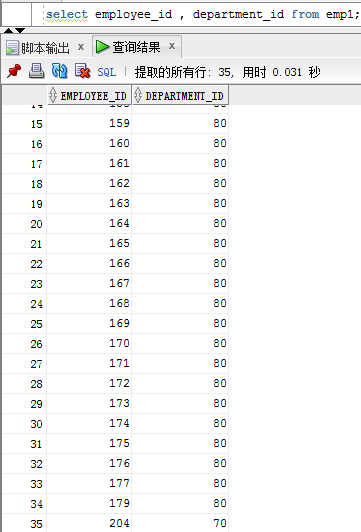
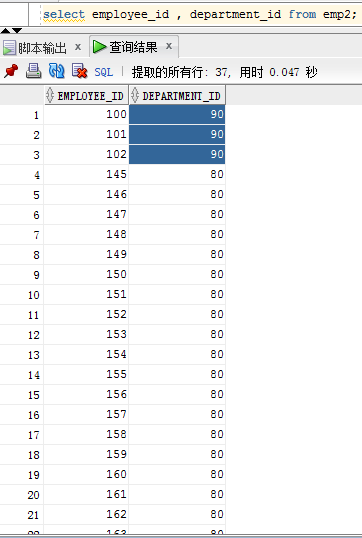
创建表emp1 和 emp2 给予employees 表,emp1 只包含employees表中的 70和80号部门的信息,emp2 包含 employees表中 80 和 90 号部门的信息
emp1 中 一共35条数据,其中80号部门的34个,70号部门的只有一个
emp2 表中 37条数据,其中90号部门的三条,其余全是80号部门的
注意的是两个表的查询语句的列的个数,和数据类型必须一致。否则报错
如果想为查询结果取别名的话,我们只能在查询的上面其别名,起到下面是没有效果的
例如:select employee_id emp_id , department_id from emp1
union
select employee_id , department_id de_id from emp2; --这里的查询结果会只显示emp_id
查询结果会默认的按照第一列的大小顺序去显示输出,也可以按倒序排序
例如:select employee_id emp_id , department_id from emp1
union
select employee_id , department_id de_id from emp2
order by emp_id desc;
或者按照列名的顺序数字进行排序
select employee_id emp_id , department_id from emp1
union
select employee_id , department_id de_id from emp2
order by 1 desc; --与上面作用一样,因为 emp_id出现的位置是第一列
union操作:emp1 和 emp2 表,由于union是取两个表中不同的元素,由于emp1 和 emp2 中80号部门重复出现,所以只算一次80号部门
select employee_id , department_id from emp1
union
select employee_id , department_id from emp2;--查询两个表中的不同元素,70号部门 + 80号部门+90号部门 = 1+ 34+3 = 38
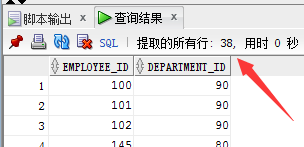
union all 操作: 取emp1 和 emp2 的两个表中所有元素,包括重复的
select employee_id , department_id from emp1
union all
select employee_id , department_id from emp2; --查询表中所有元素,70号部门 + 80号部门+ 80号部门+90号部门=1+34+34+3=72
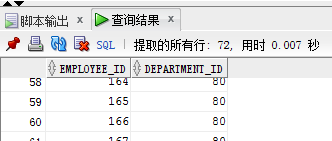
intersect:取两个表中的交集:两个表中只有是80号部门是重复的所以出来的结果只有34条,部门为80号部门
select employee_id , department_id from emp1
INTERSECT
select employee_id , department_id from emp2;
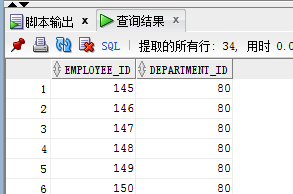
minus操作:取差集,A minus B就是把A与B重复的内容从A中去掉,由于两个表重复80号部门,所以A表去除80号部门后只剩70号部门,
select employee_id , department_id from emp1
minus
select employee_id , department_id from emp2;
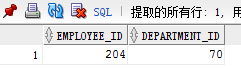
当emp2 minus emp1时,出现的结果为90号部门
上述的注意事项中,如果查询的两个表中的列就是匹配不上怎么办?我们可以用转换函数来替代位置
例如:select employee_id , department_id from emp1 --类型:number , number
minus
select department_id , department_name from departments; --类型”:number varchar2
这时候就会出现匹配不上类型的错误

这时候我们可以用转换函数来替代位置,看上述的查询语句,首先找到对应的列,两个表中只有department_id是可以对应的上的
所以我们需要为第二个查询最开始添加一个tonumber 的函数,以此把department_id排到第二位与第一个查询的department_id位置相同,这时候第二个查询
会多出来一个department_name 这时候我们需要为其在第一个查询中匹配相应的类型的列,所以查询可以这样写了
select employee_id , department_id,to_char(null) from emp1 --类型:number , number ,varchar2
minus
select to_number(null),department_id , department_name from departments; --类型”:number , number ,varchar2
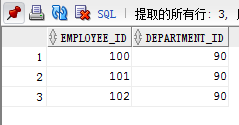
例题:查询10,20,50号部门的job_id,department_id并且department_id按 10, 50 ,20 排序,
这道题麻烦在不是按照自然顺序进行排序的,必须按照10 50 20 排序
我们可以用union来进行查询,union自动去掉了两个表中重复的元素
select job_id,department_id,1 from employees where department_id = 10
union
select job_id,department_id,3 from employees where department_id = 20
union
select job_id,department_id,2 from employees where department_id = 50
order by 3; -- 这里运用了用列的列数来制定排序规则,并且在每次查询上多添加了一个列,来制定顺序,
高级子查询:
多列子查询:第一张记录的子查询都是单列子查询,就是括号中的查询语句只返回一列的信息,供外部的主查询使用,多列子查询,括号中返回多列的值供主查询使用
与单列子查询的区别就是在子查询中,一个返回多列值一个返回单列值
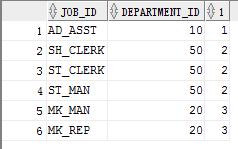
例题:查询与141 和 174号员工的manger_id 和department_id相同的其他员工的employee_id,manager_id,department_id
使用单列子查询: select employee_id,manager_id,department_id from employees
where manager_id in (
select manager_id from employees where employee_id in (141,174)
)
and
department_id in (
select department_id from employees where employee_id in (141,174)
)
and employee_id not in(141,174);
使用多列子查询:
select employee_id,manager_id,department_id from employees
where (manager_id,department_id) in (
select manager_id,department_id from employees where employee_id in (141,174)
)
and employee_id not in(141,174);
在from子句中使用子查询
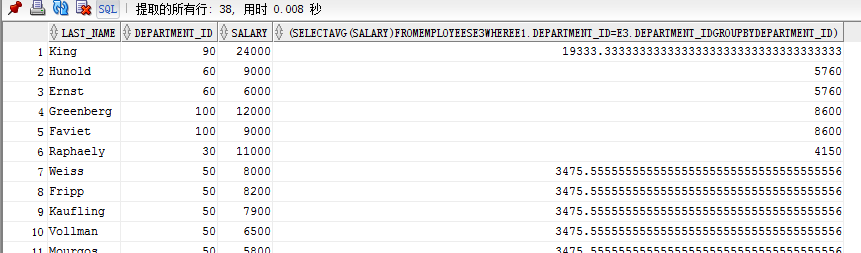
例题:返回比本部门平均工资高的员工的last_name,department_id ,salary 及平均工资
select last_name,department_id,salary,(select avg(salary) from employees e3 where e1.department_id = e3.department_id group by department_id)
from employees e1
where salary >(select avg(salary) from employees e2 where e1.department_id = e2.department_id group by department_id);
使用from子句中子查询:在这里e2就是临时用select查询出来的一个临时表
select e1.last_name,e1.department_id ,e1.salary ,e2.avg_sal
from employees e1 ,(select department_id ,avg(salary)avg_sal from employees e2 group by department_id ) e2
where e1.department_id = e2.department_id and e1.salary >e2.avg_sal;
单列子查询应用实例:
显示员工的employee_id,last_name,.location,其中,若员工的department_id与location_id为1800的department_id相同,则location为Canada,其余则为 usa
select employee_id,last_name,
case department_id when(select department_id from departments where location_id = 1800) then 'Canada' else 'USA' end as location
from employees ;
--查询员工的employee_id,last_name,按照员工的department_name排序
select employee_id,last_name from employees e order by (
select department_name from departments d where e.department_id = d.department_id
);
相关子查询:相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询
其实上面的第二个实例就是一个相关子查询,主查询的信息供子查询去使用,如果子查询中满足条件,那么就返回该数据
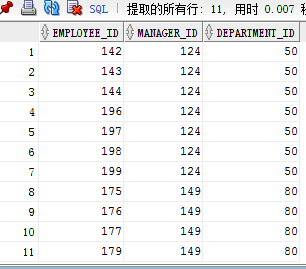
实例:若employees表中employee_id与job_history表中employee_id相同的数据小于2,输出这些相同id的员工的employee_id,last_name,job_id
首选查询job_history表中数据,发现有这三个员工是满足条件的
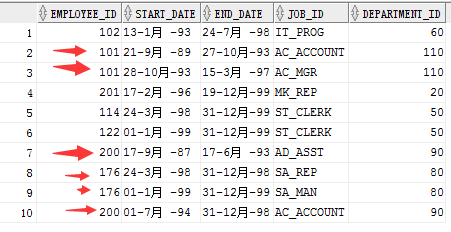
查询:select employee_id,last_name,job_id from employees e where 2<= (
select count(*) from job_history where e.employee_id = employee_id
);--解释说明:主查询每进入一个employee_id都要去子查询中去判断是否子查询中的相等,每次进入的一个employee_id都会匹配一遍job_history当满足大于等于2时就会返回该条数据
exists :检查在子查询中是否存在满足条件的行
--如果在子查询中存在满足条件的行:返回true,不在子查询中继续寻找
--如果在子查询中不存在满足条件的行:返回false,继续在子查询中寻找
实例:查询公司管理者的 employee_id,last_name,job_id,department_id
select employee_id,last_name,job_id,department_id from employees e where exists ( select distinct manager_id from employees where e.employee_id = manager_id);--在这子查询中不用返回 manager_id也可以 ,exists只是判断是否存在
not exists:与 上面的exists相反
相关更新:使用相关子查询依据一个表中的数据更新另一个表的数据
相关删除:使用相关子查询依据一个表中的数据删除另一个表的数据,这两个相关的更新其实就是相关子查询的应用。
with子句: 使用这个with语句,可以避免在select语句中重复书写相同的语句块,
with子句将该子句中的语句块执行一次并存储到用户的临时表空间中
可以提高查询效率
with 查询就是可以把一个查询的结果临时的当做一个表来临时存储,供下面的语句使用
实例:查询公司中各部门的总工资大于公司中各部门的平均总工资的部门的信息
with sum_sal_tab as(
select department_name,sum(salary)as sumsal from DEPARTMENTS d,EMPLOYEES e where d.DEPARTMENT_ID = e.DEPARTMENT_ID group by d.DEPARTMENT_name )--各部门的总工资
, avg_sal_tab as (select sum(sumsal)/count(*) as avgsal from sum_sal_tab )
select * from sum_sal_tab where sumsal>(select avgsal from avg_sal_tab);
注意的是只用开头写一个with即可,多个with之间第二个不用写with,但是需要逗号分割

 浙公网安备 33010602011771号
浙公网安备 33010602011771号