

使用centernet进行大规模遥感影像目标检测
时间又过了好久了。。。这一次我再来更新一下目标检测这一块的内容,为什么要更新这一块呢,主要是看到了YOLOX的发布,晚上11点躺在床上看的,终于看到了一个硬货,旷世科技还是牛逼。。一句话总结,什么Anchor,什么nms,统统不要,直接一把梭,端对端输出结果,最终精度又高,网络又简洁,真是不错。好了,希望不要被旷世的人看见,我这彩虹屁吹的。
很久很久之前,我就Anchor非常不爽,为什么神经网络这么简洁的东西,要加这么个玩意,不就是让网络训练的更加稳定一些么,这个东西的添加,再某个程度上来说,大大增加了开发难度,容易在编程的时候搞晕头脑,虽然说精度尚可,但是我隐隐约约总感觉这玩意绝对淘汰,所以我一直期待一种真正的工程版的Anchor-Free算法,今天要讲的就是centernet这个网络,我非常喜欢这篇文章,非常简单,非常有效,而且可扩展性有非常的好。
原理部分我就不多讲了,我们先直接看结果吧
30张样本,检测出来的飞机还是不错的!
不知道把它用到大范围上,效果会如何,我用深圳宝安区做了一个测试,影像大小为20000*30000左右,跑了5分钟左右吧,看看效果如何:

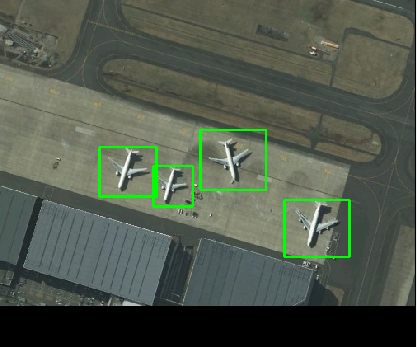
看看宝安机场如何?

整体来看,效果还是非常不错的,有几个大飞机丢失了,这个是在意料当中,后面把样本扩充一下,加一些新的trick进去,相信应该不错。
当然这里面还有一些核心算法,我用python代码给大家讲一下,这篇论文里面也有几个需要注意的地方,尤其是用到遥感工程项目里面。
第一个,groundTruth准备
这一部分,我们需要准备真值中心点,还有长宽,中心点偏移,这里需要注意一点,就是原始论文里面有这样一句话,--We do not normalize the scale and directly use the raw pixel coordinates. We instead scale the loss by a constant λsize.
The overall training objective !,意思就是说使用原始的长宽输入到真值里面,然后计算loss,这个实在是太重要了,因为我发现很多知乎公众号里边,他妈的根本就没提这个细节,我就按照很多通用做法,把它scale成一定的比例,当成真值,
结果发现长宽输出会出现负数,这就明显比对了,请使用下面这个代码!!
def get_hw_center(json_path, h, w, scale): """ 从json格式中读取目标的宽高和中心点位置 json_path: json文件的路径 h: 原始图像的高度 w: 原始图像的宽度 scale; 特征图与原图的比例,centernet为1/4 """ myObject = [] with open(json_path, 'r', encoding='utf-8') as f: ret_dic = json.load(f) imgPath = ret_dic['path'] target_Obj['imgPath'] = imgPath object = (ret_dic['outputs']['object']) numObject = len(object) print(numObject) for i in range(0, numObject): obj = object[i]['bndbox'] xmin = obj['xmin'] ymin = obj['ymin'] xmax = obj['xmax'] ymax = obj['ymax'] obj_width = np.abs(xmax - xmin)*scale # 原图中目标的宽度,原版论文无需归一化 obj_height = np.abs(ymax - ymin)*scale # 原图中目标的高度,原版论文无需归一化 centerPoint = [(xmax+xmin)/2*scale, (ymax+ymin) / 2*scale] # 目标在特征图中的中心点坐标 target_Obj['height'] = np.array(obj_height).copy() target_Obj['width'] = np.array(obj_width).copy() target_Obj['centerPoint'] = np.array(centerPoint).copy() myObject.append(target_Obj.copy()) return myObject
第二个,网络结构里面更改
原论文---We modify both ResNets and DLA-34 using deformable convolution layers [12] and use the Hourglass network as is,意思就是说,resnet,DLA,hourglass这些网络,作者在上采样阶段,用了可形变卷积来替换,
这一个可以多说一点,形变卷积可以学习到传统卷积无法学下到的长距离信息。
这一个可以多说一点,形变卷积可以学习到传统卷积无法学下到的长距离信息。
第三个,损失函数
这个是最重要的了,我们一定要看原论文,特别注意热图,长宽,中心点偏移三者的权重,论文推荐比例为[1,0.1,1],当然这是实验科学,具体的还要根据各位的自己数据来!
我们上代码:
class L1Loss(nn.Module): """ L1 loss,论文证明,该loss要比smooth L1 loss要好! """ def __init__(self): super(L1Loss, self).__init__() def forward(self, pred, mask, target): numPoint = mask[:, 0, :, :].float().sum() # 目标点个数 loss = F.l1_loss(pred * mask, target * mask, reduction='elementwise_mean') return loss/(numPoint+1e-4)
好吧,先写到这里,下一步我会来更新超大影像的目标检测及相关工程应用上的精度 与效率如何,需要代码请加qq 1044625113。
用一句话来总结我的想法,只做有用的东西,不做灌水的东西!大家共勉!

