

进入python的世界_day18_python基础——软件开发目录规范、collections模块、时间模块、random模块
一、包的具体使用
包的名称可以作为模块导来导去,如果导包,是调用包文件夹下的__init__.py文件,所以就和昨天博客写的那个例子一样,在该文件中导入同目录下的文件,这样别人在导包时就可以点出来包下的文件了
二、编程思想的转变
就按照我们目前快学了一个月的转变来说:
1.最初是所有代码都写在一个py文件内,一排排自上而下的写,代码低级冗余
2.学会了用while循环 if嵌套 函数等,让代码变得结构化起来,而且精简了部分代码
3.熟练掌握模块和包,让不同的文件负责不同的功能,集中管理统一调度
PS:有点像开公司,或者组建工会,就是逐渐专人干专事,再发展到部门
三、软件开发目录规范——背下来!!!
(interface是在代码中使用的接口,api是提供给外部使用的程序接入点。)
- api 存放接口文件,接口主要用于为业务逻辑提供数据操作
- api.py --> 应用程序编程接口
- bin 整个项目的启动文件放置在这个文件夹中
- start.py --> 启动软件入口
- conf 整个项目的配置文件放置在这个文件夹
- settings.py 配置文件,一般都是全大写
- 比如存放一些固定的路径
- core 整个项目的核心文件
- src.py 核心业务逻辑代码 (第一层:用户视图层:核心业务逻辑代码)
- db 用于存放数据文件与操作数据的代码文件
- db_file ---> db.txt ...
- db_handler.py---> 存放操作数据的代码(第三层:数据处理层)
- interface 用于存放接口文件
- user_interface.py ---> 用户接口文件(第二层:用户接口)
- lib 项目的公共功能,比如第三方包,共享的一些库
- common: 存放公共的功能
- 比如存放 装饰器
- log 用于存放项目的日志文件
- log.txt 存放日志的文件
- requirements.txt文件 依赖
- 主要存放项目所需模块及版本,requirements.txt可以通过pip命令自动生成和安装
- README.TXT 整个项目的说明文件,项目需求和大致流程,相当于产品说明书
四、常见内置模块——collections模块
1.namedtuple——具名元组
返回一个名为typename的新元组子类,新的子类用于创建类似元组的对象,这些对象具有可通过属性查找访问的字段以及可索引和可迭代的字段field_names
例子:
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y']) # 类名为Point,属性有'x'和'y'
p = Point(888, y=999) # 用位置或关键字参数实例化,因为'x'在'y'前,所以x=888,和函数参数赋值一样的
print(p[0] + p[1]) # 我们也可以使用下标来索引访问取值
# >>>1887
x, y = p # 也可以像一个元组那样解析
print(x, y)
# >>>(888, 999)
print(p.x + p.y) # 也可以通过属性名来访问
# >>>1887
print(p) # 通过内置的__repr__函数,显示该对象的信息
# >>>Point(x=888, y=999)
————————————————————————————————————
其实更像一个带名字的字典
p = Point(x=888, y=999) # 新建一个对象
d = p._asdict() # 解析并返回一个字典对象
print(d)
# >>>{'x': 888, 'y': 999}
2.deque——队列
实现了两端都可以操作的队列,相当于双端队列
import collections
t = collections.deque()
t.append('a')
t.append('666')
t.append('hahaha')
t.appendleft('d') # 不是尾部追加而是头部追加
t.extend('777') # 字符串会被迭代拆分
t.extend([777]) # 换成列表就可以
t.extendleft(['出去玩'])
print(t)
>>>
deque(['出去玩', 'd', 'a', '666', 'hahaha', '7', '7', '7', 777])
剩下很多方法就和列表一样了,诸如删除,翻转,统计数等等
3.orderddict() 有序字典
让创建字典时,存放顺序和添加顺序一致(注意:和dict直接转过去的顺序不一定相同)
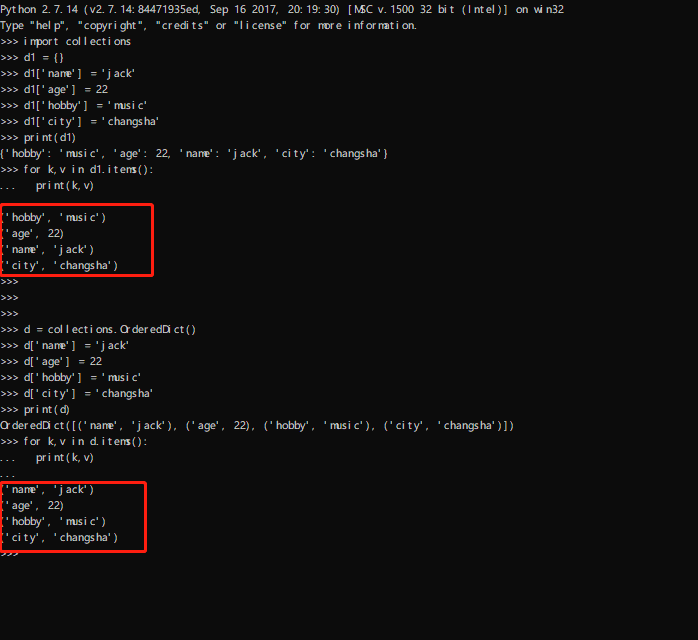
其实python 3.6以后,已经优化了相当于给字典打了这个功能,字典输入数据值时,先输入的位置就在前,后输入的位置就在后
4.Counter ——字符串字符个数统计,注意大写!返回元组包字典
import collections
t = "WOW you can really dance"
print(collections.Counter(t))
>>>
Counter({' ': 4, 'a': 3, 'W': 2, 'y': 2, 'c': 2, 'n': 2, 'e': 2, 'l': 2, 'O': 1, 'o': 1, 'u': 1, 'r': 1, 'd': 1})
五、常见内置模块——time模块
1.time.time()——时间戳(1970纪元后经过的浮点秒数)
2.time.sleep()——代码阻塞(默认以秒为单位)
3.时间的三种模式
-
时间戳——Timestamp
-
格式化的字符串——Format String
import time print(time.strftime("%Y-%m-%d %X")) # 格式一定要搞会,大小写不能搞混 # %Y-%m-%d 代表年月日 %H-%M—%S代表时分秒 # %X = %H-%M—%S >>> 可以得到当前的时间,按照设定的格式 -
结构化的时间——struct_time
这个时计算机能读懂的,我们看起来一般不好看 struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)import time print(time.localtime()) >>> time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=15, tm_min=20, tm_sec=24, tm_wday=2, tm_yday=292, tm_isdst=0)
转换关系图+关键字
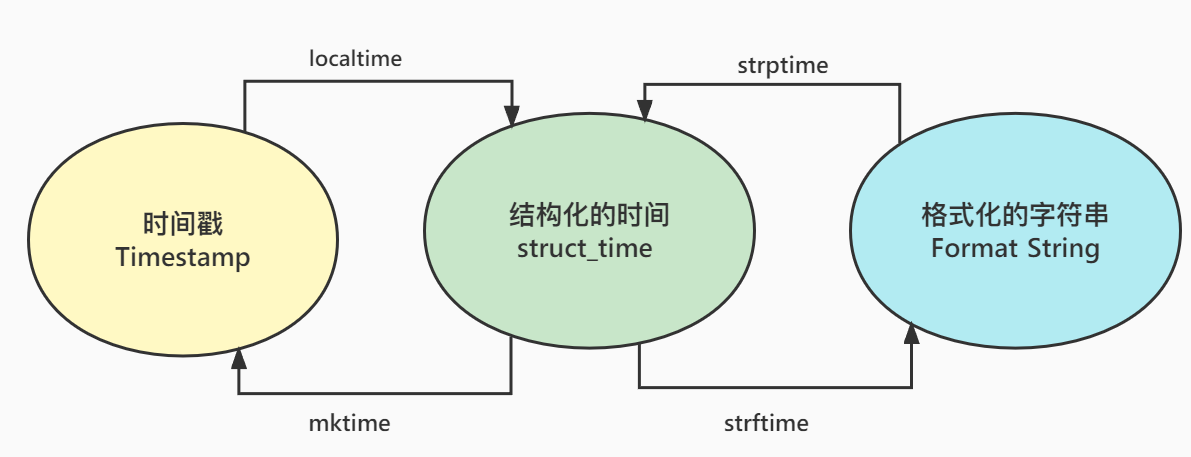
# 时间戳转结构化时间 —— localtime
import time
t = time.time()
print(time.localtime(t))
————————————————————————————————————
# 结构化时间转时间戳 —— mktime
import time
t = time.time()
F = time.localtime(t)
print(time.mktime(F))
___________________________________
# 格式化字符串时间转结构化时间 —— strptime
import time
print(time.strptime('2022-10-01 16:16:16', '%Y-%m-%d %X'))
# 注意带上格式再转
—————————————————————————————————————
# 结构化时间转格式化的字符串时间 —— strftime
import time
t = time.localtime()
f = time.strftime('%Y-%m-%d %X', t)
# 带想要的格式,后面带结构化时间
print(f)
# ps:助记,格转结用strptime,格式在后头
# 结转格用strftime,格式在前头
六、常见内置模块——datetime模块
import datetime
print(datetime.datetime.today())
print(datetime.datetime.now()) # 北京时间
print(datetime.datetime.utcnow()) # 世界标准时间
print(datetime.datetime.fromtimestamp(1564554654)) # 直接把时间戳转换成标准时间
# 指定时间赋值给一个变量,变为时间对象
import datetime
t = datetime.datetime(2022, 10, 10, 11, 11)
print(t)
>>>
2022-10-10 11:11:00
______________________________
# 对时间对象可以点打印出其属性
# 依旧拿上面的t为例
print(t.year)
print(t.month)
print(t.hour)
print(t.minute)
>>>
2022
10
18
18
# 转化
# 字符串(表示日期和时间)创建一个datetime对象
from datetime import datetime
t = '2022/10/01'
print(datetime.strptime(t, '%Y/%m/%d'))
>>>
2022-10-01 00:00:00
——————————————————————————————————
from datetime import datetime
t = datetime.now()
print(t)
t1 = t.strftime('%m/%d/%Y, %H:%M:%S')
# mm/dd/YY H:M:S format
print('t1:', t1)
# 一个好玩的时间差演算——timedelta模块
import datetime
a = datetime.date.today()
print(a)
b = datetime.timedelta(days=7) # ()内参数可控制
print(a + b) # ()运算符可以控制
print(a - b)
七、常见内置模块——random模块
英文是随机的意思,实际生活中很常见,比如验证码,比如强化概率,比如发牌洗牌等
import random
print(random.random()) # float 大于0 小于1 的小数
print(random.randint(1,5)) # [1,5] 开区间 大于等于1 小于等于5 的整数
print(random.randrange(1,5)) # [1,5) 大于等于1 小于5 的整数
print(random.choice([1,'adc',[5,8]])) # 1 或者 ‘adc’ 或者 [5,8] 多选一,随机拿
print(random.sample([11,'aaa','ccc','ddd',22],2)) # 列表元素 任意2个组合 []后面跟的数字控制取几个
print(random.uniform(1,5)) # 大于1 小于5 的小数
item = ['a','b','c','d','e','f','g']
random.shuffle(item) # 打乱item的顺序,相当于 “洗牌”
print(item)
课堂中作业:
Q:设计一个四位数的随机验证码的代码,要求每位都可以是大写字母小写字母、数字
_____________________________________
# 解答思路:每位都有三种可能,三选一,可用choice
# 四位数验证码,每次随机出一位,随机四次然后组合起来
# 大写小写可以用 chz()来拿数字转
def yanzhengma(n):
import random
for i in range(n):
upper = chr(random.randint(65, 90))
lower = chr(random.randint(97, 122))
numbers = random.randint(0, 9)
print(random.choice([upper, lower, numbers]), end='')
yanzhengma(4)
________________________________________
def yanzhengma(n):
import random
a = ''
for i in range(n):
upper = chr(random.randint(65, 90))
lower = chr(random.randint(97, 122))
numbers = str(random.randint(0, 9))
n = random.choice([upper, lower, numbers])
a += n
return a
ccc = yanzhengma(10)
print(ccc)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现