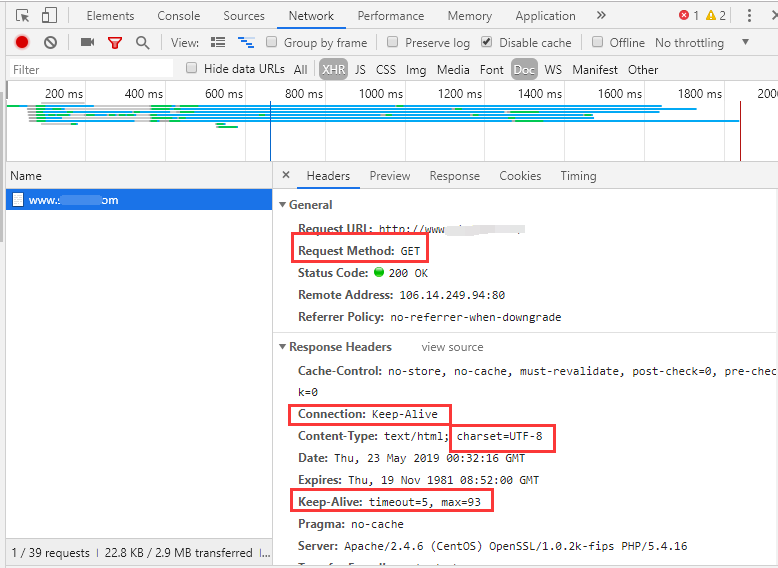
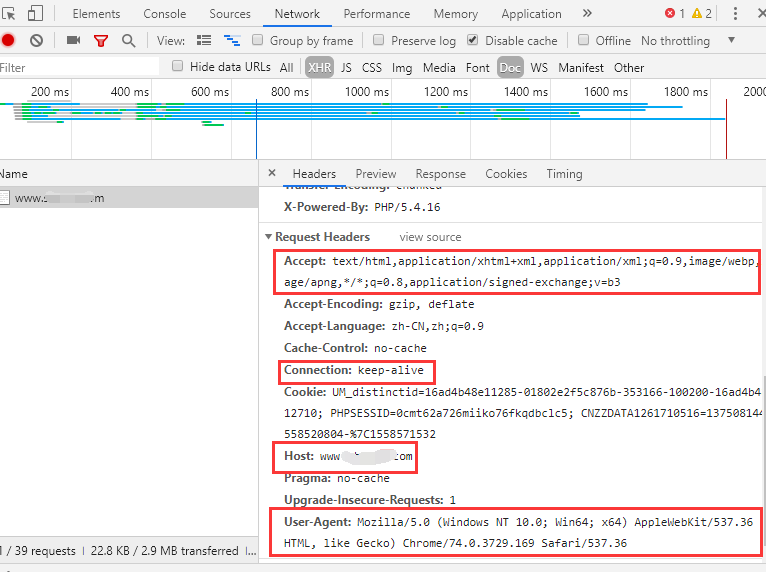
c# 写个简单的爬虫。注:就一个方法,没有注释,自己猜~哈哈
和我,在成都的街头走一走,哦~喔~哦~
public JsonResult GetHtml() { string url = "http://www.xxxxxxxxxxxxxxxxxx.com/index.php?f=order&no=618621";//网站地址 HttpWebRequest Myrq = (HttpWebRequest)WebRequest.Create(url); Myrq.KeepAlive = false; Myrq.Timeout = 30*1000; Myrq.Method = "GET"; Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3"; Myrq.Host = "www.xxxxxxxxxxxxxx.com"; Myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"; HttpWebResponse myrp = (HttpWebResponse)Myrq.GetResponse(); if (myrp.StatusCode != HttpStatusCode.OK) { return ApiSuccessResult("no ok"); } using (StreamReader sr = new StreamReader(myrp.GetResponseStream())) { return ApiSuccessResult(sr.ReadToEnd()); //返回爬到的网页 } }
public JsonResult GetHtml() { string url = "http://img.xxxxxxxxxxxxxxxxxx.com/7a530ea8ffc84a13efdcfc61c68ad8d5"; //图片地址 HttpWebRequest Myrq = (HttpWebRequest)WebRequest.Create(url); Myrq.KeepAlive = false; Myrq.Timeout = 30*1000; Myrq.Method = "GET"; Myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3"; Myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"; HttpWebResponse myrp = (HttpWebResponse)Myrq.GetResponse(); if (myrp.StatusCode != HttpStatusCode.OK) { return ApiSuccessResult("no ok"); } using (FileStream fs = new FileStream("1.jpg",FileMode.Create)) { myrp.GetResponseStream().CopyTo(fs); return ApiSuccessResult("ok"); } }