

oracle执行计划分析
参考文档:https://www.cnblogs.com/yhoralce/p/7735890.html
一、定义
执行计划是一条查询语句在Oracle中的执行过程或访问路径的描述,注意,是查询语句。
二、查看执行计划
1)打开PL/SQL数据库管理工具;
2)在SQL窗口选中一条 SELECT 语句后,或者选中Tools > Explain Plan,或者按 F5 即可查看刚刚执行的这条查询语句的执行计划;
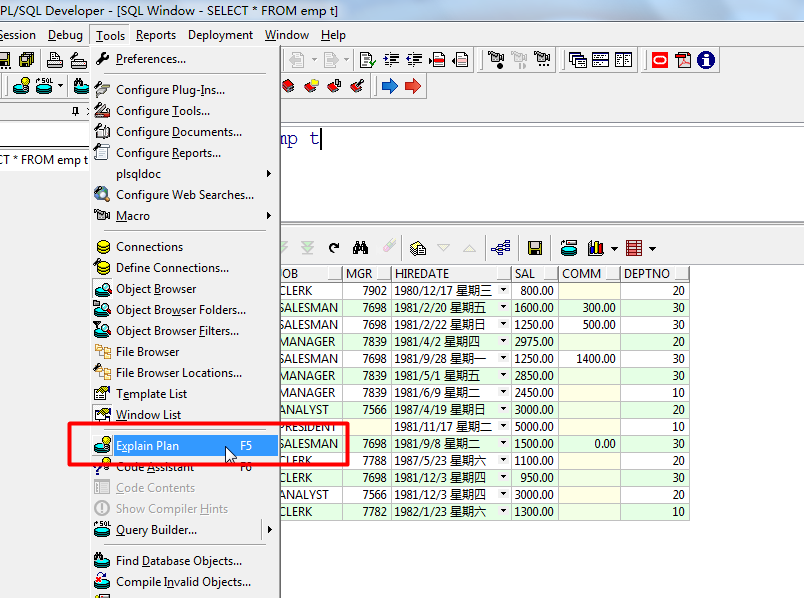
3)打开执行计划后,可以点击配置按钮进行显示配置。如图
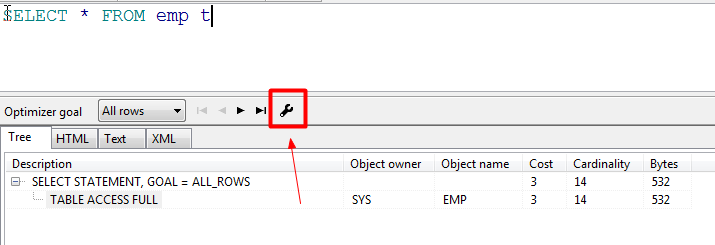
三、执行计划分析
1)执行顺序
根据下图中description列的缩进来判断,缩进最多的最先执行,缩进相同时,最上面的最先执行,可以通过点击图中箭头,查看执行顺序
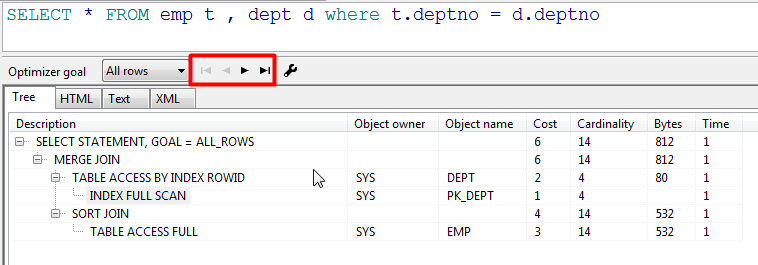
说明:
表访问方式
表访问的几种方式:(非全部)
- TABLE ACCESS FULL(全表扫描)
- TABLE ACCESS BY INDEX ROWID(通过ROWID的表存取)
- INDEX FULL SCAN(索引扫描)
如果sql关联的数据表数据量较大,使用全表扫描会影响交易性能,需要增加索引;
(1) TABLE ACCESS FULL(全表扫描):
Oracle会读取表中所有的行,并检查每一行是否满足SQL语句中的 Where 限制条件;
全表扫描时可以使用多块读(即一次I/O读取多块数据块)操作,提升吞吐量;
使用建议:数据量太大的表不建议使用全表扫描,除非本身需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上
(2) TABLE ACCESS BY ROWID(通过ROWID的表存取) :
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID可以快速定位到目标数据上,这也是Oracle中存取单行数据最快的方法;
(3) INDEX FULL SCAN(索引扫描):
索引扫描分五种:
- INDEX UNIQUE SCAN(索引唯一扫描)
- INDEX RANGE SCAN(索引范围扫描)
- INDEX FULL SCAN(索引全扫描)
- INDEX FAST FULL SCAN(索引快速扫描)
- INDEX SKIP SCAN(索引跳跃扫描)
a) INDEX UNIQUE SCAN(索引唯一扫描):
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录;
表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle常实现唯一性扫描;
b) INDEX RANGE SCAN(索引范围扫描):
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
c) INDEX FULL SCAN(索引全扫描):
进行全索引扫描时,查询出的数据都必须从索引中可以直接得到(注意全索引扫描只有在CBO模式下才有效)
d) INDEX FAST FULL SCAN(索引快速扫描):
扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
e) INDEX SKIP SCAN(索引跳跃扫描):
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
表连接方式
表(row source)之间的连接顺序对于查询效率有很大的影响,对首先存取的表(驱动表)先应用某些限制条件(Where过滤条件)以得到一个较小的row source,可以使得连接效率提高。
表连接的几种方式:
- SORT MERGE JOIN(排序-合并连接)
- NESTED LOOPS(嵌套循环)
- HASH JOIN(哈希连接)
- CARTESIAN PRODUCT(笛卡尔积)
(1) SORT MERGE JOIN(排序-合并连接):
排序-合并连接的表无驱动顺序,谁在前面都可以;
排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like
(2) NESTED LOOPS(嵌套循环):
row source 1 (即驱动表)中返回了 N 行数据,则 row source 2 也相应的会被全表遍历 N 次。
应尽可能使用限制条件(Where过滤条件)使驱动表(row source 1)返回的行数尽可能少,同时在匹配表(row source 2)的连接操作关联列上建立唯一索引(UNIQUE INDEX)或是选择性较好的非唯一索引,此时嵌套循环连接的执行效率会变得很高。若驱动表返回的行数较多,即使匹配表连接操作关联列上存在索引,连接效率也不会很高。
(3)HASH JOIN(哈希连接) :
哈希连接只适用于等值连接(即连接条件为 = )
