(3)Canal高可用集群
1.前言
在最近项目开中,为了减少前台搜索对数据库访问压力,入库的物料都需要同步一份数据到ES,让前台搜索直接访问ES,不直接访问数据库获取数据。一开始做法是代码串行先保存到数据库,再同步到ES。但是会有一个坑,如果两者其一保存数据不成功,就会导致数据库跟ES数据不一致,而且这种方式是对站点代码是有侵入式的。搜索相关资料发现阿里的canal这个增量数据订阅&消费的中间件可以无侵入式地有效解决该问题,canal伪造从库拉取mysql库每次修改binary log对象解析后,再通过MQ同步数据到ES。同时考虑系统健壮性,稳定性,所以把canal部署成高可用集群。
2. canal架构
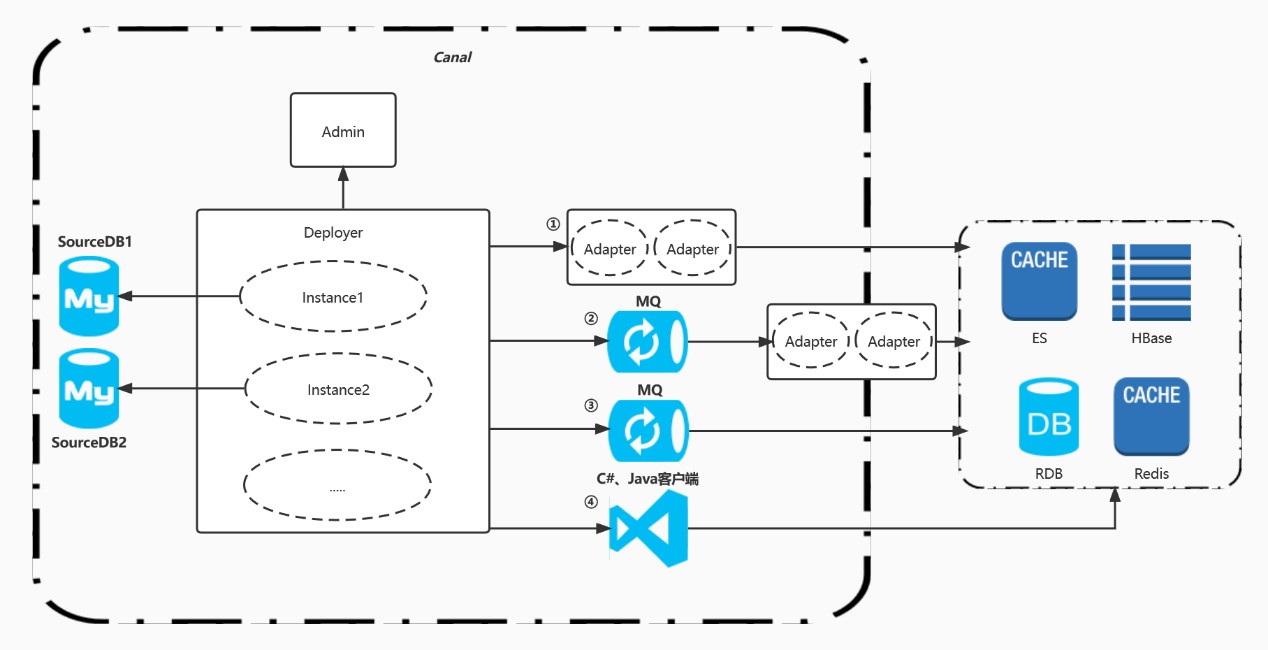
我特定查阅官网资料几遍,总体归纳canal架构如上几种(如有错误,请各位看官指正,谢谢)。而这次功能重构,鉴于目前公司现有技术栈,决定采用架构图③的架构进行重构。
2.1HA机制设计
canal的ha(双机集群)分为两部分,canal server和canal client分别有对应的ha实现:
●canal server:为了减少对mysql dump的请求,不同server上的实例(instance)要求同一时间只能有一个处于running,其他的处于standby状态。
●canal client:为了保证有序性,一份实例(instance)同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定),后续我会继续记录zookeeper学习过程。
Canal Server HA架构原理: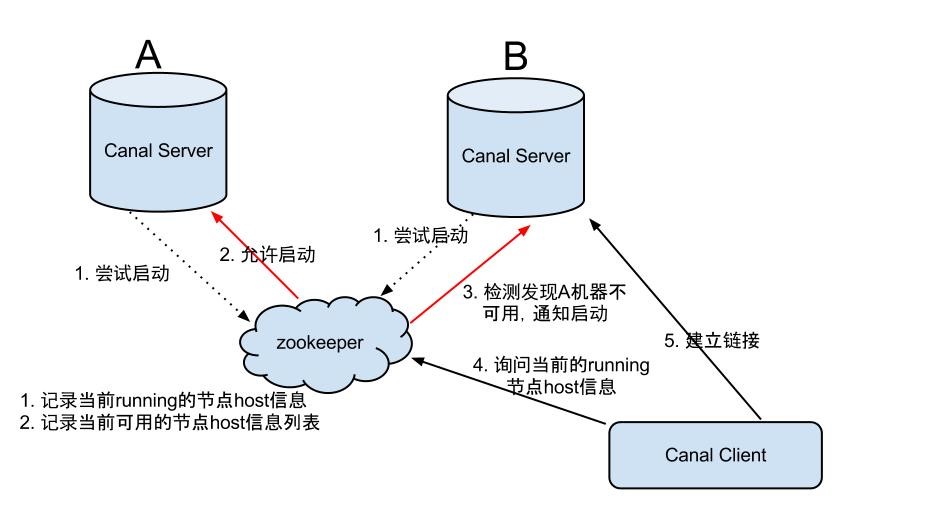
流程步骤:
1.canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断(实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)。
2.创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态。
3.一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance。
4.canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
注:canal client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制。
3.前期准备
3.1安装zookeeper
可以参考我这篇“Zookeeper在linux环境中搭建集群”文章或者百度教程安装。集群部署如下:
|
服务名称 |
IP/域名 |
端口 |
|
zookeeper(slave) |
192.168.142.129 |
2181 |
|
zookeeper(master) |
192.168.142.130 |
2181 |
|
zookeeper(slave) |
192.168.142.131 |
2181 |
3.2安装mysql
可以参考我这篇”MySQL进阶篇在linux环境下安装” 文章或者百度教程安装。MySQL我只部署单台:
|
服务名称 |
IP/域名 |
端口 |
|
mysql |
8.135.110.120(阿里云) |
3306 |
用户名:canal,密码:qwer1234
3.3安装mq(因为我公司是使用RabbitMQ,所以安装的是RabbitMQ)
可以参考我这篇“RabbitMQ在Docker上安装”文章或者百度教程安装。RabbitMQ我只部署单台:
|
服务名称 |
IP/域名 |
端口 |
|
rabbitmq |
8.135.110.120(阿里云) |
5672 |
管理后台登录账号:admin,密码:qwer1234
再新建一个队列用作演示:
Virtual hosts:/
交换器(Exchanges):canal.direct.test
路由key(Routing key):canal.routingkey.test
队列(Queues):canal.queue.test
3.4安装canal.server
可以参考我这篇“Canal入门”(这篇文章采用就是架构图④的架构)或者百度教程安装。集群部署如下:
|
服务名称 |
IP/域名 |
端口 |
|
canal.server01 |
192.168.142.129 |
11110 |
|
canal.server02 |
192.168.142.130 |
11110 |
两台canal.server实例我重新拷贝一份用作供应商报价业务,具体操作如下:
cp -r /home/deng/canal/canal.deployer/conf/example /home/deng/canal/canal.deployer/conf/quote_example
实例名称:quote_example
3.5其他依赖
JDK版本:java version "1.8.0_311"
4.启动canal集群
部署完canal.server两个服务后,集群想要生效,还需要同时修改两台服务的配置重新启动才可以,具体操作如下:
●编辑vi conf/ canal.properties文件
因为canal.server集群需要zookeeper,所以在“common argument”标题下找到canal.zkServers选项修改为zookeeper集群地址;然后把canal.serverMode选项修改为rabbitMQ类型:
canal.zkServers = 192.168.142.129:2181,192.168.142.130:2181,192.168.142.131:2181 canal.serverMode = rabbitMQ
同时canal需要MQ进行同步数据,所以在“RabbitMQ” 标题下找到rabbitmq配置进行修改:
rabbitmq.host = 8.135.110.120 rabbitmq.virtual.host = / rabbitmq.exchange = canal.direct.test rabbitmq.username = admin rabbitmq.password = qwer1234 rabbitmq.deliveryMode =
HA模式是依赖于instance name进行管理,必须都选择default-instance.xml配置。在“destinations”标题下找到canal.instance.global.spring.xml选项进行启用(其他两个选项注释):
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
注:canal是允许配置多个实例(instance),假设每个canal.server服务都有相同的两个实例(在conf目录下分别建两个实例文件夹:example1和example2,同时把默认实例example文件夹里的instance.properties文件拷贝一份过去),修改两个实例canal.properties配置就能使其生效,在“destinations”标题下找到canal.destinations选项修改如下:
canal.destinations = example1, example2
●编辑vi conf/example/instance.properties文件(如果是多实例,则每个实例目录下该文件都要修改配置,现在以canal.server01服务为例)
# mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 canal.instance.mysql.slaveId=129 # mysql数据库连接地址和端口 canal.instance.master.address=8.135.110.120:3306 # mysql数据库用户名和密码 canal.instance.dbUsername=canal canal.instance.dbPassword=qwer1234 # mq配置(如果是没用到MQ,则修改为实例名称即可) canal.mq.topic= example1 Or # mq配置(如果是用到MQ,则修改为mq路由key) canal.mq.topic=canal.routingkey.test
●启动canal.server服务
cd /home/deng/canal/canal.deployer
sh bin/startup.sh

●登录mysql增删改一条数据(创建一个供应商报价supplier_quote临时表)
INSERT ebs_material.supplier_quote (PN,Brand,StockQty) VALUES ('LM3585DT','TI',10000); UPDATE ebs_material.supplier_quote SET Brand='TS1' WHERE Id=1;
在RabbitMQ管理后台队列上会看到这两条语句待消费消息: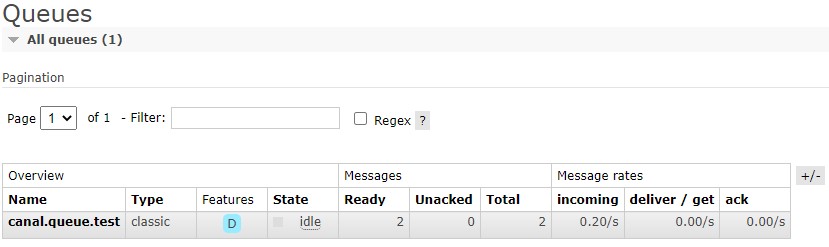

下面再来验证下canal集群是否成功。
●验证canal集群是否成功
首先把canal.server01停止运行(也可以停止canal.server02运行,随便一个都可以):
sh bin/stop.sh

查看日志:
从上述截图可以看到129虚拟机canal.server01服务已经关闭了。现在在数据库再插入一条报价数据:
INSERT ebs_material.supplier_quote (PN,Brand,StockQty) VALUES ('BAV999','TI',10000);
再查看下RabbitMQ管理后台队列有没有新增一条待消费的消息: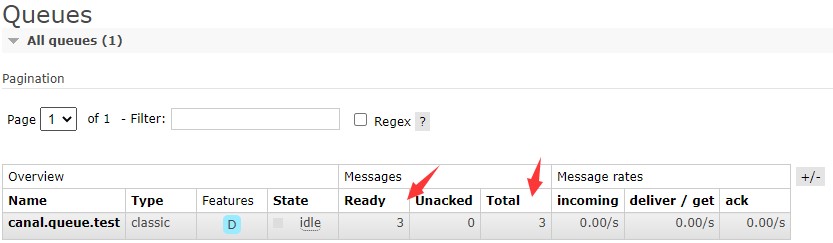

由此可见,已经新增一条待消费的消息,证明canal集群部署成功!
5.小结
在部署集群过程中偶尔会发生canal集群没有推送MQ消费情况,需要重新启动canal.server服务才生效,不知道是因为canal内部集成对rabbitmq不友好还是怎么的,后续测试排查下问题。该章节主要介绍如何搭建canal高可用集群,后续我们会深入了解内部原理跟其他功能。
参考文献:
AdminGuide
简介

 浙公网安备 33010602011771号
浙公网安备 33010602011771号