(1)Canal入门
1.前言
在我们系统开发过程中,根据业务场景很多数据库数据并不会直接给用户访问的,需要同步保存到ElasticSearch、Redis等存储应用当中(例如最常见的是搜索页面的ElasticSearch数据)。而阿里开源的框架Canal就是做这方面的功能,它可以把数据库(暂时只支持MySQL和Oracle部分版本)日志解析获取增量变更同步到其他存储应用去。
2.什么是Canal?
官网介绍,canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。
从上述介绍我们可以简单认为Canal就是一个简单的增量数据同步工具。
2.1MySQL主备复制原理
根据官网介绍,MySQL主备复制原理如下:

●MySQL master(主库)将数据变更(增删改)写入二进制日志(binary log,其中记录叫做二进制日志事件binary log events,可以通过show binlog events进行查看)。
●MySQL slave(从库)将master的binary log events 拷贝到它的中继日志(relay log)。
●MySQL slave(从库)重放relay log中事件,将数据变更反映它自己的数据。
2.2Canal工作原理
根据官网介绍,Canal工作原理如下图所示:
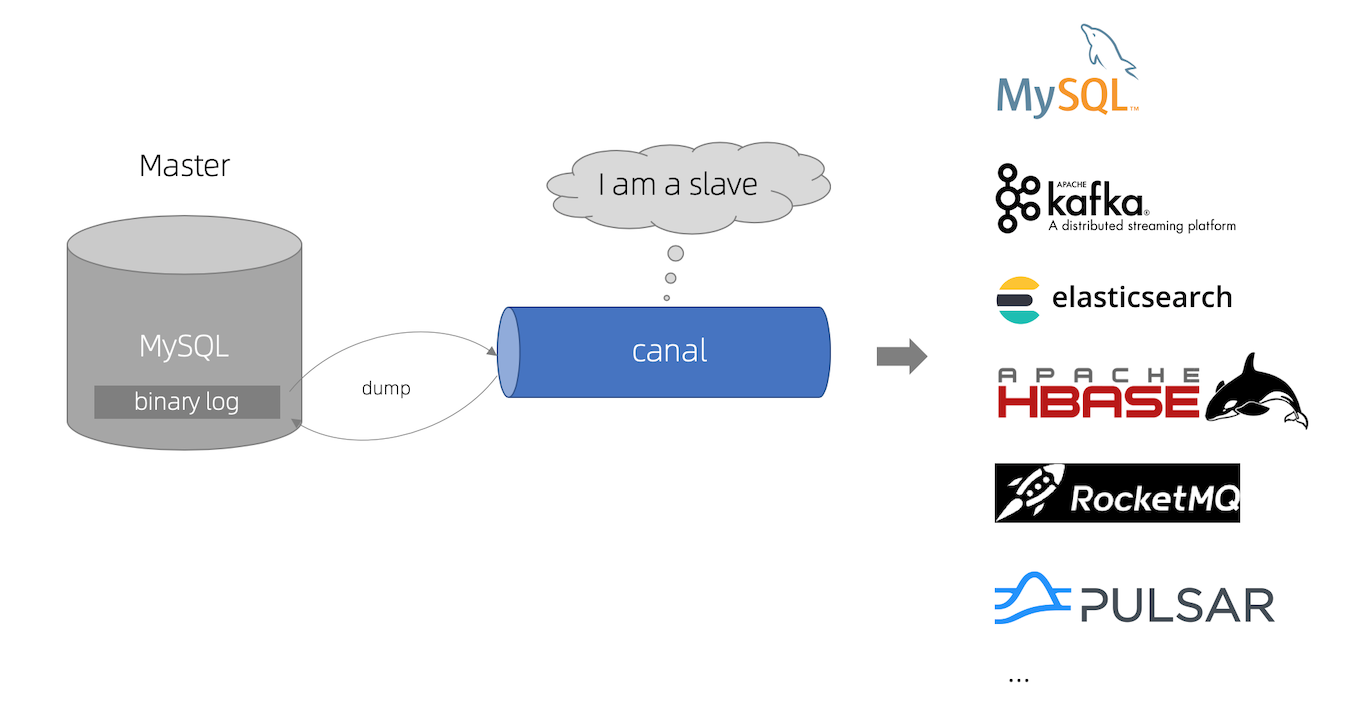
●canal模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议。
●MySQL master收到dump请求,开始推送binary log给slave(即canal )。
●canal解析binary log对象(原始为byte流),再推送到MySQL、kafka、ElasticSearch等存储应用当中。
3.Canal能做什么?
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务trigger(触发器)获取增量变更。从2010年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。所以Canal就是在这个场景中诞生的,它主要作用就是解决基于日志增量订阅和消费的业务,例如:
●数据库镜像。
●数据库实时备份。
●索引构建和实时维护(拆分异构索引、倒排索引等)。
●业务缓存刷新。
●带业务逻辑的增量数据处理(例如ElasticSearch、Redis数据同步)。
在我做过的项目中,cancal经常被用到如下场景:
●根据数据库的数据变更实时更新搜索引擎数据,比如我司电商场景下物料数据发生变更(例如后台上传更新物料信息、价格),实时同步到搜索引擎Elasticsearch上。
●根据数据库的数据变更实时更新缓存,比如专门运营人员每次修改物料品牌信息同时都会同步到Redis上。
●根据数据库的数据变更实时推送到消息队列,比如为了丰富自身系统物料库存,定时作业拉取第三方渠道物料库存推送到RabbitMQ等消息队列去消费入库。
4.如何搭建Canal?
4.1首先得安装个MySQL数据库
如果已经安装好MySQL数据库的,这一步可以跳过,如果没有安装好,请自行安装(也可以查看我之前写过一篇MySQL安装教程,不过个人建议最好还是在Docker上安装,简单方便快捷,如果自己手动安装,不懂点运维基础知识,坑太多了),具体安装教程度娘一堆资料。当前的canal支持MySQL版本包括5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
我的MySQL版本是8.0.23,所以canal是支持的。不知道自己安装是什么版本可以通过SELECT VERSION();命令查看。
4.2数据库配置
从上述可知,因为canal是模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议获取binary log内容对象的,所以需要MySql开启binlog。
●修改mysql.cnf中的配置:
-- 编辑mysql.cnf文件 vim /etc/my.cnf; -- 在my.cnf上加入如下配置 [mysqld] log-bin=mysql-bin #开启binlog binlog-format=ROW #选择ROW模式 server_id=1 #配置MySQL replaction需要定义,不要和canal的slaveId重复 expire-logs-days=10 #binlog日志保留的天数,清除超过10天的日志,防止日志文件过大,导致磁盘空间不足
●授权canal链接MySQL账号具有作为MySQL slave的权限, 如果已有账户可直接grant(我这边是根据官网示例创建一个canal账号来演示):
-- 先登录MySQL mysql -u root -p -- 创建用户,用户名:canal,密码:qwer1234 CREATE USER canal IDENTIFIED BY 'qwer1234'; -- 授予上的所有权限给canal用户; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- 刷新权限; FLUSH PRIVILEGES;
●查看下MySql是否开启binlog日志
是否开启binlog日志:
SHOW VARIABLES LIKE 'log_bin';

查看binlog日志文件列表:
SHOW BINARY LOGS;

查看当前正在写入的binlog文件:
SHOW MASTER STATUS;

4.3Canal配置
安装运行Canal服务端,一定要记得先检查当前Linux系统是否安装了java8环境,如果没有安装启动Canal时候会有如下提示:
[root@dengwu canal]# sh bin/startup.sh which: no java in (/data/mysql/bin:/data/mysql/lib:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin) Cannot find a Java JDK. Please set either set JAVA or put java (>=1.5) in your PATH.

具体安装步骤如下:
●先从Oracle官网下载JDK安装包:

通过Xftp工具导入到预先创建/app/package安装包目录下,再在/usr目录下创建java目录并解压:
mkdir /usr/java cd /app/package tar zxvf jdk-8u291-linux-x64.tar.gz -C /usr/java
然后配置java环境变量:
vim /etc/profile
用vim编辑器来编辑profile文件,输入i在文件末尾添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_291 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin export PATH=$PATH:${JAVA_PATH}
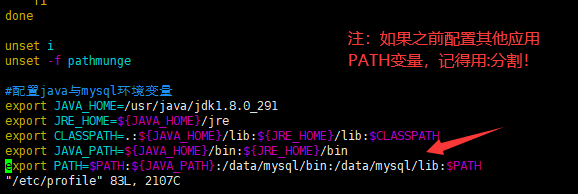
配置完java环境变量后,:wq保存退出,看看是否生效:
echo $PATH
如果没有生效,让其生效:
source /etc/profile
再瞄瞄java8是否安装成功:
java -version

●然后下载canal, 访问release页面, 选择需要的包下载, 如最新版本1.1.5为例:
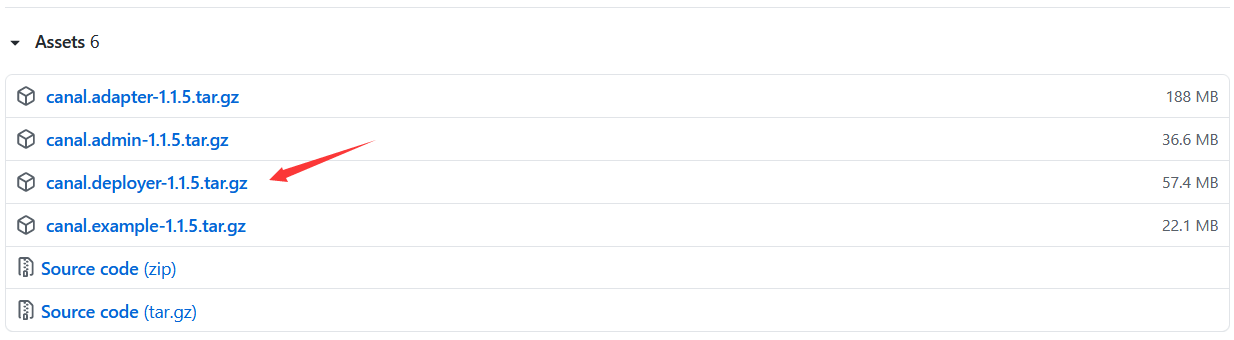
可以使用wget工具下载:
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
或者手动下载,通过Xftp等工具拉入安装包目录(/app/package)中:

再创建canal安装目录解压安装包:
mkdir /app/canal cd /app/package tar zxvf canal.deployer-1.1.5.tar.gz -C /app/canal
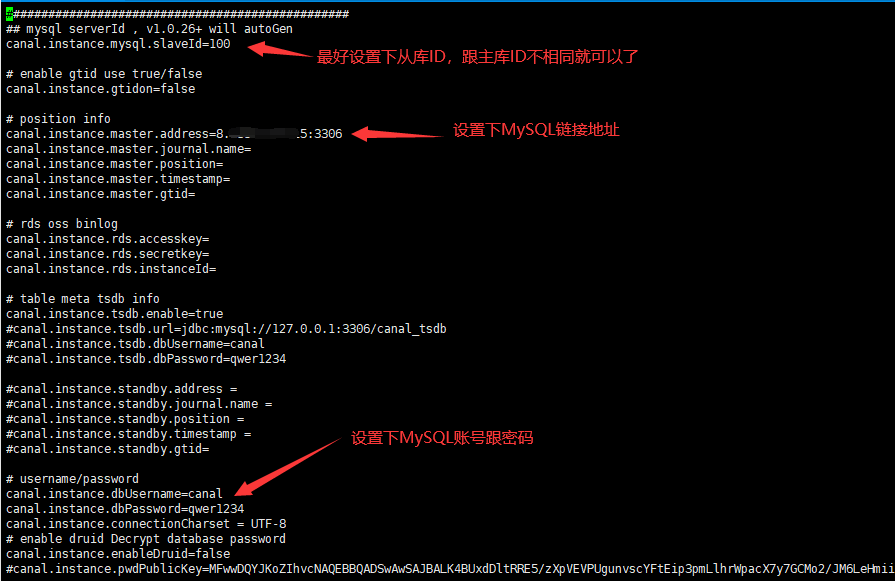
然后修改配置:
cd /app/canal vi conf/example/instance.properties i :wq
●启动canal:
cd /app/canal
sh bin/startup.sh
注:Windows使用startup.bat启动
●查看canal进程是否启动成功:
ps -ef | grep canal
●查看instance的日志:
vi logs/example/example.log
●关闭canal:
sh bin/stop.sh
●在数据库中查看从库信息:
SHOW SLAVE HOSTS;

查看下canal实例(example)配置是否成功。
●记得把canal端口加入防火墙策略去:
-- 允许通过防火墙 firewall-cmd --permanent --zone=public --add-port=11111/tcp -- 从防火墙里移除 firewall-cmd --permanent --zone=public --remove-port=11111/tcp -- 查看端口在防火墙状态 firewall-cmd --permanent --zone=public --query-port=11111/tcp -- 重启防火墙 firewall-cmd --reload
注:如果是买阿里云服务器,要到阿里云安全组添加允许通过策略。还有Canal Server的默认端口为:11111,若需要修改,可以去/canal/conf目录下的canal.properties配置文件中进行修改。
5.Canal的.NET客户端CanalSharp使用
5.1快速入门
●先安装客户端:
Install-Package CanalSharp
●初始化日志:
CanalSharp使用Microsoft.Extensions.Logging.Abstractions,因为目前主流日志组件,如:nlog、serilog等,全部支持此日志抽象接入,也就是说你可以通过安装nlog、serilog对其的适配,来使用它们,无论是Console App或则是Web App。
var loggerFactory = LoggerFactory.Create(builder => { builder .AddFilter("Microsoft", LogLevel.Debug) .AddFilter("System", LogLevel.Information) .AddConsole(); }); var logger= loggerFactory.CreateLogger<SimpleCanalConnection>();
●创建连接:
var conn=new SimpleCanalConnection(new SimpleCanalOptions("127.0.0.1",11111,1234),logger); await conn.ConnectAsync();//连接到Canal Server await conn.SubscribeAsync();//订阅
●获取数据:
var msg = await conn.GetAsync(1024);
5.2进阶使用
●解析数据
○Entry
上文conn.GetAsync()返回的是一个Entry集合,Entry对应binlog记录,它可能是事务标记也有可能是行数据变化,通过Entry.EntryType来区分,一般事务的标记在业务消费处理时不需要处理。
示例:
var entries = await conn.GetAsync(1024); foreach (var entry in entries) { //不处理事务标记 if (entry.EntryType == EntryType.Transactionbegin || entry.EntryType == EntryType.Transactionend) { continue; } }
Entry.Header包含了一些binlog以及数据库信息:
|
属性 |
说明 |
|
Entry.Header.LogfileName |
binlog文件名 |
|
Entry.Header.LogfileOffset |
binlog偏移 |
|
Entry.Header.SchemaName |
mysql schema名称 |
|
Entry.Header.TableName |
表名 |
○RowChange
一般在业务处理中,都会需要行数据的变更,将Entry转换为RowChange对象。
示例:
RowChange rowChange = null; try { rowChange = RowChange.Parser.ParseFrom(entry.StoreValue); } catch (Exception e) { _logger.LogError(e); }
通过RowChange.EventType来Row是什么变化,Update、Delete和Insert对应sql中的update、delete和insert语句,通过RowChange.RowDatas属性,来访问RowChange对象中包含的行变化数据集合。示例,遍历 RowChange 中的行数据:
foreach (var rowData in rowChange.RowDatas) { //删除的数据 if (eventType == EventType.Delete) { PrintColumn(rowData.BeforeColumns.ToList()); } //插入的数据 else if (eventType == EventType.Insert) { PrintColumn(rowData.AfterColumns.ToList()); } //更新的数据 else { _logger.LogInformation("-------> before"); PrintColumn(rowData.BeforeColumns.ToList()); _logger.LogInformation("-------> after"); PrintColumn(rowData.AfterColumns.ToList()); } } private static void PrintColumn(List<Column> columns) { foreach (var column in columns) { Console.WriteLine($"{column.Name} : {column.Value} update= {column.Updated}"); } }
○Column
Column如其名,代表数据库中表的每一列的信息:
|
属性名 |
说明 |
|
Column.Name |
列名 |
|
Column.Value |
列的值 |
|
Column.Updated |
列是否被更新 |
5.3应答机制
应答机制可以保证消费数据的准确性,Canal服务端会记录Client消费的进度,需要客户端发送ACK消息,服务端才会更新进度。类似于在消息队列中的ACK机制,如RabbitMQ。
●自动应答
await conn.GetAsync(1024);//获取数据并自动应答 GetAsync()会在获取数据后,自动向Server发送ack消息。
●手动应答
var msg = await conn.GetWithoutAckAsync(1024);//获取数据 await conn.AckAsync(msg.Id);//手动应答 await conn.RollbackAsync(msg.Id);//回滚
5.4高可用
这里的高可用分为两类,客户端集群和服务端集群。都是采用冷备模式,因为对于binlog数据消费来说,并行处理将会带来数据顺序错乱的问题,当然你可以通过一些复杂的机制去实现,这里不做说明。集群部署需要Zookeeper组件。
●服务端集群
在conf/canal.properties文件中修改zookeeper地址:
canal.zkServers=127.0.0.1:2181
集群中每个实例需配置相同的zookeeper地址。
●客户端集群
客户端集群和服务端集群采用相同的模式,每个实例去抢占锁,获得了锁那么这个实例就运行获取数据,其他实例做冷备。若正在运行消费数据的实例由于网络波动,导致和zookeeper失去连接,那么其他客户端实例不会立即抢占,会等待60s后才执行抢占,给与这个实例恢复的机会。
客户端集群使用的连接对象和快速入门中的不同:ClusterCanalConnection,但使用方法基本相同。
示例:
//初始化日志 var loggerFactory = LoggerFactory.Create(builder => { builder .AddFilter("Microsoft", LogLevel.Debug) .AddFilter("System", LogLevel.Information) .AddConsole(); }); var logger = loggerFactory.CreateLogger<Program>(); //设置zk地址和clientid,统一集群的client必须相同 var conn = new ClusterCanalConnection( new ClusterCanalOptions("localhost:2181", "12350"),loggerFactory); //连接到Server await conn.ConnectAsync(); //订阅 await conn.SubscribeAsync(); await conn.RollbackAsync(0); while (true) { try { //获取数据 var msg = await conn.GetAsync(1024); } catch (Exception e) { _logger.LogError(e,"Error."); //发生异常执行重连,此方法只有集群连接对象才有 await conn.ReConnectAsync(); } }
5.5订阅
订阅指过滤表(table)的规则,Canal客户端发送给客户端订阅规则,那么服务端将会推送符合规则的表数据过来,采用正则匹配。
允许所有表:.\*\\\\..\*
6.小结
这里这是简单介绍Canal工作原理,能做什么,还有.NET客户端CanalSharp使用,其实Canal涉及知识点还是很多的,例如配置MQ模式、服务集群、Web管理界面部署,多实例等等。后面如果有时间,我还会继续花时间去学习。
参考文献:
CanalSharp文档
CanalSharp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号