


mysql数据库隔离级别及其原理、Spring的7种事物传播行为
一、事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。分为强一致性(银行转账)、弱一致性、最终一致性等
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
二、事务的并发问题
1、脏读:一个事务读取另外一个事务还没有提交的数据叫脏读【针对未提交的数据】
2、不可重复读:即在同一个事务内,两个相同的查询返回了不同的结果【读取数据本身的对比】
表tms_message_info数据:
ID file_name
1 1111.SND
2 2222.SND
| 事务A READ-COMMITTED | 事务B READ-COMMITTED |
|
start transaction; select * from tms_message_info where id='1' |
start transaction;-- 开启事务 update tms_message_info set FILE_NAME='666.SND' where ID='1'; 未提交 |
| B事务未提交前,A事务执行上述查询,得到的文件名结果为1111.SND | commit; B 事务提交 |
| B事务提交后,A事务在执行查询,结果发生变化,文件名变为666.SND,即同一事务查询结果不同,即不可重复读 |
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
【同一事务A多次查询,若另一事务B只是update,则A事务多次查询结果相同;若B事务insert/delete数据,则A事务多次查询就会发现新增或缺少数据,出现幻读,即幻读关注读取结果集条数变化】
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
三、MySQL事务隔离级别
1、读不提交(Read Uncommited,RU)
这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用。
2、读提交(Read commited,RC)
本事务读取到的是最新的数据(其他事务提交后的)。问题是,在同一个事务里,前后两次相同的SELECT会读到不同的结果(不重复读)
3、可重复读(Repeatable Read,RR)【MySQL 默认的级别】
在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同一个事务同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象
4、 串行化(SERIALIZABLE)。读操作会隐式获取共享锁,可以保证不同事务间的互斥

四、4种隔离级别的相应原理总结如下:
READ_UNCOMMITED 的原理:
- 事务对当前被读取的数据不加锁;
- 事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级共享锁,直到事务结束才释放。
表现:
- 事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,能读到事务2对该记录的修改版本,即使该修改尚未被提交。
- 事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
READ_COMMITED 的原理:
- 事务对当前被读取的数据加 行级共享锁(当读到时才加锁),一旦读完该行,立即释放该行级共享锁;
- 事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
表现:
- 事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的只能是事务2对其更新前的版本,要不就是事务2提交后的版本。
- 事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
REPEATABLE READ 的原理:
- 事务在读取某数据的瞬间(就是开始读取的瞬间),必须先对其加 行级共享锁,直到事务结束才释放;
- 事务在更新某数据的瞬间(就是发生更新的瞬间),必须先对其加 行级排他锁,直到事务结束才释放。
表现:
- 事务1读取某行记录时,事务2也能对这行记录进行读取、更新;当事务2对该记录进行更新时,事务1再次读取该记录,读到的仍然是第一次读取的那个版本。
- 事务1更新某行记录时,事务2不能对这行记录做更新,直到事务1结束。
SERIALIZABLE 的原理:
- 事务在读取数据时,必须先对其加 表级共享锁 ,直到事务结束才释放;
- 事务在更新数据时,必须先对其加 表级排他锁 ,直到事务结束才释放。
表现:
- 事务1正在读取A表中的记录时,则事务2也能读取A表,但不能对A表做更新、新增、删除,直到事务1结束。
- 事务1正在更新A表中的记录时,则事务2不能读取A表的任意记录,更不可能对A表做更新、新增、删除,直到事务1结束。
注释:
1、共享锁:称为读锁,简称S锁,顾名思义,共享锁就是如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。共享锁也属于悲观锁的一种
2、排他锁:又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他所并存,如一个事务获取了一个数据行的排他锁,其他事务就不能给该数据加其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
ps:对于update,insert,delete语句会自动加排它锁)。添加排它锁与添加共享锁类似,执行语句添加 “ for update” 即可。
对于共享锁大家可能很好理解,就是多个事务只能读数据不能改数据,对于排他锁大家的理解可能就有些差别,我当初就犯了一个错误,以为排他锁锁住一行数据后,其他事务就不能读取和修改该行数据,其实不是这样的。排他锁指的是一个事务在一行数据加上排他锁后,其他事务不能再在其上加其他的锁。mysql InnoDB引擎默认的修改数据语句,update,delete,insert都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果加排他锁可以使用select ...for update语句,加共享锁可以使用select ... lock in share mode语句。所以加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select ...from...查询数据,因为普通查询没有任何锁机制。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中同步锁synchronized和重入锁ReentrantLock等独占锁就是悲观锁思想的实现。
共享锁和排他锁也是悲观锁
(另外:同步锁synchronized和重入锁ReentrantLock的相同点与不同点:
相同点:1)ReentrantLock和synchronized都是独占锁,只允许线程互斥的访问临界区
2)ReentrantLock和synchronized都是可重入的
不同点:1)ReentrantLock可以实现公平锁。公平锁是指当锁可用时,在锁上等待时间最长的线程将获得锁的使用权。而非公平锁则随机分配这种使用权。默认情况下二者都是非公平锁,但是ReentrantLock可以设置为公平锁
2)ReentrantLock可响应中断。当使用synchronized实现锁时,阻塞在锁上的线程除非获得锁否则将一直等待下去,也就是说这种无限等待获取锁的行为无法被中断。而ReentrantLock给我们提供了一个可以响应中断的获取锁的方法
lockInterruptibly()。该方法可以用来解决死锁问题。
3)获取锁时限时等待。ReentrantLock还给我们提供了获取锁限时等待的方法tryLock(),可以选择传入时间参数,表示等待指定的时间,无参则表示立即返回锁申请的结果:true表示获取锁成功,false表示获取锁失败。我们可以使用该方法配合失败重试机制 来更好的解决死锁问题。
4)结合Condition实现等待通知机制。



Condition接口在使用前必须先调用ReentrantLock的lock()方法获得锁。之后调用Condition接口的await()将释放锁,并且在该Condition上等待,直到有其他线程调用Condition的signal()方法唤醒线程。使用方式和wait,notify类似 public class ConditionTest { static ReentrantLock lock = new ReentrantLock(); static Condition condition = lock.newCondition(); public static void main(String[] args) throws InterruptedException { lock.lock(); new Thread(new SignalThread()).start(); System.out.println("主线程等待通知"); try { condition.await(); } finally { lock.unlock(); } System.out.println("主线程恢复运行"); } static class SignalThread implements Runnable { @Override public void run() { lock.lock(); try { condition.signal(); System.out.println("子线程通知"); } finally { lock.unlock(); } } } } //执行结果 主线程等待通知 子线程通知 主线程恢复运行
)
乐观锁:所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。
方法1:加版本号
1.查询出商品信息 select (status,status,version) from t_goods where id=#{id} 2.根据商品信息生成订单 3.修改商品status为2 update t_goods set status=2,version=version+1 where id=#{id} and version=#{version};
方法2:cas算法(即比较与交换):一种无锁算法
CAS算法涉及到三个操作数
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
乐观锁缺点:1)ABA问题:如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 "ABA"问题。
2)自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销
3)只能保证一个共享变量的原子操作
另外:CAS(乐观锁)与synchronized(悲观锁)的使用情景
简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
1)对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2)对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
注意:mysql的update、delete、insert是默认加了排他锁的,而普通的selete是什么锁都没加,所以普通selete既能查共享锁的行也能查排他锁的行
参考:https://www.cnblogs.com/lyftest/p/7687747.html,https://www.cnblogs.com/lyftest/p/7687747.html
https://blog.csdn.net/weixin_39666581/article/details/87008846
https://blog.csdn.net/u013030086/article/details/86492335
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Spring的7种事物传播行为:
参考:https://segmentfault.com/a/1190000013341344
Spring有7中事物传播行为:由@Transaction(Propagation=XXX)设置决定:
1)REQUIRED(required):如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。即:不管内部事物还是外部事物,只要发生异常,全部回滚,默认是这种传播
2)REQUIRES_NEW(requires_new):新建事务,如果当前存在事务,把当前事务挂起。
3)SUPPORTS(supports):支持当前事物,如果没有事物,就以非事物方式执行。
4)MANDATORY(mandatory):使用当前事物,没有就抛出异常
5)NOT_SUPPORTED(not_supported):使用非事物的方式执行,如果当前存在事物,就把当前事物挂起
6)NEVER(never):以非事物方式执行,如果当前事物存在,则抛出异常
7)NESTED(nested):如果当前存在事物,则嵌套事物内部执行;如果当前没有事物,则执行与PROPAGATION_REQUIRED类似操作
https://segmentfault.com/a/1190000013341344
REQUIRED,REQUIRES_NEW,NESTED异同
NESTED和REQUIRED修饰的内部方法都属于外围方法事务,如果外围方法抛出异常,这两种方法的事务都会被回滚。但是REQUIRED是加入外围方法事务,所以和外围事务同属于一个事务,一旦REQUIRED事务抛出异常被回滚,外围方法事务也将被回滚。而NESTED是外围方法的子事务,有单独的保存点,所以NESTED方法抛出异常被回滚,不会影响到外围方法的事务。
NESTED和REQUIRES_NEW都可以做到内部方法事务回滚而不影响外围方法事务。但是因为NESTED是嵌套事务,所以外围方法回滚之后,作为外围方法事务的子事务也会被回滚。而REQUIRES_NEW是通过开启新的事务实现的,内部事务和外围事务是两个事务,外围事务回滚不会影响内部事务。
事务可以分为编程式事务和声明式事务。
关于声明式事物@Transactional两个注意事项
1、在Service层抛出Exception,在Controller层捕获,那如果在Service中有异常,那会事务回滚吗?
结论:如果是编译时异常不会自动回滚,如果是运行时异常,那会自动回滚!
2、如果我在当前类下使用一个没有事务的方法去调用一个有事务的方法,那我们这次调用会怎么样?是否会有事务呢?
结论:如果是在同一个service中(即在同一个@Service下),一个没有事物的方法调用一个有事物的方法,那么事物不会生效;如果不再同一个service中(即在不同的@Service),则会生效。
原因:
我们都知道,带有@Transactional注解所包围的方法就能被Spring事务管理起来,那如果我在当前类下使用一个没有事务的方法去调用一个有事务的方法,那我们这次调用会怎么样?是否会有事务呢?
用代码来描述一下:
// 没有事务的方法去调用有事务的方法 public Employee addEmployee2Controller() throws Exception { return this.addEmployee(); } @Transactional public Employee addEmployee() throws Exception { employeeRepository.deleteAll(); Employee employee = new Employee("3y", 23); // 模拟异常 int i = 1 / 0; return employee; }
我第一直觉是:这跟Spring事务的传播机制有关吧。
其实这跟Spring事务的传播机制没有关系,下面我讲述一下:
-
Spring事务管理用的是AOP,AOP底层用的是动态代理。所以如果我们在类或者方法上标注注解
@Transactional,那么会生成一个代理对象。
接下来我用图来说明一下:
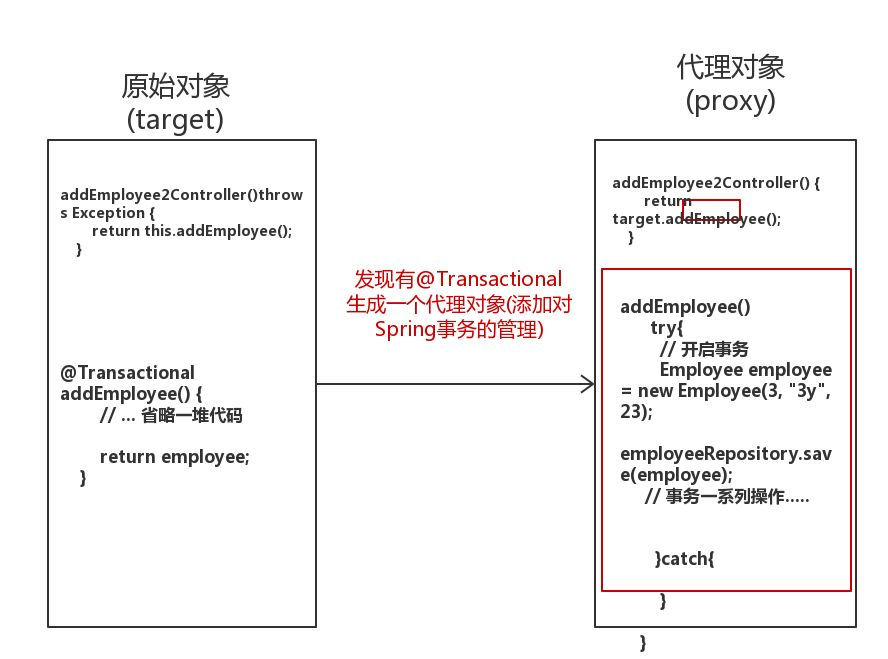
显然地,我们拿到的是代理(Proxy)对象,调用addEmployee2Controller()方法,而addEmployee2Controller()方法的逻辑是target.addEmployee(),调用回原始对象(target)的addEmployee()。所以这次的调用压根就没有事务存在,更谈不上说Spring事务传播机制了。
从上面的测试我们可以发现:如果是在本类中没有事务的方法来调用标注注解@Transactional方法,最后的结论是没有事务的。那如果我将这个标注注解的方法移到别的Service对象上,有没有事务?
@Service public class TestService { @Autowired private EmployeeRepository employeeRepository; @Transactional public Employee addEmployee() throws Exception { employeeRepository.deleteAll(); Employee employee = new Employee("3y", 23); // 模拟异常 int i = 1 / 0; return employee; } } @Service public class EmployeeService { @Autowired private TestService testService; // 没有事务的方法去调用别的类有事务的方法 public Employee addEmployee2Controller() throws Exception { return testService.addEmployee(); } }
这时就会有事务了。
因为我们用的是代理对象(Proxy)去调用addEmployee()方法,那就当然有事务了。
注意注意:
在同一个类中,一个方法调用另外一个有注解(比如@Async,@Transational)的方法,注解是不会生效的
Test1ServiceImpl事务回滚,而Test2ServiceImpl不回滚,并且Test1ServiceImpl发生异常才写入Test2ServiceImpl |
@Service@Slf4jpublic class Test1ServiceImpl implements Test1Service { @Autowired private Test2Service test2Service; @Transactional(rollbackFor = Exception.class) public HttpMessageResult<?> auditTest() { try { // 修改risk_case_base RiskCaseBaseExample ex1 = new RiskCaseBaseExample(); Criteria criteria = ex1.createCriteria(); criteria.andCaseNoEqualTo("XXXXXXXXX"); RiskCaseBase riskCaseBase = new RiskCaseBase(); riskCaseBase.setEventName("test7"); riskCaseBaseMapper.updateByExampleSelective(riskCaseBase, ex1); riskCaseBaseOrderMapper.updateByExampleSelective(riskCaseBaseOrder, ex2); //模拟异常 int[] array = {0,1}; int a = array[5]; } catch (Exception e) { // TODO: handle exception test2Service.updateRiskCaseBaseOrder(); log.error("已经捕获异常!!!"); throw e; } return HttpMessageResult.success(); }} @Servicepublic class Test2ServiceImpl implements Test2Service{ @Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRES_NEW) public void updateRiskCaseBaseOrder() { RiskCaseBaseOrderExample ex2 = new RiskCaseBaseOrderExample(); com.shizhuang.duapp.caseBase.model.RiskCaseBaseOrderExample.Criteria criteria2 = ex2.createCriteria(); criteria2.andOrderNoEqualTo("XXXXXXXX"); RiskCaseBaseOrder riskCaseBaseOrder = new RiskCaseBaseOrder(); riskCaseBaseOrder.setBuyerName("testBuyerName7"); riskCaseBaseOrderMapper.updateByExampleSelective(riskCaseBaseOrder, ex2); }} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具