

一、简介:
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。
二、具体步骤
(1)收集数据:采用各种方法收集数据
(2)准备数据:因为需要计算距离,所以数据类型应该是数值型,最好是结构化数据格式;
(3)分析数据:通过业务的角度或者其他的方法分析数据;
(4)训练算法:这是关键的一步,训练的目的是找到最佳的分类回归系数;
(5)测试算法:训练完成,将数据投入模型进行测试;
(6)使用算法:将需要的数据进行处理成适合模型的结构化数据;
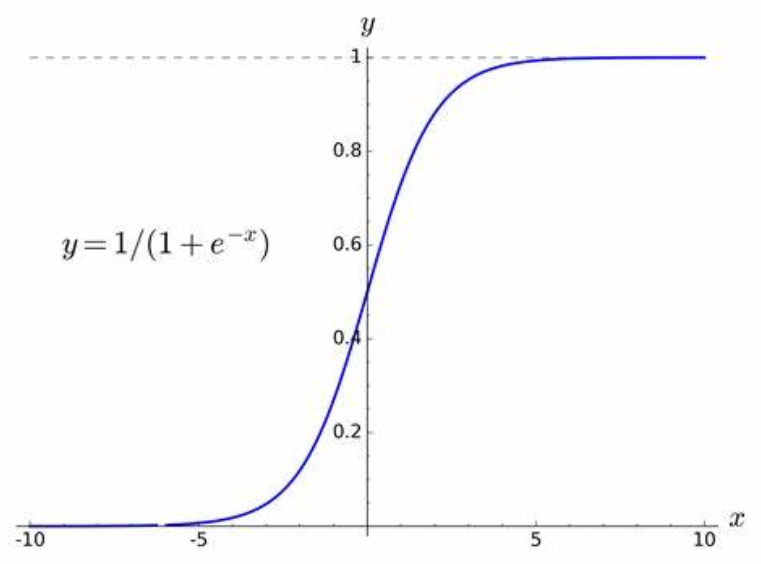
三、sigmoid 激活函数
Sigmoid 函数就可以帮助你将输入转换到区间【0,1】上,使你可以根据输入x得到的输出概率更好进行分类。
四、梯度上升法
梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇,则函数f(x,y)的梯度由下式表示:
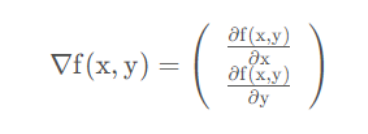
五、实现Logistic回归
1、数据集的准备
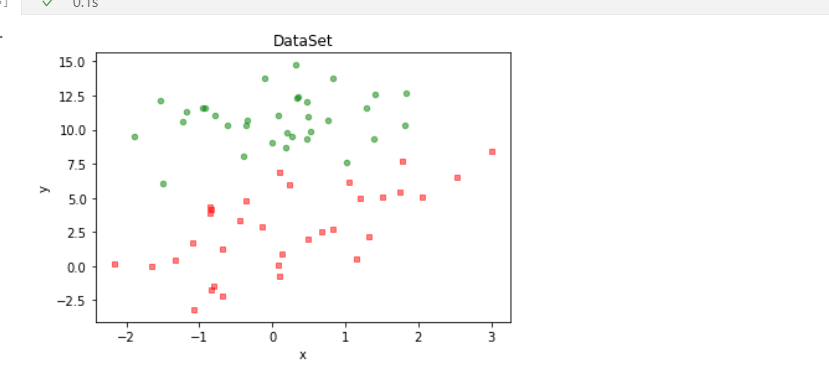
此数据集分为三列,第一列为x轴数据,第二列为y轴数据,第三列则为分类标签。根据标签的不同,对这些点进行分类。
2、加载数据
点击查看代码
import random
import numpy as np
import matplotlib.pyplot as plt
from numpy import shape, ones, array
#函数说明:加载数据
def loadDataSet():
dataMat = [] #创建数据列表
labelMat = [] #创建标签列表
fr = open('testSet.txt') #打开文件
for line in fr.readlines(): #逐行读取
lineArr = line.strip().split() #去回车,放入列表
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据
labelMat.append(int(lineArr[2])) #添加标签
fr.close() #关闭文件
return dataMat, labelMat #返回
#函数说明:绘制数据集散点图
def plotDataSet():
dataMat, labelMat = loadDataSet() #加载数据集
dataArr = np.array(dataMat) #转换成numpy的array数组
n = np.shape(dataMat)[0] #数据个数
xcord1 = []; ycord1 = [] #正样本
xcord2 = []; ycord2 = [] #负样本
for i in range(n): #根据数据集标签进行分类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
plt.title('DataSet') #绘制title
plt.xlabel('x'); plt.ylabel('y') #绘制label
plt.show() #显示
if __name__ == '__main__':
plotDataSet()
3、使用梯度上升法求出最佳参数
点击查看代码
#函数说明:sigmoid函数
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
#函数说明:梯度上升算法
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
alpha = 0.001 #移动步长,也就是学习速率,控制更新的幅度。
maxCycles = 500 #最大迭代次数
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() #将矩阵转换为数组,返回权重数组
if __name__ == '__main__':
dataMat, labelMat = loadDataSet()
print(gradAscent(dataMat, labelMat))
4、根据得出的特征值绘制预测函数的图像:
点击查看代码
def plotBestFit(weights):
dataMat, labelMat = loadDataSet() #加载数据集
dataArr = np.array(dataMat) #转换成numpy的array数组
n = np.shape(dataMat)[0] #数据个数
xcord1 = []; ycord1 = [] #正样本
xcord2 = []; ycord2 = [] #负样本
for i in range(n): #根据数据集标签进行分类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
x1 = np.arange(-3.0, 3.0, 0.1)
x2 = (-weights[0] - weights[1] * x1) / weights[2] #w0+w1x1+w2x2=0 => x2=(-w0-w1x1)/w2
ax.plot(x1, x2)
plt.title('BestFit') #绘制title
plt.xlabel('x1'); plt.ylabel('x2') #绘制label
plt.show()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet()
weights = gradAscent(dataMat, labelMat)
plotBestFit(weights)
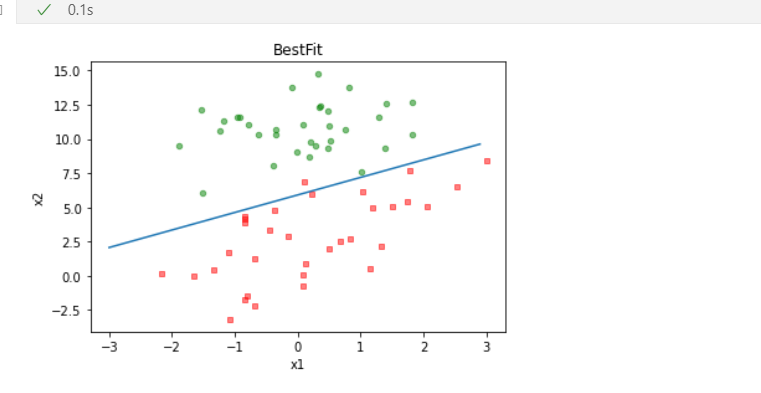
可以看出,效果还是挺好的。
5、随机梯度算法
全批量在每次更新回归系数时都需要遍历整个数据集,这种方法在处理小数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度太高。而随机梯度上升是一次仅用一个样本点来更新回归系数,这样做大大减小了计算复杂度,并且提高了函数的收敛速度。
代码如下:
点击查看代码
#函数说明:随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
if __name__ == '__main__':
dataMat, labelMat = loadDataSet()
weights = stocGradAscent0(array(dataMat), labelMat)
plotBestFit(weights)
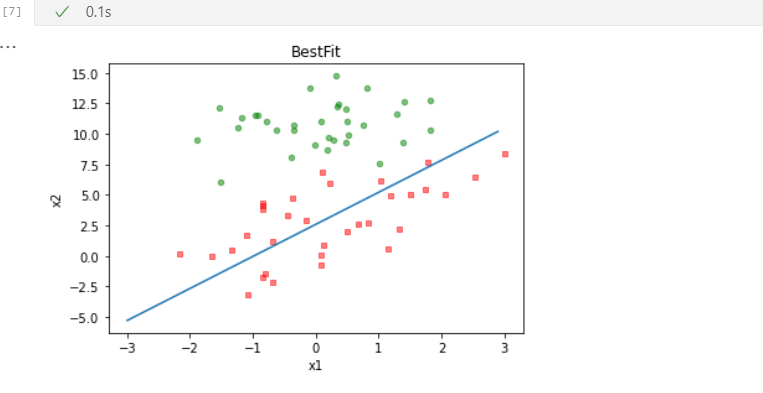
可以看出,此次分错的点比上次更多,效果下降了。
小结:
Logistic回归的优点:
无需事先假设数据分布;
可得到“类别”的近似概率预测;
可直接应用现有数值优化算法(如牛顿法)求取最优解,具有快速、高效的特点;
Logistic回归的缺点:
不能用Logistic回归去解决非线性问题,因为Logistic的决策面试线性的;
对多重共线性数据较为敏感;
很难处理数据不平衡的问题;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)