
图像融合综述
图像融合
一.图像融合满足的条件
- 融合后的图像应完整保留源图像的信息
- 融合后的图像不应产生任何合成信息,例如伪影
- 应避免不良状态,例如失准和噪音
二.融合方法
2.1传统的融合方法
- 传统的医学图像融合方法分为空间域和变换域
- 基于空间域的医学图像融合方法是最早的研究热点。典型的方法是主成分分析
- 缺点: 空间域技术产生光谱失真和融合图像的空间失真
- 为了获得更好的融合效果,研究人员将研究重点转向了变换域。人们将源图像转换到频域或其他域以融合它们,然后执行重建操作。
- 融合过程分为四个层次,分别是信号、特征、符号、像素层次
- 像素级如今被广泛使用,其典型代表包括轮廓变换、离散小波变换、金字塔变换。
- 基于变换域的方法具有良好的结构和避免失真的优点,但在融合过程中也会产生噪声。因此,去噪也是图像融合的挑战
- 缺点1: 一方面,为了保证后续特征融合的可行性,传统方法被迫对不同的源图像采用相同的变换来提取特征。但是,该操作没有考虑源图像的特征差异,可能导致提取的特征表达能力较差。
- 缺点2: 另一方面,传统的特征融合策略过于粗糙,融合性能非常有限。将深度学习引入图像融合的动机是克服传统方法的这些限制
2.2深度学习
-
优点1: 基于深度学习的方法可以利用不同的网络分支进行差异化的特征提取,从而获得更有针对性的特征。
-
优点2: 基于深度学习的方法可以在精心设计的损失函数的指导下学习更合理的特征融合策略,从而实现自适应特征融合
-
融合的三个子问题
- 特征提取、特征融合和图像重建
-
融合策略
-
基于自动编码器(AE)、基于传统卷积神经网络(CNN)和基于生成对抗网络(GAN)的方法
-
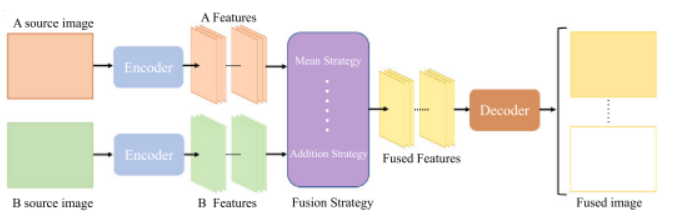
该图为自动编码器网络, DenseFuse 是最著名的基于 AE 的方法之一,它在 MS-COCO 数据集上训练编码器和解码器,并采用加法和𝑙1-范数融合策略。
![image]()
-
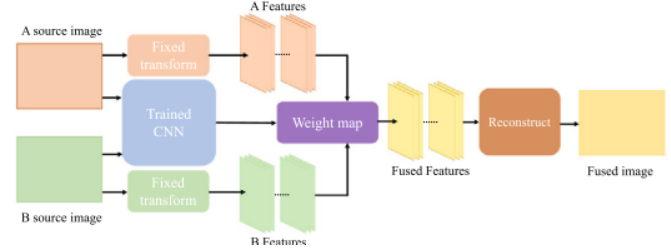
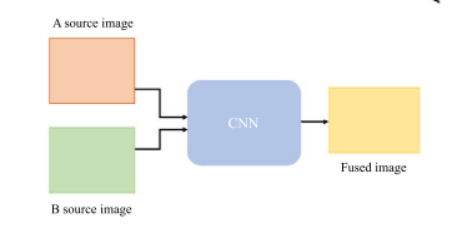
CNN 方法,它们通常以两种不同的形式将卷积神经网络引入图像融合中 一种是通过使用精心设计的损失函数和网络结构,实现端到端的特征提取、特征融合和图像重建,如图1所示。基于 CNN 的端到端方法的一个代表工作是 PMGI ,它提出了梯度和强度的比例保持损失来指导网络直接生成融合图像。另一种是采用经过训练的CNN来制定融合规则,而特征提取和图像重建则使用传统方法[22]完成,如图2所示。采用 CNN 生成融合权重,而图像分解和重建由拉普拉斯金字塔实现。
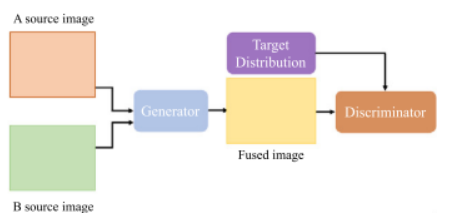
- GAN方法: GAN方法依靠生成器和判别器之间的对抗性博弈来估计目标的概率分布,可以以隐式的方式共同完成特征提取、特征融合和图像重建
-
根据融合目标和源图像成像的差异,图像融合场景可以分为三类
-
数字摄影图像融合
* 由于数字成像设备的性能限制,传感器无法在单个设置下完全表征成像场景中的信息。例如,由数码摄影产生的图像只能承受有限的照明变化,并且具有预定义的景深。在这种情况下,作为数字摄影图像融合的典型任务,多曝光图像融合和多焦点图像融合可以合并在不同设置下捕获的图像,以产生具有高动态范围和完全清晰度的结果。 -
多模态图像融合
* 由于成像原理的限制,单个传感器只能捕获部分场景信息。多模态图像融合结合了多个传感器获得的图像中最重要的信息,以实现对场景的有效描述。 -
锐化融合
2.3数字摄像图像融合方法
-
成像场景区域之间的光照变化通常很大。由于成像设备的技术限制,传感器捕获的图像通常处于非常有限的动态曝光范围内。也就是说,在单一拍摄设置下拍摄的图像会因为曝光过度/曝光不足而丢失场景信息。多曝光图像融合是将不同曝光的图像的有效信息结合起来,产生曝光适当、成像信息丰富的结果。目前实现多曝光融合的方法主要有 CNN 和 GAN 方法。
-
一些CNN方法直接使用训练好的网络从不同曝光的源图像中提取特征,然后根据特征图的显着性确定相应像素位置的重要性,生成融合权重图[38]。根据得到的融合权重图,直接对源图像进行加权,生成最终的融合结果。
-
多焦点融合
- 多焦点图像融合的问题源于光学镜头的局限性。具体而言,很难使不同景深的所有对象在一个图像中全部聚焦。多焦点图像融合是将具有不同焦点区域的图像组合在一起,以产生完整清晰的图像。CNN和GAN方法是用于多焦点图像融合的两种主要深度学习方法。
- 由于多焦点图像融合可以看作是清晰像素的选择,因此这些深度学习方法可以分为基于决策图的方法和基于整体重建的方法。
2.4多模态图像融合
- 不同传感器的成像原理是多种多样的,它们所捕捉到的多模态图像在描述场景的重点方面也存在显着差异。通过融合不同模态图像中的互补和有益信息,可以对成像场景或目标提供更全面的描述。两个最具代表性的多模态图像任务包括红外和可见图像融合,以及医学图像融合。
- 红外和可见光图像融合
- 红外图像具有显着的对比度,即使在恶劣天气下也能有效地从背景中突出目标。可见图像包含丰富的纹理细节,更符合人类视觉感知。红外和可见光图像融合就是将这两个特性结合起来,产生具有高对比度和丰富纹理的结果。
- 医学影像融合
- 介绍: 医学图像根据所表现的信息可分为结构图像和功能图像。例如,PET 和 SPECT 图像可以描述身体代谢功能的强度,而 MRI 和 CT 图像可以反映组织的结构。
- 方法: 目前,用于实现医学图像融合的两种流行方法是 CNN 和 GAN 方法
- 大多数用于医学图像融合的 CNN 方法只参与特征融合 。具体来说,这些方法通常使用预训练的卷积神经网络来测量医学图像像素的活动水平并生成融合权重图。然后,将生成的权重图与传统的分解重建策略(如拉普拉斯金字塔)相结合,实现医学图像融合。
- GAN 方法通过对抗性学习机制同时对医学源图像中的显着信息进行建模。例如,功能医学图像的显着信息是强度分布,结构医学图像的显着信息是空间纹理。 GFPPC-GAN 将 GAN 引入到 GFP 和 PC 图像的融合中,利用 PC 图像和融合图像之间的对抗学习来加强结构信息的保存。
- 锐化融合
- 介绍:锐化融合是克服光谱和空间分辨率之间矛盾的有效技术。在空间图像的指导下,致力于在空间维度上实现超分辨率,同时保持光谱分辨率。两种典型的锐化融合任务是多光谱图像锐化和高光谱图像锐化。
三.数据集来源和存在的问题
3.1数据集来源
- 多焦点图像融合中的测试数据来自MEF1数据集 ,该数据集收集了两类场景 (室内和室外) 的多曝光序列; 多焦点图像融合中的测试数据来自Lytro2数据集,其中利用Lytro相机在特定视角下改变聚焦深度,获得不同聚焦区域的数字图像;
- 红外和可见光图像融合中的测试数据来自TNO3数据集,主要描述各种军事相关场景 。
- 医学图像融合中的测试数据来自Harvard4医学院网站,其中包括大脑半球的不同横轴部分 。
- 多光谱锐化的测试数据来自QuickBird数据集,其中多光谱图像包含4个波段 。
- 高光谱锐化的测试数据来自Cave5数据集 [110],其中高光谱图像包含31个波段 。
3.2定性和定量评价
- 定性评估: 为每个图像融合任务选择两个典型的可视化结果,其中突出显示相关区域以反映差异 。
3.3问题
-
目前,在几乎所有的图像融合任务中,基于深度学习的方法都假设源图像是预先配准的 。然而,由于真实场景中的视差、尺度差异等因素,多模态图像和数码摄影图像都没有配准。因此,现有深度学习方法中沿空间像素位置的操作不适用于真实的源图像。尽管可以使用许多现成的方法对源图像进行预配准,但依赖配准算法的预处理可能会导致一定的局限性,例如效率低和对配准精度的依赖。因此,需要开发非配准融合算法,以隐式方式实现图像配准和融合。
-
由于传感器原理的不同,源图像的分辨率也会有所不同。克服分辨率差异,充分利用不同源图像中的信息实现有效融合是一个挑战。
-
面向任务的图像融合。图像融合的初衷是为后续应用提供更多有益的输入。然而,在许多图像融合任务中,现有的基于深度学习的方法在设计损失函数时没有考虑融合与后续应用之间的相关性,这往往导致非常主观的融合结果。未来的研究可以考虑在融合阶段将后续任务的准确性引入到损失函数设计中,以从决策层面指导融合过程。实时图像融合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号