

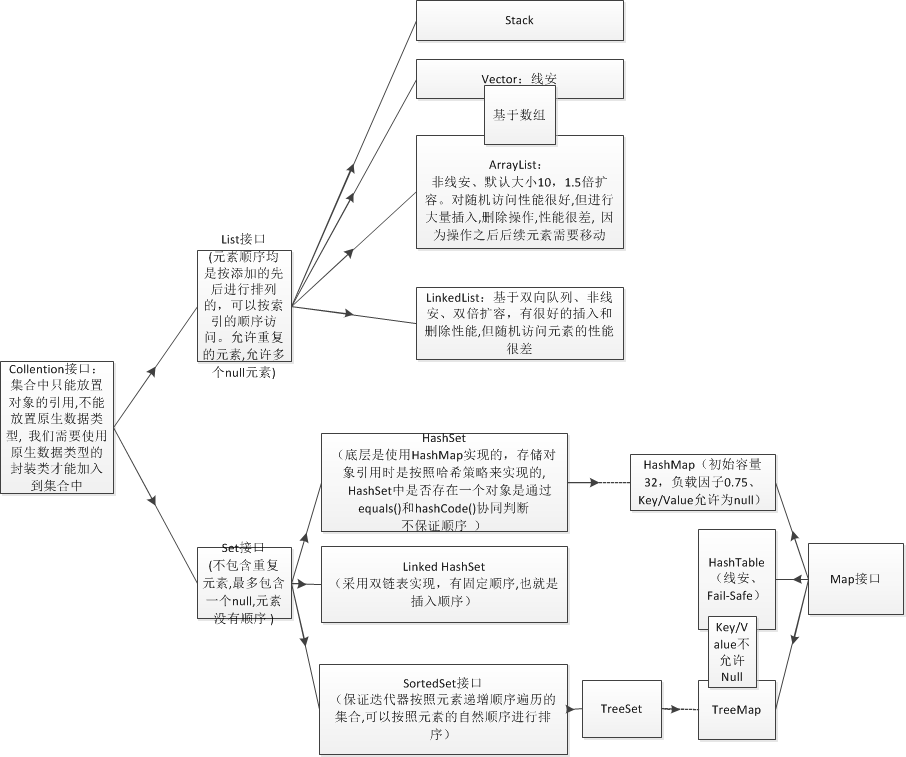
Collection类集
1.Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}
2.List接口
ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快。而LinkedList的内部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
2.1LinkedList类
由双向链表实现存储。允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList是非现场安全的,可以如此构造现场安全的同步的列表: List list =Collections.synchronizedList(new LinkedList(...));
2.2ArrayList类
ArrayList实现了可变大小的数组。它允许所有元素,包括null。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。 和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
2.3Vector类
Vector非常类似ArrayList,但是Vector是同步的。由Vector创建的Iterator,虽然和ArrayList创建的Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
2.4Stack类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
2.5List接口各实现类的区别
ArrayList 、stack和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要设计到数组元素移动等内存操作,所以索引数据快插入数据慢
Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,
LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快!
在《Practical Java》一书中Peter Haggar建议使用一个简单的数组(Array)来代替Vector或ArrayList。尤其是对于执行效率要求高的程序更应如此。因为使用数组(Array)避免了同步、额外的方法调用和不必要的重新分配空间的操作。
尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。
3.Set接口
它的常用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。
集合框架中还有两个很实用的公用类:Collections和Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一个数组进行类似的操作。
请注意:必须小心操作可变对象(MutableObject)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
4.Map接口
键不允许重复,有两种比较常用的实现:HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。
4.1Hashtable类
是线程安全的,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。Hashtable通过initialcapacity和load factor两个参数调整性能。通常缺省的load factor0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大。由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相同,即obj1.equals(obj2)=true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希表的操作。 需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。
4.2HashMap类
是线程不安全的,并且允许null,即null value和null key。
和Hashtable的区别
Hashtable和HashMap类有四个重要的不同之处。
第一:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
第二:为一个HashMap提供外同步的方便方法就是利用Collections类的静态的synchronizedMap()方法,它创建一个线程安全的Map对象,但是同步增加了很多处理费用。
第三:只有HashMap可以让你将空值作为一个表的条目的key或value。HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。
第四:HashTable使用Enumeration,HashMap使用Iterator来迭代
4.3 TreeMap
底层使用了红黑树来实现
4.4WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
4.5Properties
有时侯,你可能想用一个hashtable来映射key的字符串到value的字符串。Java提供了另外一种方法。 Java.util.Properties类是Hashtable的一个子类,设计用于String keys和values。Properties对象的用法同Hashtable的用法相象,但是类增加了两个节省时间的方法,你应该知道。 Store()方法把一个Properties对象的内容以一种可读的形式保存到一个文件中。Load()方法正好相反,用来读取文件,并设定Properties对象来包含keys和values。

Collections常用方法 // 将所有元素从一个列表复制到另一个列表 Collections.copy(new ArrayList(), new ArrayList()); // 如果两个指定collection中没有相同的元素,则返回 true Collections.disjoint(new ArrayList(), new ArrayList()); // 使用指定元素替换指定列表中的所有元素 Collections.fill(new ArrayList(), new Object()); // 返回指定 collection 中等于指定对象的元素数 Collections.frequency(new ArrayList(), new Object()); // 返回指定源列表中第一次出现指定目标列表的起始位置,如果没有出现这样的列表,则返回 -1 Collections.indexOfSubList(new ArrayList(), new ArrayList()); // 根据元素的自然顺序,返回给定 collection 的最大元素 Collections.max(new ArrayList()); // //根据元素的自然顺序,返回给定 collection 的最大元素 Collections.min(new ArrayList()); // 使用另一个值替换列表中出现的所有某一指定值 Collections.replaceAll(new ArrayList(), "oldVal", "newVal"); // 反转指定列表中元素的顺序 Collections.reverse(new ArrayList()); // 返回一个比较器,它强行反转 Collections.reverseOrder(); // 返回一个比较器,它强行反转指定比较器的顺序 Collections.reverseOrder(new Comparator() { @Override public int compare(Object o1, Object o2) { return 0; } }); // 使用默认随机源随机更改指定列表的序列 Collections.shuffle(new ArrayList()); // 根据元素的自然顺序对指定列表按升序进行排序 Collections.sort(new ArrayList()); // 根据元素的自然顺序对指定列表按降序进行排序 Collections.sort(new ArrayList(), Collections.reverseOrder()); // 在指定列表的指定位置处交换元素 Collections.swap(new ArrayList(), 1, 2);
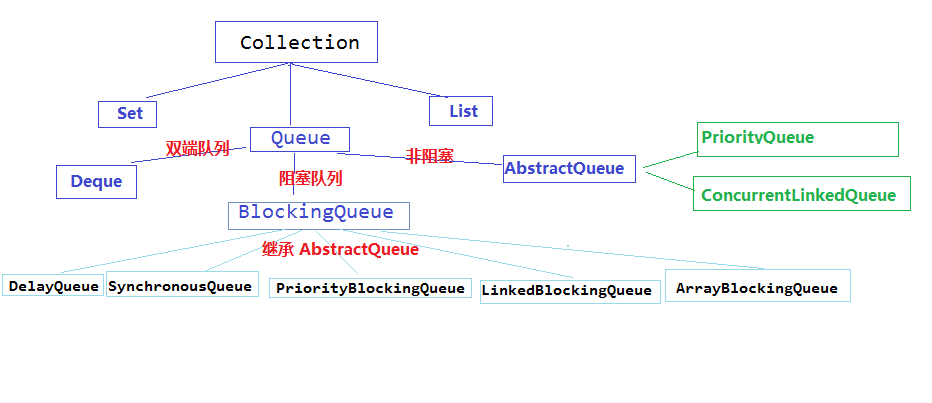
5. Queue
PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。
ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以不需要知道队列的大小,对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
阻塞队列类:实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。五个队列所提供的各有不同:
* ArrayBlockingQueue :一个由数组支持的有界队列。
* LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
* PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
* DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
* SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!