

IDEA2017 maven Spark HelloWorld项目(本地断点调试)
作为windows下的spark开发环境
1.应用安装 首先安装好idea2017 java8 scalaJDK spark hadoop(注意scala和spark的版本要匹配)
2.打开idea,创建建maven项目,如图所示

项目创建好后,记得勾选maven auto upate选项,这个动作会触发idea自动下载maven依赖的包
3.修改pom文件如下

<properties> <scala.version>2.11.11</scala.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> </dependencies> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.8</arg> </args> </configuration>
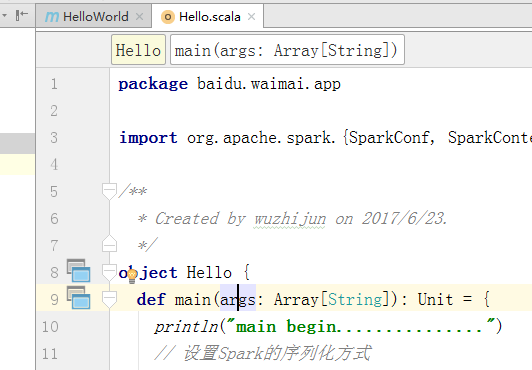
4.删除test文件夹(因为会报junit等错误),在scala下创建新scala Object

并在Hello中加入main函数,最终Hello类如下
object Hello { def main(args: Array[String]): Unit = { println("main begin...............") // 设置Spark的序列化方式 System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // 初始化Spark val sparkConf = new SparkConf().setAppName("sparkDemo") val sc = new SparkContext(sparkConf) val a = sc.parallelize(List(1,2,3,3)) val b = a.map(x => x+1) // textfileTest("C:/Users/think/Desktop/1.txt"); val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F") val nums: Map[Int, Int] = Map() println( "colors 中的键为 : " + colors.keys ) println( "colors 中的值为 : " + colors.values ) println( "检测 colors 是否为空 : " + colors.isEmpty ) println( "检测 nums 是否为空 : " + nums.isEmpty ) println("main end...............") } }
5.开始断点调试
点击main方法左侧篮框,将会触发debug过程![]()
如果出现以下错误
org.apache.spark.SparkException: A master URL must be set in your configuration
需要在debug config中的vm options加入下面这一行参数
-Dspark.master=local

6.调试界面
最终调试界面如下



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!