

HBase结构
Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据
Hive,可以使用类似SQL语言来访问HBase,最终本质是编译成MapReduce Job来处理HBase表数据,适合做数据统计。
1.什么是HBase
HBase是一个在Hadoop上开发的面向列(同类软件还有Cassandra和HyperTable)的分布式数据库。
利用HDFS作为其文件存储系统
利用MapReduce来处理HBase中的海量数据
利用Zookeeper作为协同服务,主要用于实时随机读/写超大规模数据集
HBase并不是关系型数据库,它不支持SQL,但它能够做RDBMS不能做的事;
2.HBase的特点
面向列:列的动态、无限扩展 —— 内容评论的扩展,同类数据集中存储便于压缩
稀疏表:有数据时这个单元格才存在 —— 节省空间
3.HBase表格示意图

Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
Ø Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
4.HBase的组件构成
HMaster (HA),负责Table和Region的管理工作
1、建表、删表、查看表格属性;
2、管理RegionServer负载均衡,调整Region分布;
3、Region Split后,负责新Region的分配;
4、在RegionServer失效后,负责失效节点上的Regions迁移;
RegionServer(x N),主要负责响应用户I/O请求,向HDFS文件系统中读写数据
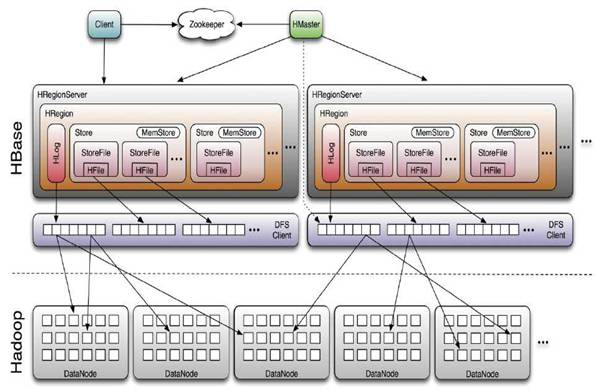
5.HBase中表格的存储
一张表存储在[1-N)个HRegion中,每个HRegion保存某张表RowKey连续的一段记录。
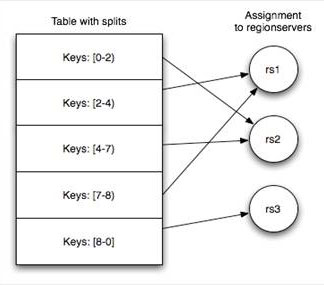
建表时可以预划分HRegion——提高并行度,进而提升读写速度
否则初始表存在单一HRegion中,随着数据增大HRegion会分裂为多个HRegion
HBase中有两张特殊的Table,-ROOT-和.META.
Ø .META.:记录了用户表的Region信息,.META.可以有多个regoin
Ø -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
Ø Zookeeper中记录了-ROOT-表的location
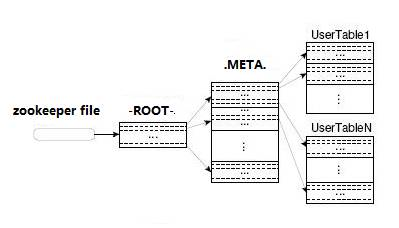
首先 HBase Client端会连接Zookeeper Qurom
通过 Zookeeper组件Client 能获知哪个 RegionServer管理-ROOT- Region 。
那么Client就去访问管理 -ROOT-的HRegionServer ,在META中记录了 HBase中所有表信息,(你可以使用 scan '.META.' 命令列出你创建的所有表的详细信息 ),从而获取Region 分布的信息。一旦 Client获取了这一行的位置信息,比如这一行属于哪个 Region,Client 将会缓存这个信息并直接访问 HRegionServer。
久而久之Client 缓存的信息渐渐增多,即使不访问 .META.表 也能知道去访问哪个 HRegionServer。
6.HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
7.HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
下图展示了MapReduce的数据处理流程,其中一个Map-Reduce step的输出将作为下一个典型Hadoop job的输入结果。
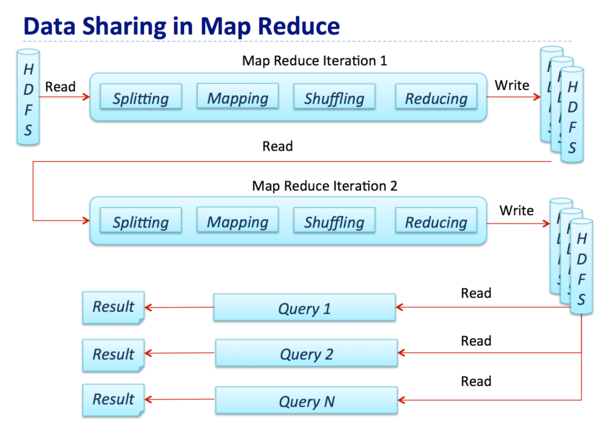
在整个过程中,中间结果会借助磁盘传递,因此对比计算,大量的Map-Reduced作业都受限于IO。然而对于ETL、数据整合和清理这样的用例来说,IO约束并不会产生很大的影响,因为这些场景对数据处理时间往往不会有较高的需求。然而,在现实世界中,同样存在许多对延时要求较为苛刻的用例


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!