

es基础知识
1.ES定义
•是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据
•使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
•Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
•检索相关数据•返回统计结果•速度要快
2. 核心概念
Cluster(集群):ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
Node(节点 ):形成集群的每个服务器称为节点。
Shard(分片):数据可以分为较小的分片。每个分片放到不同的服务器上(一个分片保存了索引中所有数据的一部分)。当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。
replia(副本):为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片
全文搜索:全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来
3.集群构成
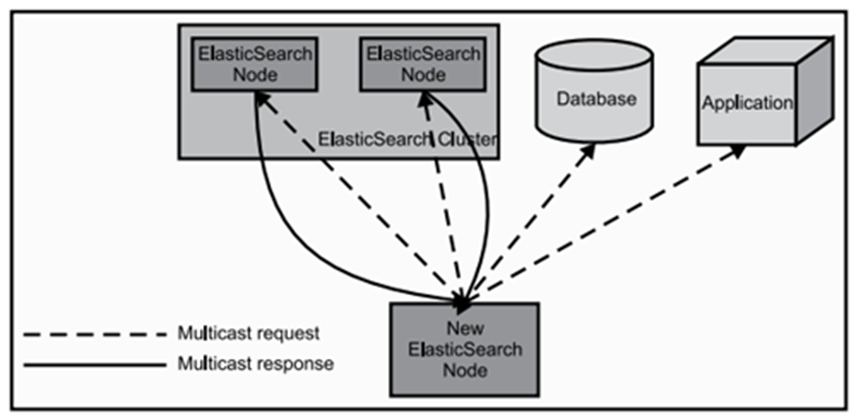
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如上图所示
4 .与关系数据库Mysql对比

5.ES特点和优势
分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
实时分析的分布式搜索引擎。索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;负载再平衡和路由在大多数情况下自动完成。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上。
支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
数据聚合分析
横向扩展机制方便
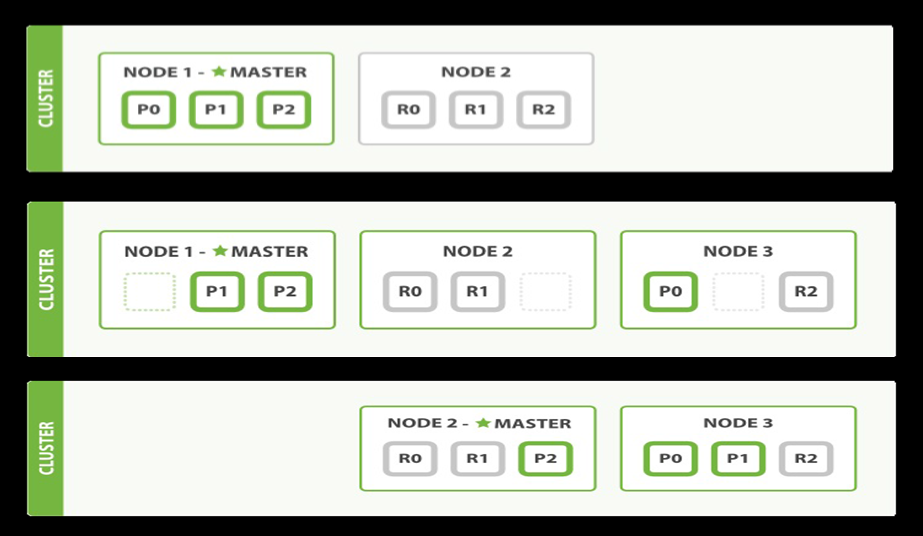
6. 横向扩展
7.ES对外接口——索引
当索引创建完成的时候,主分片的数量就固定了,但复制分片的数量可以调整。
每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储的数据量。
复制分片只是主分片的一个副本,防止硬件故障导致的数据丢失,同时可以提供读请求。
默认情况下,一个索引被分配为5个主分片,每个主分片有一个复制分片
7.1添加索引
分为手动和自动两种
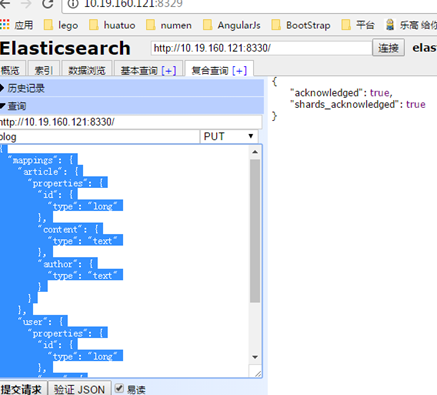
7.2 索字段类型

8 .文档元数据
文档不只有数据,还有元数据。三个必须的元数据节点是:


9.ES对外接口
9.1添加文档


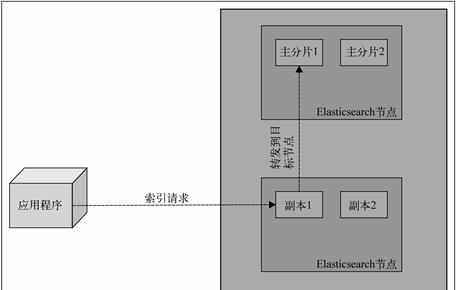
9.2 查询文档

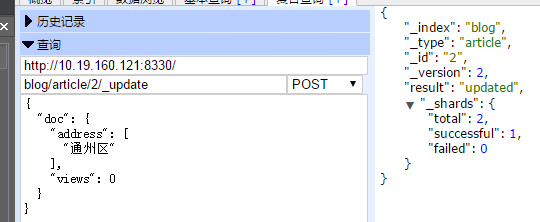
9.3 更新文档

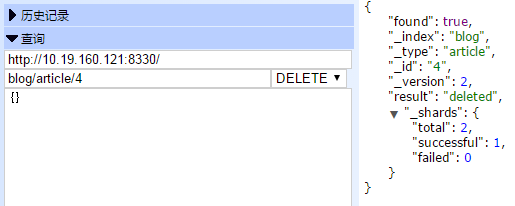
9.4 删除 文档
10.ES常用API
10.1 基本查询
Term:词条查询:代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇.所以搜索作者等于”李四”是搜不出来的。
Terms:多词条查询:多词条查询允许匹配那些在内容中含有某些词条的文档。词条查询允许匹配单个未经分析的词条,多词条查询可以用来匹配多个这样的词条

match-all:所有查询:它使我们能够匹配索引中的所有文件
Match查询:Elasticsearch将对一个字段选择合适的分析器,所以可以确定,传给match查询的词条将被建立索引时相同的分析器处理

multi_match查询:multi_match查询和match查询一样,不同的是它不是针对单个字段,而是可以通过fields参数针对多个字段查询。当然,match查询中可以使用的所有参数同样可以在multi_match查询中使用。
范围查询:
范围查询使我们能够找到在某一字段值在某个范围里的文档,字段可以是数值型,也可以是基于字符串的(将映射到一个不同的Apache Lucene查询)。范围查询只能针对单个字段,查询参数应封装在字段名称中。范围查询支持以下参数。
gte:范围查询将匹配字段值大于或等于此参数值的文档。
gt:范围查询将匹配字段值大于此参数值的文档。
lte:范围查询将匹配字段值小于或等于此参数值的文档。
lt:范围查询将匹配字段值小于此参数值的文档。
标识符查询:标识符查询是一个简单的查询,仅用提供的标识符来过滤返回的文档
前缀查询:前缀查询在配置方面来说跟词条查询类似。前缀查询能让我们匹配这样的文档:它们的特定字段以给定的前缀开始
query_string查询
script_fields查询
Fuzzy查询
通配符查询:请注意,通配符查询不太注重性能,在可能时应尽量避免,特别是要避免前
缀通配符(以通配符开始的词条)
10.2 复合查询
布尔查询


加权查询
constant_score查询
索引查询
11. 过滤器
11.1在任何搜索中使用过滤器,只需在于query节点相同级别上添加一个filter节点。如果你只想要过滤器,也可以完全省略query节点。


11.2过滤器类型



11.3 query filter post-filter区别
查询:会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”。查询操作不仅仅会进行查询,还会计算分值,用于确定相关度
过滤器:会回答这个问题——“这个文档匹不匹配?”答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
后置过滤器:•只影响搜索结果、不影响聚合结果。post_filter会在查询之后才会被执行,因此会失去过滤在性能上帮助(比如缓存)。•post_filter应该只和聚合一起使用,并且仅当你使用了不同的过滤条件时。
12 . 数据排序

13.聚合


14. 倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。


可参考 https://blog.csdn.net/sinat_35930259/article/details/80282710
分类:
elasticsearch


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!