0.索引的概念
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。好比是一本书前面的目录,能加快数据库的查询速度。
无论是Myisam和Innodb引擎,如果在建表的时候没有显示的定义一行主键列的话,他内部都会自动创建一个隐藏的主键索引;
1.索引的优点:
a.大大减少服务器需要扫描的数据量
b.帮助服务器避免排序和临时表
c.将随机IO变为顺序IO
2.“三星 ”系统:
The index earns one star if it places relevant rows adjacent to each other,
a second star if its rows are sorted in the order the query needs,
and a final star if it contains all the columns needed for the query.
翻译:
如果将相关行相邻放置,索引就会获得一颗星,
如果行按查询所需的顺序排序,则是第二个星号,
如果包含查询所需的所有列,则为最后一个星号
3.按照实现方式来划分
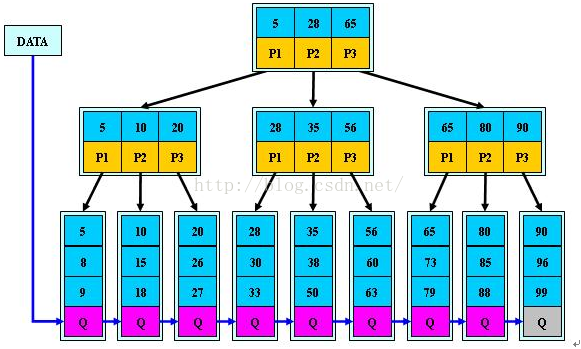
在MySQL索引中,B-Tree(平衡树)和B+Tree(平衡树加强版)是两种常用的索引结构。它们在一些方面有所不同,下面是它们的主要区别:
-
存储方式:B-Tree和B+Tree都是树状结构,但在存储方式上有所不同。B-Tree的每个节点中既包含键值,又包含对应的数据,这使得B-Tree可以直接通过索引进行数据查找。而B+Tree的内部节点只包含键值,而数据则仅存储在叶子节点中,这使得B+Tree的叶子节点形成一个有序链表,便于范围查询和顺序遍历。
-
叶子节点指针:B-Tree的叶子节点可以包含指向下一个叶子节点的指针,这样可以支持更高效的范围查询。而B+Tree的叶子节点之间通过指针连接成一个有序链表,这样可以快速地进行范围查询和顺序遍历。
-
范围查询效率:由于B+Tree的叶子节点形成有序链表,范围查询时可以通过遍历叶子节点的链表来获取满足条件的数据,而无需回溯到内部节点。这使得B+Tree在范围查询方面比B-Tree更高效。
-
索引的稳定性:B+Tree相较于B-Tree更稳定。当有新的数据插入时,B+Tree只需在叶子节点进行插入操作,而B-Tree可能需要调整内部节点的结构。这使得B+Tree更适合于频繁的插入和删除操作。
总体而言,B+Tree相对于B-Tree在范围查询和插入删除操作方面有更好的性能表现。在实际应用中,MySQL通常使用B+Tree作为默认的索引结构,因为它能够更好地适应数据库的查询和维护需求。
![]()
MyISAM和InnoDB上都是采用B+Tree索引,但是实现方式完全不同。具体可参考
https://www.cnblogs.com/zlcxbb/p/5757245.html
其它索引包含
哈希索引:基于哈希表实现,只有精确匹配索引所有列的查询才有效,只有Memory引擎实现
空间数据索引(R-Tree ),只有MyISAM引擎实现
全文索引:分词后查找关键词,适用于match against操作
4.按照索引类型来划分
innodb采用聚簇索引:主键索引的叶子节点下面直接存放数据,其他索引的叶子节点指向主键id;聚簇索引能提高多行检索的速度。
myisam采用非聚簇索引 :主键索引的叶子节点只存放数据在物理磁盘上的指针,其他索引也是一样的;非聚簇索引对于单行的检索很快
聚簇索引:数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
聚集索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是数据具体的物理地址。
InnoDB是聚簇索引,将主键组织到一棵B+树中((所以聚簇索引的key,不能过长)),而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。
非聚集索引:一个表可以有不止一个非聚簇索引。
MyISAM是非聚簇索引,B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的物理地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的。这里的索引都是非聚簇索引。非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,
这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
5.按照使用方式来划分
a.普通索引INDEX :这是最基本的索引,它没有任何限制。
b.唯一索引UNIQUE:与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
c.主键索引PRIMARY KEY:它 是一种特殊的唯一索引,不允许有空值。
d.全文索引FULLTEXT :仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时耗空间。
e. 单列索引、多列索引:多个单列索引与单个多列索引的查询效果不同,因为执行查询时,MySQL只能使用一个索引,会从多个索引中选择一个限制最为严格的索引。
f.组合索引:为了榨取MySQL的效率,就要考虑建立组合索引。例如表中针对title和time建立一个组合索引:ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))。建立这样的组合索引,其实是相当于分别建立了下面两组组合索引,为什么没有time这样的组合索引呢?这是因为MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这两列的查询都会用到该组合索引
–title,time
–title
6.索引覆盖
如果要查找的数据恰好是索引列,那么就不用在去物理磁盘上去找数据了,就是不用回行,称为索引覆盖;
7.索引优化
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。索引只是提高效率的一个因素,如果你的MySQL有
大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
a. 何时使用聚集索引或非聚集索引?
| 动作描述 |
使用聚集索引 |
使用非聚集索引 |
| 列经常被分组排序 |
使用 |
使用 |
| 返回某范围内的数据 |
使用 |
不使用 |
| 一个或极少不同值 |
不使用 |
不使用 |
| 小数目的不同值 |
使用 |
不使用 |
| 大数目的不同值 |
不使用 |
使用 |
| 频繁更新的列 |
不使用 |
使用 |
| 外键列 |
使用 |
使用 |
| 主键列 |
使用 |
使用 |
| 频繁修改索引列 |
不使用 |
使用 |
事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。
b. 索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
c. 使用短索引
对字符串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。mysql不允许索引这些列(BLOB、TEXT、很长的VARCHAR)的完整长度
d. 索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方向一致时,mysql才能用索引来对结果做排序
e. like语句操作:一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引。而like “aaa%”可以使用索引。
f. 不要在列上进行运算:
例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′
g.多列索引:
如果对多个单独索引做AND条件查询时,应该将多个单独索引合并为一个多列索引。
如果对多个单独索引做OR条件查询,会消耗大量CPU、内存在算法的缓存、排序和合并上。应该将多个单独索引合并为一个多列索引。
使用explain检查sql 语句,如果发现了索引合并问题,应该修改sql语句
选择合适的索引列顺序,选择性高的列往前放
h.覆盖索引:如果一个索引包含所有要查询的字段值(三星系统中第三星),较少了磁盘IO操作,提高查询性能
i.索引不能太多:索引越多会导致更新表的速度减慢,因为除了更新数据外,还要更新索引
j:MySQL只对以下操作符才使用索引 <,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引,不过除非是数据量真的很多,否则过多的使用索引也不是那么好玩的
8.mysql索引和页的关系
索引往往以索引文件的形式存储在磁盘上,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为了达到这个目的,磁盘按需读取,要求每次都会预读的长度一般为页的整数倍。而且数据库系统将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。把B-tree中的m值设的非常大,就会让树的高度降低,有利于一次完全载入。 内存管理内容可参考操作系统内存管理


 浙公网安备 33010602011771号
浙公网安备 33010602011771号