转自 https://blog.csdn.net/qq_26950567/article/details/118522439
refresh操作
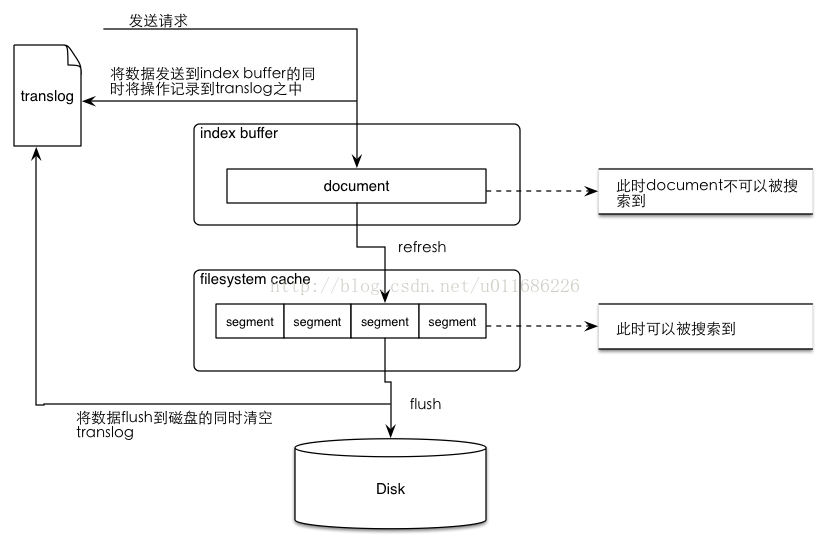
当我们向ES发送请求的时候,我们发现es貌似可以在我们发请求的同时进行搜索。而这个实时建索引并可以被搜索的过程实际上是一次es 索引提交(commit)的过程,如果这个提交的过程直接将数据写入磁盘(fsync)必然会影响性能,所以es中设计了一种机制,即:先将index-buffer中文档(document)解析完成的segment写到filesystem cache之中,这样避免了比较损耗性能io操作,又可以使document可以被搜索。以上从index-buffer中取数据到filesystem cache中的过程叫做refresh。
refresh操作可以通过API设置:
POST /index/_settings
{“refresh_interval”: “10s”}
当我们进行大规模的创建索引操作的时候,最好将将refresh关闭。
POST /index/_settings
{“refresh_interval”: “-1″}
es默认的refresh间隔时间是1s,这也是为什么ES可以进行近乎实时的搜索。
flush操作与translog
我们可能已经意识到如果数据在filesystem cache之中是很有可能在意外的故障中丢失。这个时候就需要一种机制,可以将对es的操作记录下来,来确保当出现故障的时候,保留在filesystem的数据不会丢失,并在重启的时候可以从这个记录中将数据恢复过来。elasticsearch提供了translog来记录这些操作。
当向elasticsearch发送创建document索引请求的时候,document数据会先进入到index buffer之后,与此同时会将操作记录在translog之中,当发生refresh时(数据从index buffer中进入filesystem cache的过程)translog中的操作记录并不会被清除,而是当数据从filesystem cache中被写入磁盘之后才会将translog中清空。而从filesystem cache写入磁盘的过程就是flush。可能有点晕,我画了一个图帮大家理解这个过程:
总结一下translog的功能:
1.保证在filesystem cache中的数据不会因为elasticsearch重启或是发生意外故障的时候丢失。
2.当系统重启时会从translog中恢复之前记录的操作。
3.当对elasticsearch进行CRUD操作的时候,会先到translog之中进行查找,因为tranlog之中保存的是最新的数据。
4.translog的清除时间时进行flush操作之后(将数据从filesystem cache刷入disk之中)。
再总结一下flush操作的时间点:
1.es的各个shard会每个30分钟进行一次flush操作。
2.当translog的数据达到某个上限的时候会进行一次flush操作。
有关于translog和flush的一些配置项:
index.translog.flush_threshold_ops:当发生多少次操作时进行一次flush。默认是 unlimited。
index.translog.flush_threshold_size:当translog的大小达到此值时会进行一次flush操作。默认是512mb。
index.translog.flush_threshold_period:在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作。默认是30m。
index.translog.interval:多少时间间隔内会检查一次translog,来进行一次flush操作。es会随机的在这个值到这个值的2倍大小之间进行一次操作,默认是5s。
------------------------------------------------------------------------------------------------
在ES中, 要保证被索引的文档能够立即被搜索到, 有两种方法:_refresh 或者_flush。
那么二者的区别是什么呢?要搞懂这个问题, 就需要对ES中文档的索引过程有个了解。
我们知道ES的索引数据是写入到磁盘上的。但这个过程是分阶段实现的,因为IO的操作是比较费时的。
当一个文档进入ES的初期, 文档是被存储到内存里的,默认经过1s之后, 会被写入文件系统缓存,这样该文档就可以被搜索到了,注意,此时该索引数据被没有最终写入到磁盘上。如果你对这1s的时间间隔还不满意, 调用_refresh就可以立即实现内存->文件系统缓存, 从而使文档可以立即被搜索到。
所以refresh实现的是文档数据从内存到文件系统缓存的过程。
再来看flush,flush是用于translog的。
ES为了数据的安全, 在接受写入的文档的时候, 在写入内存buffer的同时, 会写一份translog日志,从而在出现程序故障/磁盘异常时, 保证数据的完整和安全。flush会触发lucene commit,并清空translog日志文件。 translog的flush是ES在后台自动执行的,默认情况下ES每隔5s会去检测要不要flush translog,默认条件是:每 30 分钟主动进行一次 flush,或者当 translog 文件大小大于 512MB主动进行一次 flush。对应的配置是index.translog.flush_threshold_period 和 index.translog.flush_threshold_size
需要指出的是, 从ES2.0开始,每次 index、bulk、delete、update 完成的时候,一定触发flush translog 到磁盘上,才给请求返回 200 OK。这个改变提高了数据安全性,但是会对写入的性能造成不小的影响。在写入效率优先的情况下,可以在 index template 里设置如下参数:"index.translog.durability":"async" 和 "index.translog.sync_interval":30s (默认是5s)。
参考:
1. http://stackoverflow.com/questions/19963406/refresh-vs-flush
2.https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
3. http://kibana.logstash.es/content/elasticsearch/principle/realtime.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html