
三剑客之一 Grep小记
三剑客grep+sed+awk,配合正则又爱又恨的存在~~~
话不多少,开记~~~
grep #过滤 文本搜索工具,按照行进行处理
[root@web01 ~]# cat 2.txt
root oldboy good
stundent oldboy
oldboy
oldgirl root
dog cat
oldboy
ROOT
old
oldboyoldboy
[root@web01 ~]# grep 'oldboy' 2.txt #过滤出oldboy及包含oldboy的行
root oldboy good
stundent oldboy
oldboy
oldboy
oldboyoldboy
oldboyoldboy test
[root@web01 ~]# grep -w 'oldboy' 2.txt # 精确匹配,只匹配oldboy 包含关系不匹配
root oldboy good
stundent oldboy
oldboy
oldboy
[root@web01 ~]# grep -v 'oldboy' 2.txt # 排除包含oldboy的行 取反
oldgirl root
dog cat
ROOT
old
[root@web01 ~]# grep -n 'oldboy' 2.txt # 显示过滤内容的原行号
1:root oldboy good
2:stundent oldboy
3:oldboy
6:oldboy
9:oldboyoldboy
10:oldboyoldboy test
[root@web01 ~]# grep -c 'oldboy' 2.txt # 只显示过滤内容的总计行数
6
[root@web01 ~]# grep -i 'root' 2.txt # 不区分大小写
root oldboy good
oldgirl root
ROOT
总结:grep 参数选项
-v #对过滤到的内容取反
-n #显示过滤到内容的行号
-i #不区分大小写
-w #按照单词过滤
-P #支持tab键
-E #扩展正则 ==egrep
-r #递归查询,查询当前目录及目录下面的所有文件
-A #显示匹配行及后面多少行
-B #显示匹配行的前面多少行
-C #显示匹配行的前后多少行
三剑客都支持正则匹配:
1.过滤以m开头的行:
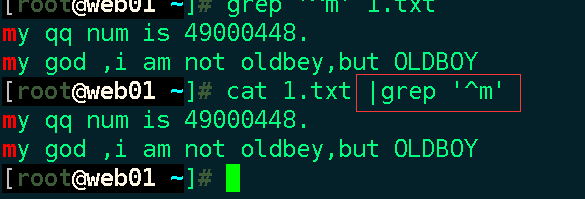
2.过滤以m结尾的行(过滤以什么结尾时注意空格,cat -A查看是否有空格)
[root@web01~]#grep 'm $' oldboy.txt
my blog is http: blog.51cto.com
our site is http:www.lizhenya.com
3.针对空行进行取反【空行:^$ 】
[root@web01~]#grep '^$' oldboy.txt
[root@web01~]#grep -v '^$' oldboy.txt
4.排除空行和#的行 #用到或者, 使用的是扩展正则
[root@oldboy~]#egrep -v '^$|#' oldboy.txt
5.匹配任意一个字符 不包含空行
[root@oldboy~]#grep '.' oldboy.txt -o
6. .* 匹配所有 #任何符号,包括空行
[root@oldboy~]#grep '.*' oldboy.txt -o
7. 匹配以 . 结尾的行
[root@oldboy~]#egrep '\.$' oldboy.txt # . 有特殊含义,撬棍取消其特殊含义
8. *匹配前一个字符出现0次或0次以上
[root@oldboy~]#grep '0*' oldboy.txt # 0这个数字出现0次或0次以


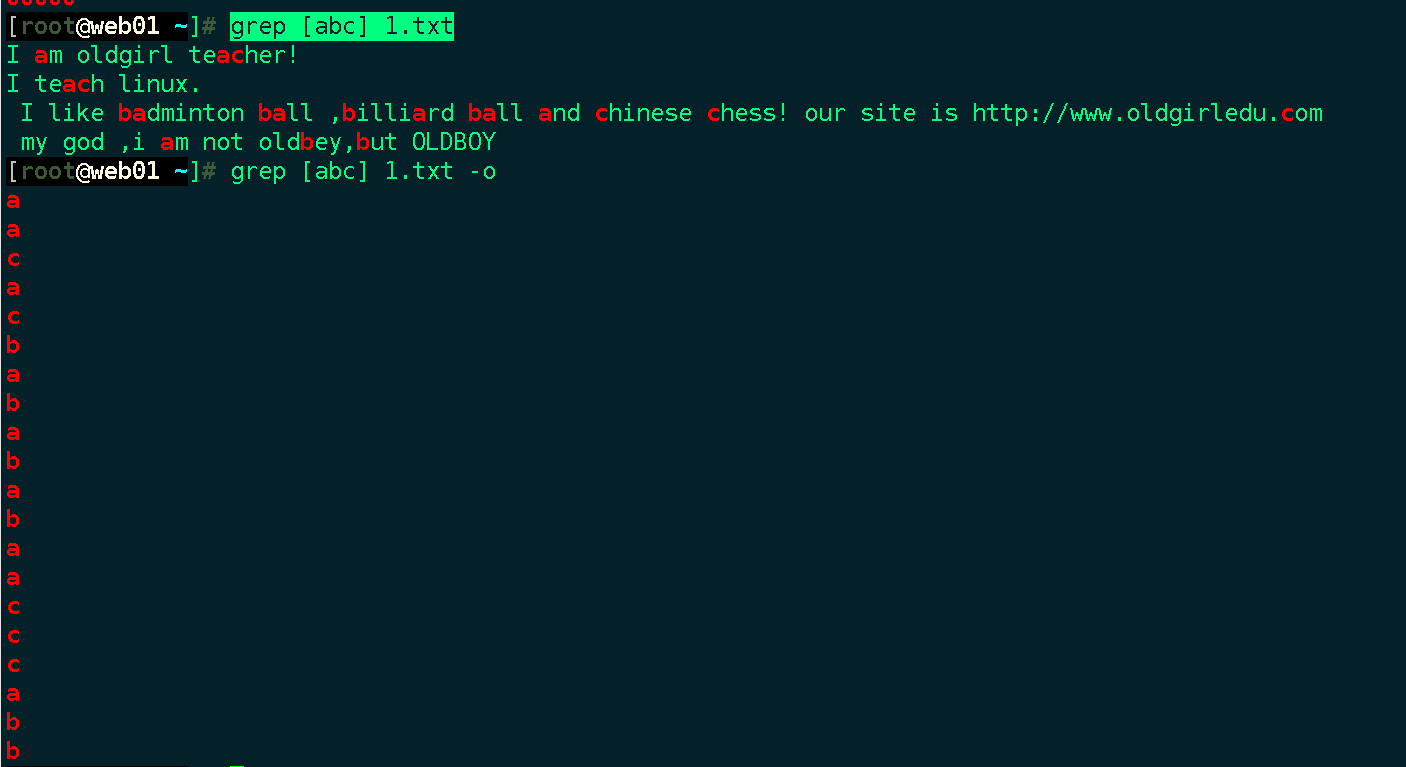
9. 分别匹配a b c
[root@oldboy~]#grep '[abc]' oldboy.txt
[root@oldboy~]#grep '[0-9]' oldboy.txt -o
10. 查看花括号前的字母或数字最少出现几次,最多出现多少次
[root@oldboy~]#egrep '8{1,5}' oldboy.txt #最少出现1次,最多出现5次
my qq num is 593528156
not 572891888887.
避坑指南:
1.执行某些指令时需要用到扩展正则,为了不单独记忆普通正则与扩展正则建议使用grep时都使用egrep。
2.注意特殊符号,需要用\取消其特殊含义。
