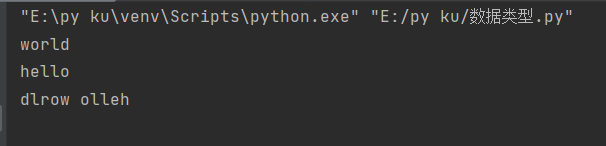
Python——数据类型内置方法
方法就是提前内置给各个数据类型的一些功能
视频文件:暂停、快进、倍速、放大等功能
表格文件:公式、透视表、插入表格、插入行、插入列等功能
方法的表现形式:
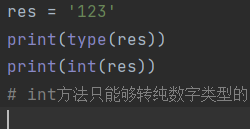
int(res) #方法名()
数据类型.方法名()
str.split()
'helloworld'.solit()
整型和浮点型的内置方法:
res2 = '123kevin'
print(int(res2))
print(int('')) # invalid literal for int() with base 10: ''
res = int(input('请输入内容'))
print(int(res))
十进制转其他进制
10---------->00001010
print(bin(2000)) # 0b1010 # 0b代表的是二进制
print(oct(2000)) # 0o3720
print(hex(2000)) # 0x64 0x7d0 0-9 11 12 14 14 15
ob:二进制
0o:八进制
0x:十六进制
返回来转换
print(int('0b1010', 2)) # 10
print(int('0o3720', 8)) # 2000
print(int('0x7d0', 16)) # 2000
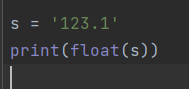
字符串类型的内置方法
1.数据类型转换: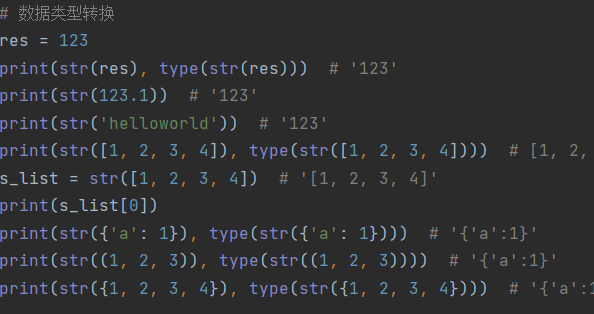
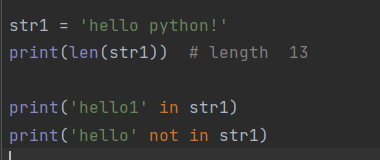
str1 = 'hello python!'
print(str1[2])
print(str1[-1])
print(str1[-2])
str1[0] = 'x' # 字符串不允许改变值
# 1.按索引存取值(正向存取+反向存取):即可存也可以取
# 1.1 正向取(从左往右)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 反向取(负号表示从右往左)
>>> my_friends[-1]
5
# 1.3 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在则报错
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到3的元素
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 步长:0:4:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
>>> my_friends[0:4:2]
['tony', 'tom']
# 3.长度
>>> len(my_friends)
5
# 4.成员运算in和not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
2.切片(顾头不顾尾,步长)
2.1 顾头不顾尾:取出索引为0到8的所有字符
print(str1[0:3]) # hel
print(str1[0:9]) # hello pyt
print(str1[0:9:3]) # hlopt
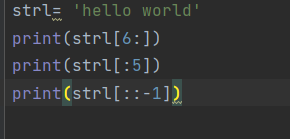
print(str1[::-1])
print(str1[6:]) # 一直切到字符串的末尾
print(str1[:5]) # 从索引位置为0的开始
print(str1[::-1]) # 这个写法就是把一个字符串翻转了

strip 移除字符串首尾指定的字符(默认移除空格)
>>> str1 = '**tony***'
>>> str1.strip('*') # 移除左右两边的指定字符
'tony'
>>> str1.lstrip('*') # 只移除左边的指定字符
tony***
>>> str1.rstrip('*') # 只移除右边的指定字符
**tony
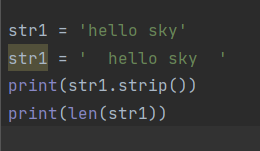
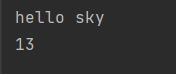
str1 = ' hello python! '
str1 = '$$hello python!$$'
str1 = '@@@hello p@@@ython!@@@@@@'
print(str1.strip(), len(str1), len(str1.strip()))
print(str1.lstrip(), len(str1), len(str1.lstrip()))
print(str1.rstrip(), len(str1), len(str1.rstrip())
str1 = 'kevin@18@male@200000' # ['kevin', 18, 'male', 2000]
# res = str1.split('|') # ['kevin', '18', 'male', '200000']
res = str1.split('@') # ['kevin', '18', 'male', '200000']
print(res)
for i in str1:
print(i)
使用方法:
# 1.按索引取值(正向取,反向取):
# 1.1 正向取(从左往右)
>>> str1[6]
p
# 1.2 反向取(负号表示从右往左)
>>> str1[-4]
h
# 1.3 对于str来说,只能按照索引取值,不能改
>>> str1[0]='H' # 报错TypeError
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到8的所有字符
>>> str1[0:9]
hello pyt
# 2.2 步长:0:9:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2、4、6、8的字符
>>> str1[0:9:2]
hlopt
# 2.3 反向切片
>>> str1[::-1] # -1表示从右往左依次取值
!nohtyp olleh
# 3.长度len
# 3.1 获取字符串的长度,即字符的个数,但凡存在于引号内的都算作字符)
>>> len(str1) # 空格也算字符
13
# 4.成员运算 in 和 not in
# 4.1 int:判断hello 是否在 str1里面
>>> 'hello' in str1
True
# 4.2 not in:判断tony 是否不在 str1里面
>>> 'tony' not in str1
True
# 5.strip移除字符串首尾指定的字符(默认移除空格)
# 5.1 括号内不指定字符,默认移除首尾空白字符(空格、\n、\t)
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# 5.2 括号内指定字符,移除首尾指定的字符
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6.切分split
# 6.1 括号内不指定字符,默认以空格作为切分符号
>>> str3='hello world'
>>> str3.split()
['hello', 'world']
# 6.2 括号内指定分隔字符,则按照括号内指定的字符切割字符串
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127', '0', '0', '1'] # 注意:split切割得到的结果是列表数据类型
# 7.循环
>>> str5 = '今天怎么样?'
>>> for line in str5: # 依次取出字符串中每一个字符
... print(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号