
正则表达式-grep(egrep)
一、正则表达式定义说明
1、定义
为处理大量的字符串而定义的一套规则和方法。
通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤、替换或者输出需要的字符串。
2、应用场景
在linux运维工作中,时刻都会面对大量带有字符串的文本配置、程序、命令输出及日志文件等,
而我们经常会有迫切的需要从大量的字符串内容中查找符合工作需要的特定字符串,这就要靠正则表达式,
因此,可以说正则表达式就是为过滤这样字符串的需求而生的!
正则表达式应用非常广泛,例如:php,Python,java等,但在linux中最常用的正则表达式的命令就是grep(egrep),sed,awk等。
3、注意
linux正则表达式一般以行为单位处理的。
正则表达式和我们常用的通配符特殊字符是有本质区别的,例如:ls *.txt 这里的*就是通配符(表示所有),不是正则表达式。
确保字符集:export LC_ALL=C
二、正则表达式含义解释
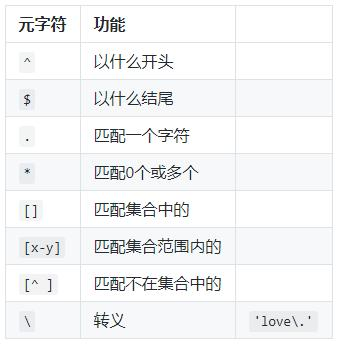
1、基础正则表达式
. 代表且只能代表任意一个字符(不包括空行)
* 重复前面任意0个或多个字符
.* 匹配所有字符。(包括空行)
^ 表示以什么开头,^bqh 以bqh开头
$ 是以什么结尾
^$ 表示空行。
\ 例\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
^.* 以任意多个字符开头。
.*$ 以任意多个字符结尾。
(.*) 从第一字符匹配,到空格停止,
[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别。
a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
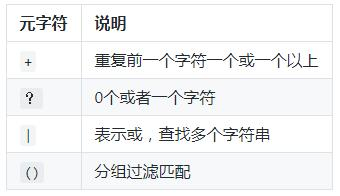
2、扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
grep提供的option(参数选项):
-i 忽略大小写
-n 显示行号
-o 只显示被匹配的关键字,不打印匹配的行内容
-r 递归搜索
-v 取反,显示未被匹配的行信息
-q 静默模式,不输出任何信息,在shell脚本中,可以通过echo $? 查看是否匹配到,0表示匹配到,1表示没有匹配到。
-E 使用扩展正则表达式。
三、实例
定义:
正则表达式是一种字符模式,用于在查找过程中匹配制定的字符。
元字符通常在Linux中分为两类:
Shell元字符,由Linux Shell进行解析;
正则表达式元字符,由vi/grep/sed/awk等文本处理工具进行解析;
特殊元字符

本文主要针对普通正则表达式,和扩展正则表达式进行展开
1、基础正则表达式
表达式元字符
基础数据准备:
[root@dream zhengze]# ls bqh.log linux.txt refile [root@dream zhengze]# cat refile I had a lovely time on our little picnic. Lovers were all oraoud us.It is springtime.Oh love,how much I adore you.Do you know the extend of my love? Oh,by the way,I think I lost my gloves somewhere out in that field of clover.Did you see them? I can only hope love is forever.I live for you.It`s hard to get back in the groolve [root@dream zhengze]# cat linux.txt Linux is a good god assdxw bcvnbvbjk greatttttt wexcvxc operaaaating dhfgjfvx goodfs awrerdxxhkl gdsystem awxxxx glad good [root@dream zhengze]# cat bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 41188889874 my tel 1234567890 [root@dream zhengze]#
设置每次过滤出来的字符串都会带色彩了
[root@dream zhengze]# alias grep='grep --color=auto'
1)、^love,查找以love开头的所有行
[root@dream zhengze]# grep '^love' refile love,how much I adore you.Do you know [root@dream zhengze]#
2)、love$,搜索以love结尾的所有行
[root@dream zhengze]# grep 'love$' refile clover.Did you see them? I can only hope love [root@dream zhengze]#
3)、用.,表示任意字符
l..e,搜索以l(L的小写字母)开头,中间包含两个字符(用.表示),结尾是e的所有行
[root@dream zhengze]# grep 'l..e' refile I had a lovely time on our little picnic. love,how much I adore you.Do you know the extend of my love? Oh,by the way,I think I lost my gloves somewhere out in that field of clover.Did you see them? I can only hope love is forever.I live for you.It`s hard to get back in the grolve [root@dream zhengze]#
查找带o的字符
[root@dream zhengze]# grep ".o" bqh.log I like play computer. my blog is https://www.cnblogs.com/root/ [root@dream zhengze]#
符号.表示任意字符,但不表示空行。
[root@dream zhengze]# cat -n bqh.log 1 I am bhq! 2 3 I like play computer. 4 5 my blog is https://www.cnblogs.com/root/ 6 7 my qq 47384739874 8 my tel 1234567890 [root@dream zhengze]# grep -n "." bqh.log 1:I am bhq! 3:I like play computer. 5:my blog is https://www.cnblogs.com/root/ 7:my qq 47384739874 8:my tel 1234567890 [root@dream zhengze]#
用.*,表示包括空行在内的所有字符
[root@dream zhengze]# grep ".*" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 47384739874 my tel 1234567890 [root@dream zhengze]#
4)、用^$,去掉空行,用n显示行号,v取反
[root@dream zhengze]# cat -n bqh.log 1 I am bhq! 2 3 I like play computer. 4 5 my blog is https://www.cnblogs.com/root/ 6 7 my qq 47384739874 8 my tel 1234567890 [root@dream zhengze]# grep -v "^$" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 47384739874 my tel 1234567890 [root@dream zhengze]# grep -vn "^$" bqh.log 1:I am bhq! 3:I like play computer. 5:my blog is https://www.cnblogs.com/root/ 7:my qq 47384739874 8:my tel 1234567890 [root@dream zhengze]#
5)、查找以.结尾的行(转义)
注意:\. 就只代表点本身,转义符号,让有着特殊身份移动的字符。
[root@dream zhengze]# grep ".$" bqh.log //错误写法 I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 47384739874 my tel 1234567890 [root@dream zhengze]# grep "\.$" bqh.log //正确方法,用\转义. I like play computer. [root@dream zhengze]#
6)、1*,重复前面1到多个字符。-o为精确匹配
[root@dream zhengze]# grep "1*" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 41184739874 my tel 1234567890 [root@dream zhengze]# grep -o "1*" bqh.log 11 1 [root@dream zhengze]#
7)、用^.*,以任意多个字符开头
[root@dream zhengze]# grep "^I.*" bqh.log //以I开头 I am bhq! I like play computer. [root@dream zhengze]#
8)、用.*$,以任意多个字符结尾
[root@dream zhengze]# grep "t.*$" bqh.log //含有t的任意结束符的行 I like play computer. my blog is https://www.cnblogs.com/root/ my tel 1234567890 [root@dream zhengze]#
9)、用[abc],匹配字符集合内的任意一个字符【a-zA-Z】
[root@dream zhengze]# grep "[abc]" bqh.log //含有abc字符中任意字符的行 I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ [root@dream zhengze]#
匹配含有a-z任意小写字符的内容
[root@dream zhengze]# grep "[a-z]" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 41184739874 my tel 1234567890 [root@dream zhengze]#
匹配Love或love的内容
[root@dream zhengze]# grep '[Ll]ove' refile I had a lovely time on our little picnic. Lovers were all oraoud us.It is springtime.Oh love,how much I adore you.Do you know the extend of my love? Oh,by the way,I think I lost my gloves somewhere out in that field of clover.Did you see them? I can only hope love [root@dream zhengze]#
10)、用[^abc],取反
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别
[root@dream zhengze]# grep "[^a-z]" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 41184739874 my tel 1234567890 [root@dream zhengze]#
匹配非数字的任意字符
[root@dream zhengze]# grep "[^0-9]" bqh.log I am bhq! I like play computer. my blog is https://www.cnblogs.com/root/ my qq 41184739874 my tel 1234567890 [root@dream zhengze]#
11)、a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r /grep -E可以去掉斜线。
查找8重复3-5次的内容
[root@dream zhengze]# grep "8\{3,5\}" bqh.log my qq 41188889874 [root@dream zhengze]#
12)、\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
查找8重复3次以上(至少重复3次)的内容
[root@dream zhengze]# grep "8\{3,\}" bqh.log my qq 41188889874 [root@dream zhengze]#
13)、\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
[root@dream zhengze]# grep "8\{3\}" bqh.log //8开头,重复3次的内容 my qq 41188889874 [root@dream zhengze]# grep -E "8{3}" bqh.log //使用grep -E或egrep,可以取消斜线,效果一样。 my qq 41188889874 [root@dream zhengze]# egrep "8{3}" bqh.log my qq 41188889874 [root@dream zhengze]#
2、扩展的正则表达式:ERP(egrep或grep -E)
egrep,grep -E或sed -r过滤一般特殊字符可以不转义。
扩展的正则表达式:
1)、用+显示 重复一个或一个以上前面的字符
egrep,grep -E表达式
[root@dream zhengze]# cat linux.txt //文本内容 Linux is a good god assdxw bcvnbvbjk greatttttt wexcvxc operaaaating dhfgjfvx goodfs awrerdxxhkl gdsystem awxxxx glad good [root@dream zhengze]# egrep "go+d" linux.txt //显示含有go和d的行 Linux is a good god assdxw bcvnbvbjk goodfs awrerdxxhkl good [root@dream zhengze]# egrep -o "go+d" linux.txt //egrep显示go和d以及之间的1-n个字符 good god good good [root@dream zhengze]# grep -Eo "go+d" linux.txt //grep -E显示go和d以及之间的1-n个字符 good god good good [root@dream zhengze]#
2)、用?显示0个或者1个前面的字符
[root@dream zhengze]# cat linux.txt Linux is a good god assdxw bcvnbvbjk greatttttt wexcvxc operaaaating dhfgjfvx goodfs awrerdxxhkl gdsystem awxxxx glad good [root@dream zhengze]# egrep "go?d" linux.txt //用?表示g和d之间含有0个或1个o的行 god assdxw bcvnbvbjk gdsystem awxxxx [root@dream zhengze]# egrep -o "go?d" linux.txt //-o表示精确匹配 god gd [root@dream zhengze]# grep -Eo "go?d" linux.txt god gd [root@dream zhengze]#
3)、用|或,查找多个字符串
[root@dream zhengze]# cat linux.txt Linux is a good god assdxw bcvnbvbjk greatttttt wexcvxc operaaaating dhfgjfvx goodfs awrerdxxhkl gdsystem awxxxx glad good [root@dream zhengze]# egrep "gd|good" linux.txt //用|查找含有gd或者good的行 Linux is a good goodfs awrerdxxhkl gdsystem awxxxx good [root@dream zhengze]# grep -E "gd|good" linux.txt Linux is a good goodfs awrerdxxhkl gdsystem awxxxx good [root@dream zhengze]#
4)、用(),分组过滤
[root@dream zhengze]# cat linux.txt Linux is a good god assdxw bcvnbvbjk greatttttt wexcvxc operaaaating dhfgjfvx goodfs awrerdxxhkl gdsystem awxxxx glad good [root@dream zhengze]# egrep "g(la|oo)d" linux.txt //查找g和d之间含有la或者oo的行 Linux is a good goodfs awrerdxxhkl glad good [root@dream zhengze]# grep -E "(la|oo)" linux.txt Linux is a good goodfs awrerdxxhkl glad good [root@dream zhengze]#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号