

【Hadoop】5、集群运行
前提:需要在上节Hadoop全分布式基础配置的基础上完成
步骤一、NameNode 格式化
第一次启动 HDFS 时要进行格式化,否则会缺失 DataNode 进程。另外,只要运行过 HDFS,Hadoop 的工作目录(本书设置为/usr/local/src/hadoop/tmp)就会有数据,如果需要重新格式化,则在格式化之前一定要先删除工作目录下的数据,否则格式化时会出问题。
(master节点)
[root@master ~]# su - hadoop
[hadoop@master ~]$ cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ ./bin/hdfs namenode -format
22/04/01 17:37:26 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.100.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.1
……
……
22/04/01 17:37:26 INFO common.Storage: Storage directory /usr/local/src/hadoop/dfs/name has been successfully formatted.
22/04/01 17:37:26 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
22/04/01 17:37:26 INFO util.ExitUtil: Exiting with status 0
22/04/01 17:37:26 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.100.10
************************************************************/
以上出现successfully说明格式化成功
步骤二、启动 NameNode
(master节点)
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.example.com.out
[hadoop@master hadoop]$ jps
41732 NameNode
41801 Jps
看到NameNode说明成功
步骤三、启动 SecondaryNameNode
(master节点)
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-secondarynamenode-master.example.com.out
[hadoop@master hadoop]$ jps
41732 NameNode
41877 Jps
41834 SecondaryNameNode
看到SecondaryNameNode说明成功
步骤四、slave 启动 DataNode
(slave1和slave2节点)
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave1.example.com.out
[hadoop@slave1 ~]$ jps
41552 DataNode
41627 Jps
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave2.example.com.out
[hadoop@slave2 ~]$ jps
4161 DataNode
4236 Jps
看到DataNode说明成功
步骤五、查看 HDFS 的报告
(master节点)
[hadoop@master hadoop]$ hdfs dfsadmin -report
Configured Capacity: 34879832064 (32.48 GB)
Present Capacity: 26675437568 (24.84 GB)
DFS Remaining: 26675429376 (24.84 GB)
DFS Used: 8192 (8 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.100.20:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 16640901120 (15.50 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 4275404800 (3.98 GB)
DFS Remaining: 12365492224 (11.52 GB)
DFS Used%: 0.00%
DFS Remaining%: 74.31%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 01 17:41:17 CST 2022
Name: 192.168.100.30:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 3928989696 (3.66 GB)
DFS Remaining: 14309937152 (13.33 GB)
DFS Used%: 0.00%
DFS Remaining%: 78.46%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 01 17:41:17 CST 2022
步骤六、浏览器查看节点状态
需要在windows真机上执行
1、进入C:\Windows\sytstem32\drivers\etc\
2、把此目录下的hosts文件拖到桌面上
3、右键打开此文件加入IP与主机名的映射关系
192.168.100.10 master master.example.com
192.168.100.20 slave1 slave1.example.com
192.168.100.30 slave2 slave2.example.com
4、保存后拖回原位置
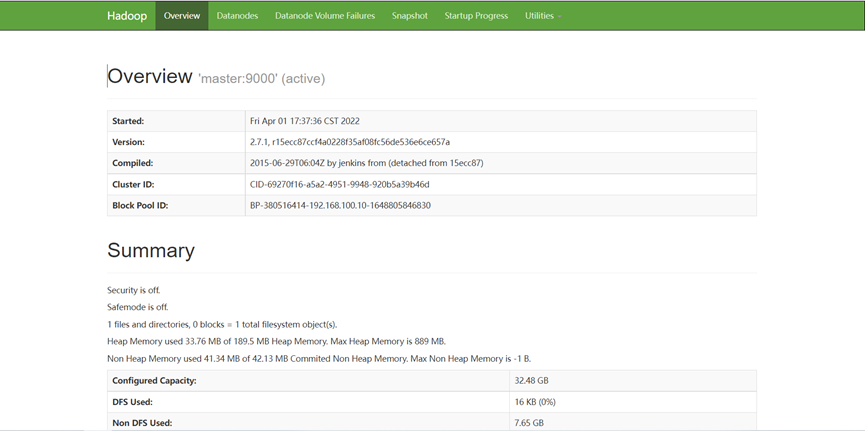
在浏览器访问:http://master:50070,可以查看NameNode和DataNode 信息
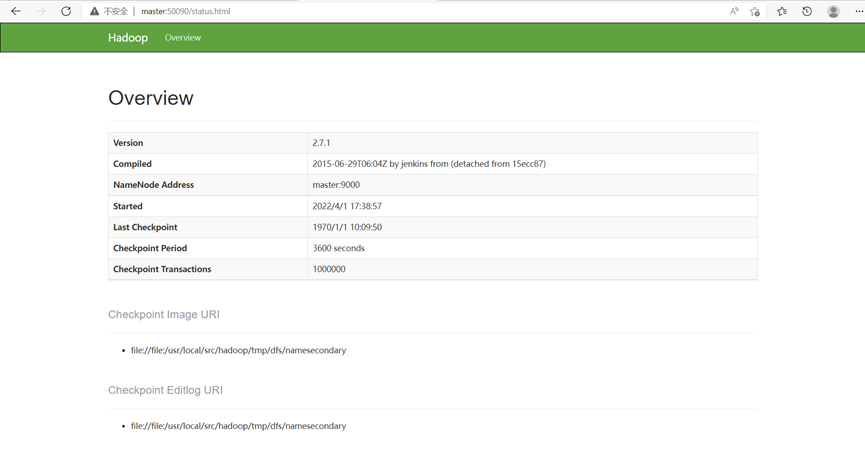
在浏览器访问: http://master:50090,可以查看 SecondaryNameNode 信息
步骤七、配置免密登录
启动 HDFS之前需要配置 SSH 免密码登录,否则在启动过程中系统将多次要求确认连接和输入 Hadoop 用户密码。
(master节点)
[hadoop@master ~]$ ssh-keygen -t rsa
[hadoop@master ~]$ ssh-copy-id hadoop@slave1
[hadoop@master ~]$ ssh-copy-id hadoop@slave2
步骤八、启动dfs 和 yarn
(master节点)
[hadoop@master ~]$ stop-dfs.sh
……
[hadoop@master ~]$ start-dfs.sh
……
[hadoop@master ~]$ start-yarn.sh
……
[hadoop@master ~]$ jps
45284 SecondaryNameNode
45702 Jps
45080 NameNode
45435 ResourceManager
(slave1和slave2节点)
[hadoop@slave1 ~]$ jps
42986 DataNode
43213 Jps
43102 NodeManager
[hadoop@slave2 ~]$ jps
42986 DataNode
43213 Jps
43102 NodeManager
在master上看到ResourceManager,并且在slave上看到NodeManager就说明启动成功
步骤九、运行WordCount测试
运行 MapReduce 程序,需要先在 HDFS 文件系统中创建数据输入目录,存放输入数据。
注意:创建的/input 目录是在 HDFS 文件系统中,只能用 HDFS 命令查看和操作。
(master节点)
[hadoop@master ~]$ hdfs dfs -mkdir /input
[hadoop@master ~]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2022-04-01 19:50 /input
[hadoop@master ~]$ mkdir ~/input
[hadoop@master ~]$ vi input/data.txt
Hello World
Hello Hadoop
Hello Huasan
将输入数据文件复制到 HDFS 的/input 目录中
[hadoop@master ~]$ hdfs dfs -put ~/input/data.txt /input
[hadoop@master ~]$ hdfs dfs -cat /input/data.txt
Hello World
Hello Hadoop
Hello Huasan
运行 WordCount
注意:数据输出目录/output不能提前创建,否则会报错
(master节点)
[hadoop@master ~]$ hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
22/04/01 19:58:10 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
22/04/01 19:58:10 INFO input.FileInputFormat: Total input paths to process : 1
22/04/01 19:58:10 INFO mapreduce.JobSubmitter: number of splits:1
22/04/01 19:58:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1648813571523_0001
22/04/01 19:58:11 INFO impl.YarnClientImpl: Submitted application application_1648813571523_0001
22/04/01 19:58:11 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1648813571523_0001/
22/04/01 19:58:11 INFO mapreduce.Job: Running job: job_1648813571523_0001
22/04/01 19:58:17 INFO mapreduce.Job: Job job_1648813571523_0001 running in uber mode : false
22/04/01 19:58:17 INFO mapreduce.Job: map 0% reduce 0%
22/04/01 19:58:20 INFO mapreduce.Job: map 100% reduce 0%
22/04/01 19:58:25 INFO mapreduce.Job: map 100% reduce 100%
22/04/01 19:58:26 INFO mapreduce.Job: Job job_1648813571523_0001 completed successfully
22/04/01 19:58:26 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=56
……
出现successfully说明运行成功
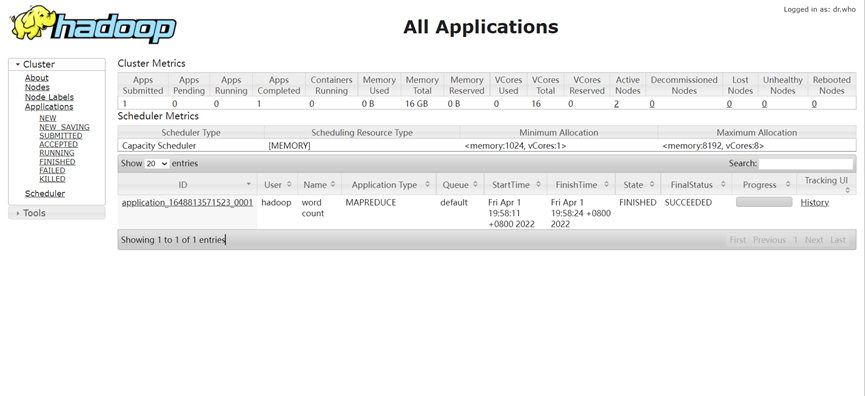
在浏览器访问: http://master:8088,可以看到运行成功
在浏览器访问: http://master:50070,在 Utilities 菜单中选择 Browse the file system,可以查看 HDFS 文件系统内容。
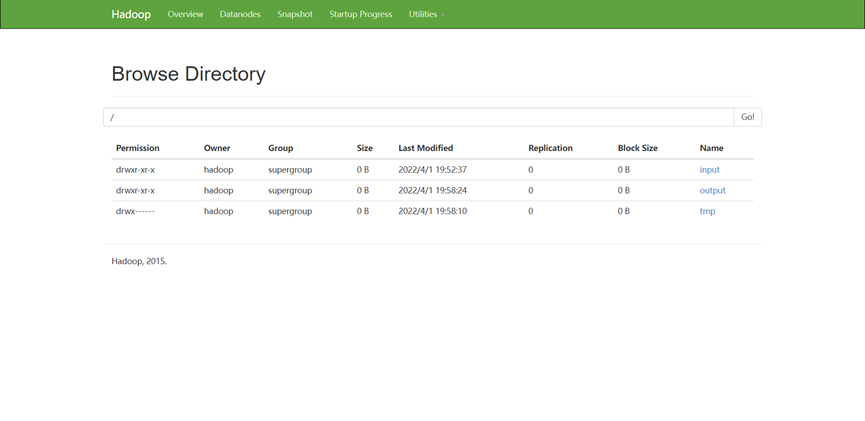
查看 output 目录,文件_SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中。
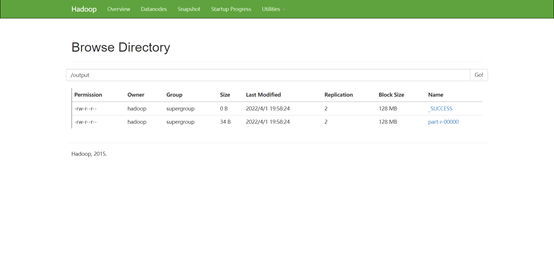
也可以直接使用命令查看 part-r-00000 文件内容
(master节点)
[hadoop@master ~]$ hdfs dfs -cat /output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
步骤十、停止 Hadoop
使用stop-all.sh一条命令就可以全部停止
(master节点)
[hadoop@master ~]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
192.168.100.30: stopping datanode
192.168.100.20: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
192.168.100.20: stopping nodemanager
192.168.100.30: stopping nodemanager
192.168.100.20: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
192.168.100.30: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
查看 JAVA 进程
[hadoop@master ~]$ jps
46683 Jps
[hadoop@slave1 ~]$ jps
43713 Jps
[hadoop@slave2 ~]$ jps
41702 Jps
声明:未经许可,不得转载
原文地址:https://www.cnblogs.com/wzgwzg/p/16093975.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix