1.非交互式人脸活体检测
人机交互的活体检测方法需要通过对人脸做出实时响应来判断是否为活体,通常采用的方法有脸部姿态和读取指定数字等。
以现在主流的交互式活体检测为例,系统会引导用户往指定方向去看,然后去估计用户的头部姿势,通过比较用户的动作姿势和指示方向是否一致来判断活体,从而抵抗照片和视频重放的攻击。这种方式的优点比较明显,由于大部分应用情况下相机传感器的有限性,在广泛且只有单目前置摄像机的情况下,非交互型的人脸活体检测实现相对比较复杂。需要的数据成本也相对较高,并且实际效果也不算太好。而交互性活体检测仅需要通过用户简单的低头摇头操作即可极大降低用户的欺骗攻击成本。但是也因此带来了一些问题,人机交互方法的主要缺点是检测的隐蔽性差,攻击者往往可以通过交互方法就可以知道系统所采用的活体检测手段,然后设计相应的方法去欺骗系统。
为了减少被攻击的可能性,因此在交互式的基础上增加了眨眼检测且对每次交互的项目进行随机性排序,并且加入了动态的边框检测,对于照片和视频的攻击具有很好的防御效果。
算法整体流程如下:
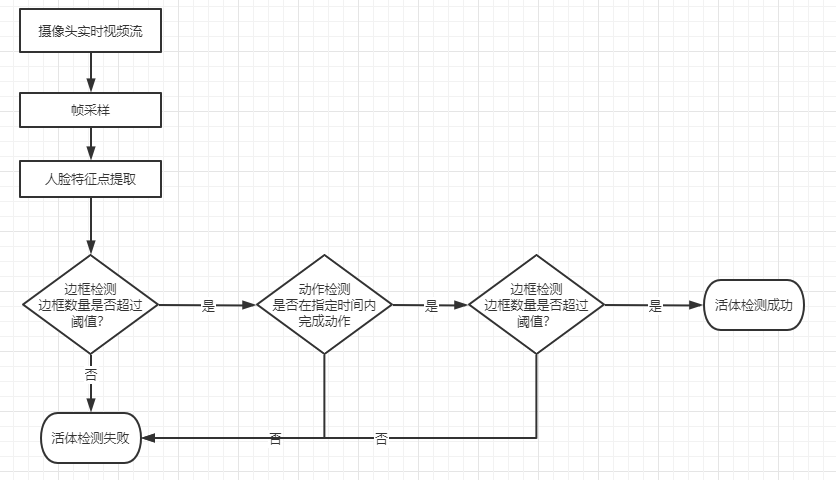
一:摄像头的视频获取
在获取视频的时候首先要设置一个区域,人脸落在这个区域里面才会检测,落在这个区域外面,就提示请靠近摄像头中心。人脸过大和过小都可以给出提示,比如请靠近摄像头,请远离摄像头。如果不提这些要求,大规模使用后,千奇百怪各种姿态都会看到的。甚至可以画一个小头,引导用户摆在合适的位置。
重点的重点是不合规姿态下,要有反馈提示!!!
二:人脸特征点提取
在此项目中,使用了Dlib 官方训练好的模型 “shape_predictor_68_face_landmarks.dat” 进行 68 个点标定,这个模型是基于14年CVPR中One Millisecond Face Alignment with an Ensemble of Regression Trees来实现的,本质上还是使用的级联回归器来做的人脸特征对齐,速度很快,效果也还不错。
首先输入标注人脸关键点的图像数据,先将脸提取处理,由于脸的尺寸不一,所以利用仿射变换将人脸关键点仿射到单位空间,统一尺寸和坐标系。将数据的人脸关键点做下平均,作为初始人脸形状,基于这个初始形状再进行残差计算拟合人脸关键点。
然后在初始关键点的范围内随机采样像素作为对应的特征像素点。特征像素点选择最接近的初始关键点作为anchor,并计算偏差。当前像素点通过旋转、转换、伸缩后的坐标系要与初始关键点(关键点的平均位置)接近,即最小化之间的距离平方,得到最优变换tform。tform作用于偏差,加上自身的位置信息,得到当前关键点的特征像素点。
在得到特征像素点后开始构建残差树,计算出当前关键点与目标关键点的偏差。通过特征像素点,利用退火的方法选择多个分割点,进行左右树划分,选择最小化划分后的偏差为最优分割点。分割样本,基于样本的平均残差更新当前关键点位置。回到上一步骤,重新选择出特征关键点,拟合下一颗残差树,最终综合所有残差树的结果得到关键点位置。
下图为级联中不同层级的形状变化:

从上图可以看出,随着级联的进行,预测形状和真实值之间的误差不断减少。上述算法在dlib中已经开源。因此直接调用了此代码进行脸部特征点标注。
三:边框检测
现在网上人脸照片泄露非常普遍,从网上下载合法用户照片,视频再去欺骗检测系统也时常发生,结合实际的场景,在非法用户采取欺诈行为时,或多或少的会出现一些边框。
如图所示:分别为手机边框和打印照片边框。
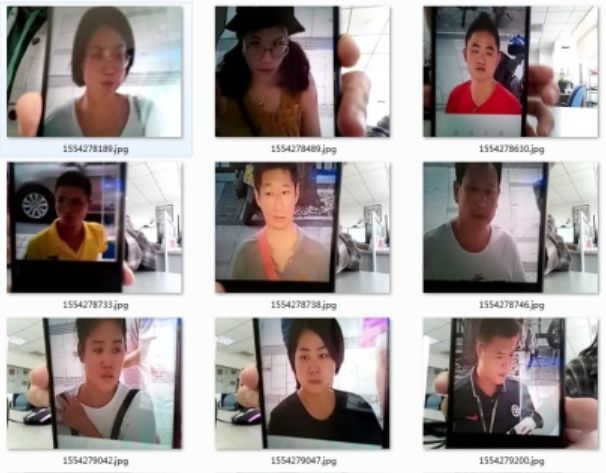

针对上图中的情况,设计了一种基于边缘提取和Hough变换的边框检测算法,首先采用传统的边缘检测方法Canny算子提取出图像的边缘区域,然后使用霍夫变换来检测图像中的直线区域,根据直线检测结果来判别是否存在边框。
这部分思路如下,先将图片的指定帧resize为200*200,对图像进行灰度化处理,再使用canny边缘提取灰度图边缘,再将边缘图进行霍夫直线变换。
不过此方法存在一些问题,受光线和背景复杂度的影响大,良好的光线是本算法识别的基础。
四:眨眼检测
一般来说,人很轻易就能区分一张活生生的脸和一张照片,因为人可以很容易地识别出许多真实面部才有的动态的生理线索,例如,面部表情的变化、嘴巴的运动、头部的转动、眼睛的变化等等。其中眨眼是既不需要高质量图像和额外设备也不需要用户高度配合的可以有效区分活体和照片的一种动态检测方式。因此本文选择了眨眼检测器作为活体检测框架的动态检测部分。尽管眨眼速度会因疲劳、情绪压力、行为类别、睡眠时间、眼睛损伤、药物治疗和疾病等因素而有所不同,但研究人员报告称,人在休息时自发眨眼的频率几乎为每分钟15到30次。也就是说,一个人大约每2到4秒眨眼一次,平均眨眼时间约为250毫秒。而目前的通用相机可以轻松地捕捉帧数不低于15FPS(帧/秒)(即帧间隔不超过70毫秒)的人脸视频。因此对于一个普通的相机来说,当人脸正对着相机时很容易捕捉到每一次眨眼动作的两帧甚至更多帧画面。因此利用基于通用相机的眨眼检测来进行活体识别是可行的.因此提出了基于特征点的实时眨眼检测算法,根据提取出的眼部特征点坐标,计算人眼宽高比EAR,因此根据定义的2D人眼长宽比模型,设置合适的阈值来进行眨眼检测。

上图中的6个特征点p1、p2、p3、p4、p5、p6是人脸特征点中对应眼睛的6个特征点。
我们要思考的是,这些点在眼睛睁开和闭合时,彼此坐标之间的关系。如图中直线所示,我们可以看出,长宽比在眼睛睁开和闭合时会有所不同。因此,我们可以导出EAR的方程:
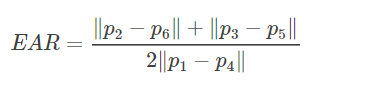
分子中计算的是眼睛的特征点在垂直方向上的距离,分母计算的是眼睛的特征点在水平方向上的距离。由于水平点只有一组,而垂直点有两组,所以分母乘上了2,以保证两组特征点的权重相同。我们不难发现,EAR在眼睛睁开时是基本保持不变的,在小范围内会上下浮动,然而,当眼睛闭合时,EAR会迅速下降。这也就是我们进行眨眼检测的原理,同时根据实验得出,当眼睛睁到最大时,人眼宽高比EAR一般在0.45以上,闭眼时人眼宽高比EAR 为0,人眼宽高比EAR在0.25及以上为睁眼,人眼宽高比EAR在0到0.25之间为闭眼。本文中眨眼检测使用通用USB摄像头进行拍摄,拍摄速度为25帧每秒,帧间间隔为40毫秒,即一次眨眼动作可以拍到6-7张图像。通过对视频序列中毎一帧图像计算EAR值,同时统计EAR值低于0.25的帧数就可以判断出眨眼次数。当眨眼次数大于2时,即判断该视频通过眨眼检测。
五:人脸姿态检测
人脸姿态估计主要是获得脸部朝向的角度信息。一般可以用旋转矩阵、旋转向量、四元数或欧拉角表示(这四个量也可以互相转换)。一般而言,欧拉角可读性更好一些,使用更为广泛。
计算步骤如下:
1)首先定义一个具有n个关键点的3D脸部模型,n可以根据自己对准确度的容忍程度进行定义,以下示例定义6个关键点的3D脸部模型(左眼角,右眼角,鼻尖,左嘴角,右嘴角,下颌);
2)采用人脸检测以及面部关键点检测得到上述3D脸部对应的2D人脸关键点;
3)采用Opencv的solvePnP函数解出旋转向量;
4)将旋转向量转换为欧拉角;
六:活体检测技术性能指标
为了度量抗欺骗方法的安全性和活体检测的性能,需要有合适的方法去评估。
常用的性能度量指标有错误拒绝率(FRR),错误接受率(FAR),等错误率(EER),、获取错误率和平均处理时间等。
下面对活体检测方法的这些指标作些说明:
1: LFRR错误拒绝率:合法活体用户尝试登陆被认为不是活体而拒绝的次数除以合法用户尝试登陆的总次数。
2:LFAR错误接受率:欺骗攻击被接受为活体合法用户的次数除以欺骗攻击的总次数。
3:获取错误率:系统因不能获取信息而作出活体判断的次数除以尝试获取信息的总次数。
由于单个FAR或FRR不能评估系统性能,所以一般我们把FRR和FAR相等时的错误率作系统的评估指标,称为等错误率EER.当EER值较小时,表示系统性能较高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号