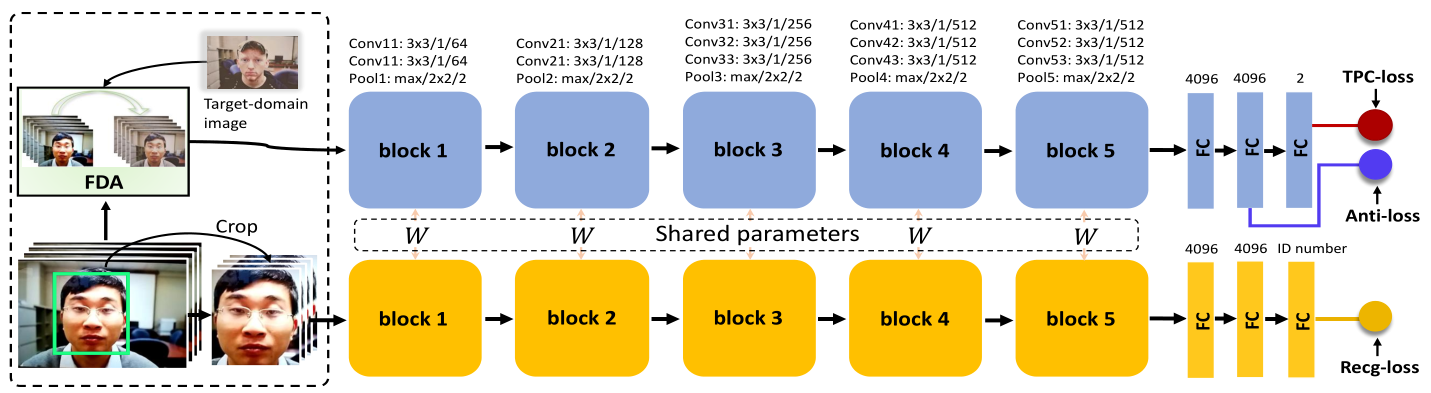
Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
1.论文的创新点:
1.提出了一个TCP(完全成对混淆Total Pairwise Confusion)loss用来增加CNN的泛化能力。
2.将FDA(快速域适应Fast Domain Adaptation)整合到CNN中,以减轻domain changes带来的影响。
3.提出了一个多任务学习方式,即用一个CNN同时完成活体检测和人脸识别两个任务。
1.针对第一点创新(提出了一个TPC loss)
灵感来自(Pairwise confusion for fine-grained visual classi-fication. In ECCV, pages 70–86, 2018)这篇文章中所提出的PC(Pairwise confusion)loss:即缩小类别之间条件概率分布的距离去混淆网络,已达到尽量较少学习判别特征。X(i,j)是随机从训练样本对里面抽取的两个样本,M为训练集中总样本对数目。
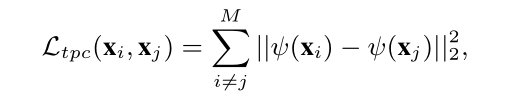
一.TPC loss和PC loss主要不同:
1.抽取样本方式不同,TPC是随机抽取,而PC是从两个不同类别中抽取。
2.TPC是最小化特征空间的欧式距离,而PC是最小化概率空间的距离,以此达到使样本对之间概率分布相似。
二.基于PC修改成TPC方式的原因:
1.针对二分类任务,混淆的引入并不会影响其分类性能
2.如下图,改变了样本分在特征空间的特征分布,增强了其泛化能力。
3.对于一个二分类任务,在特征空间的正则化比在概率空间更有用。
三.关于TPC loss能改善其泛化能力的说明:
假设活体和非活体分别有K个特征模式,F-live=(f1,f2....fk),F-spoof=(f1,f2....,fk)(根据contribution依次排列)
L-anti loss是增大F-live和F-spoof的特征距离,为了得到更好判别器。
TCP loss是缩小F-live和F-spoof之间的差异。
L-anti loss和TCP loss相互作用就是为了达到一个平衡状态。
2.针对第二点创新FDA(Fast Domain Adaptation)的引入
一般来说一幅图片包含着两种成分:content和appearance,其中appearance可以认为是image style,不同样本之间domain是不同的。 对于活体检测,domain variance会引起样本在特征空间分布的不相似,降低了活体检测模型的性能,所以引入FDA去减少domain change带来的负面影响。
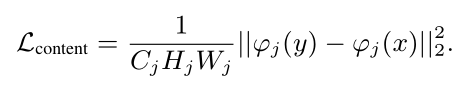

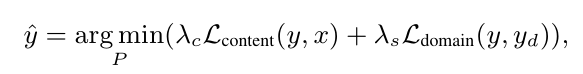
其中,y is output image,yd is target image, x is input image,G(y)是F-范数(矩阵A各项元素的绝对值平方的总和)ϕ(·) 表示一种损失网络。

CNN block的基础网络结构是VGG16,并且使用在vgg-face数据库上的预训练模型。λ1设置为0.1,λ2设置为2.5e-10。
Intra-Test 和Cross-Test 对比结果。

讨论:1.TCP对迁移域的效果比较大。2.FAD可以进一步增强网络泛化能力。
在MFSD上的评估结果:
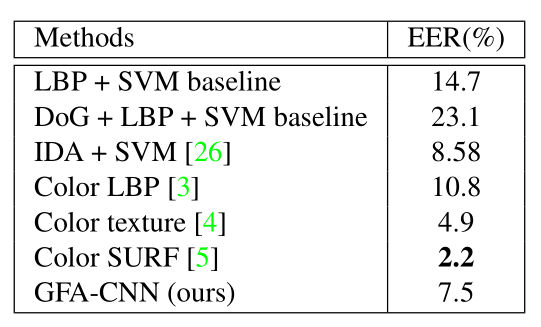
讨论:TCP的加入,导致在Intra-test上效果不好。
与其他结果比较:
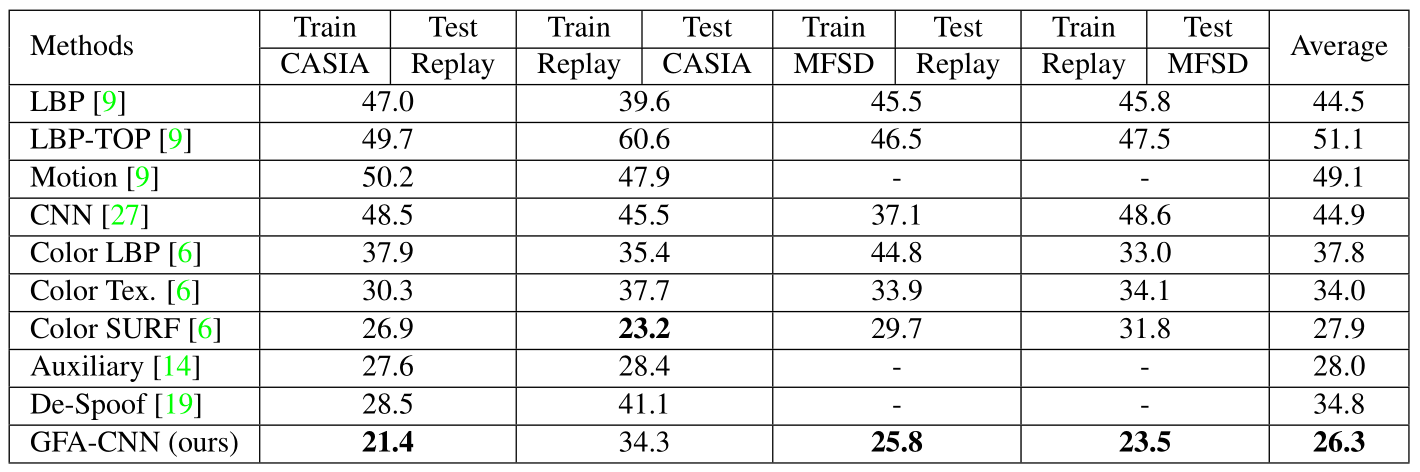
讨论:上表中Replay到CASIA结果并不好,论文描述的是主要因为Replay数据分辨率(Replay:320*240 CASIA:720*1280)和CASIA的不同,导致在进行FDA的时候存在了一个resolution gap,降低了转换图片的质量,导致性能下降。
人脸识别评估结果:
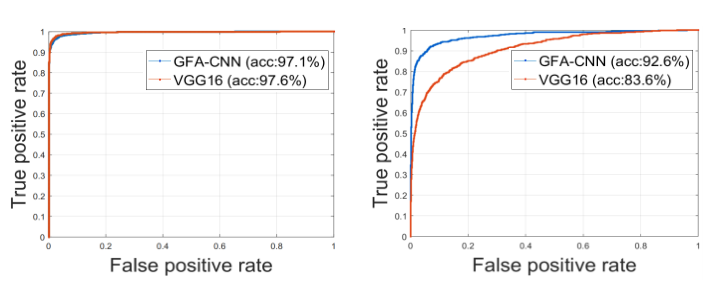
讨论:在siw 数据集上VGG16性能低,主要是在非活体中,丢失了一些比较好的人脸细节。而GFA-CNN性能仍然很不错主要是因为活体检测和人脸识别两个任务的相互增强,使得人脸识别任务对活体检测不是很敏感。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号