Text-CNN模型作为文本分类模型,通过验证实验以及业界的共识,在文本分类任务中,CNN模型已经能够取到比较好的结果,虽然在某些数据集上效果可能会比RNN稍差一点,但是CNN模型训练的效率更高。所以,一般认为CNN模型在文本分类任务中是兼具效率与质量的理想模型。针对海量的文本多分类数据,也可以尝试一下浅层的深度学习模型FastText模型,该模型的分类效率更高。

Text-CNN模型结构:
Text-CNN模型的整体网络架构如图所示。整个模型由四部分构成:输入层、卷积层、池化层、全连接层。
1.输入层(词嵌入层):
Text-CNN模型的输入层需要输入一个定长的文本序列,我们需要通过分析语料集样本的长度指定一个输入序列的长度L,比L短的样本序列需要填充,比L长的序列需要截取。最终输入层输入的是文本序列中各个词汇对应的词向量。
2.卷积层:
在NLP领域一般卷积核只进行一维的滑动,即卷积核的宽度与词向量的维度等宽,卷积核只进行一维的滑动。在Text-CNN模型中一般使用多个不同尺寸的卷积核。卷积核的高度,即窗口值,可以理解为N-gram模型中的N,即利用的局部词序的长度,窗口值也是一个超参数,需要在任务中尝试,一般选取2-8之间的值。

3.池化层:
在Text-CNN模型的池化层中使用了Max-pool(最大值池化),即减少了模型 的参数,又保证了在不定长的卷基层的输出上获得一个定长的全连接层的输入。
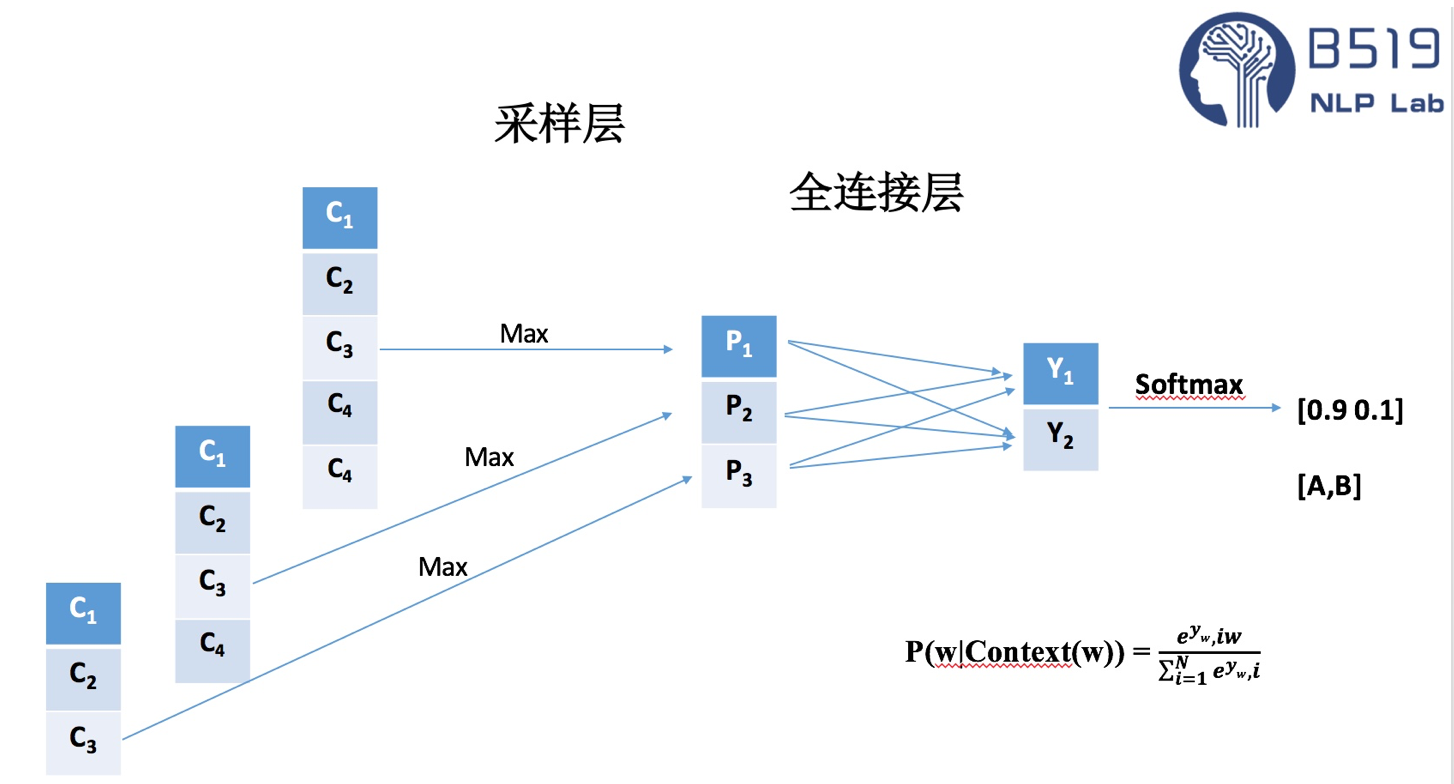
卷积层与池化层在分类模型的核心作用就是特征提取的功能,从输入的定长文本序列中,利用局部词序信息,提取初级的特征,并组合初级的特征为高级特征,通过卷积与池化操作,省去了传统机器学习中的特征工程的步骤。
4.全连接层:
全连接层的作用就是分类器,原始的Text-CNN模型使用了只有一层隐藏层的全连接网络,相当于把卷积与池化层提取的特征输入到一个LR分类器中进行分类。至此,Text-CNN的模型结构就算大体了解了,有人把深度学习模型看作一个黑盒子,知道格式化的输入,我们就可以利用别人搭建好的模型框架训练在自己的数据集上实现一定的功能。但是在不同的数据集上,模型的最佳状态也不唯一,这就需需要我们在新的数据集上需要进行调优(调参)。
5.模型的效果评估与调优
针对分类问题,一般可以使用准确率、召回率、F1值、混淆矩阵等指标,在文本多标签分类中一般还会考虑标签的位置加权等问题。分类模型中的主要参数:词向量的维度、卷积核的个数、卷积核的窗口值、L2的参数、DropOut的参数、学习率等。这是在模型优化的过程中需要重点关注的参数。此外,一般数据集的类别不均衡问题对模型的影响也是比较显著的,可以尝试使用不同的方法,评估不同方案的模型效果。
文本分类中经常遇到的问题:
1.数据集类别不均衡
即语料集中,各个类别下的样本数量差异较大,会影响最终文本分类模型的效果。 主要存在两类解决方案:(1)调整数据:数据增强处理,NLP中一般随分词后词序列进行随机的打乱顺序、丢弃某些词汇,然后分层采样的方式来构造新的样本数据。

数据增强
(2)使用代价敏感函数:例如图像识别中的Focal Loss等。
2.文本分类模型的泛化能力
首先,对于一个未知的样本数据,分类模型只能给出分类标签中的一个,无法解决不属于分类标签体系的样本。我们无法预知未来的数据会是什么样的,也不能保证未来的所有分类情况在训练集中都已经出现过!剩下影响分类模型泛化能力的就是模型过拟合的问题了。
过拟合问题
如何防止过拟合?: (1)数据上:交叉验证 ;(2)模型上:使用DropOut、BatchNorm、正则项、Early Stop。
转载:https://cloud.tencent.com/developer/article/1335257

 浙公网安备 33010602011771号
浙公网安备 33010602011771号