Scrapy框架立项
一、安装Scrapy
pip install scrapy
二、创建scrapy项目
scrapy startproject my_spider
三,创建爬虫文件
scrapy genspider example example.com #example 文件名称 #example.com 爬取网站地址 #如:scrapy genspider baidu baidu.com
出现下图就创建成功

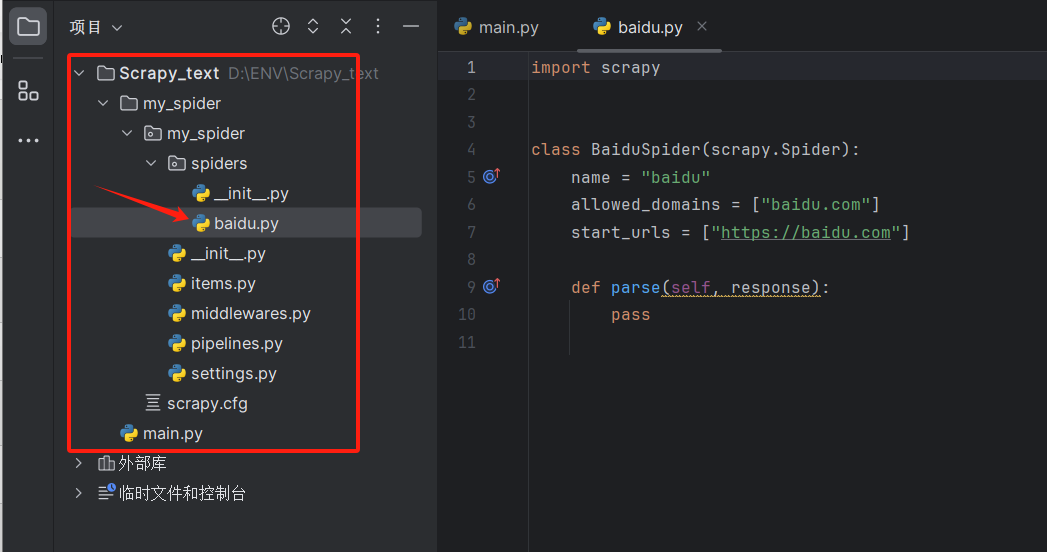
四、运行刚才创建的爬虫文件
1 | scrapy crawl baidu |
五、用代码运行Scrapy项目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import scrapyfrom scrapy import cmdline #导入这个文件class QingtingSpider(scrapy.Spider): name = "qingting" allowed_domains = ["m.qingting.fm"] start_urls = ["https://m.qingting.fm/rank/"] def parse(self, response): print('测试',response) passif __name__ == '__main__': cmdline.execute('scrapy crawl qingting'.split()) #写入这行代码 |
六、scrapy变量声明
#首先需要导入HtmlResponse包 from scrapy.http import HtmlResponse 如何在parse函数中使用 def parse(self, response:HtmlResponse): print('测试',response) pass


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?