scrapy爬虫笔记
https://www.bilibili.com/video/BV1Yh411o7Sz?p=60&spm_id_from=pageDriver
#scrapy框架
'''
什么是框架?
集成了很多功能并且具有很强通用性的一个项目模板
如何学习框架?
专门学习框架封装的各种功能的详细用法
什么是scrapy?
爬虫中封装好的一个明星框架。功能:高兴能持久化存储,异步数据下载,数据解析,分布式
scrapy框架的基本使用
环境安装:
mac or linux: pip install scrapy
windows;
pip install scrapy
测试:在终端里录入scrapy指令,没有报错即表示安装成功!
创建一个工程:scrapy startproject xxxPro
cd xxxPro
在spiders子目录中创建一个爬虫文件
scrapy genspider spideName www.xxx.com
执行工程:
scrapy crawl spiderName
scrapy crawl first --nolog #无日志信息
'''
#first文件
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫文件名称:就是爬虫源文件的唯一标识
name = 'first'
#允许的域名:用来限定start_urls中哪些url可以进行请求发送,一般不会用
#allowed_domains = ['www.baidu.com']
#起始的url列表:可以更改,可以有多个url,该列表中存放的url会被scrapy自动进行请求发送
start_urls = ['http://www.baidu.com/','https://www.sougou.com']
#用作数据解析:response参数表示请求成功后对应的相应对象
def parse(self, response):
print(response)
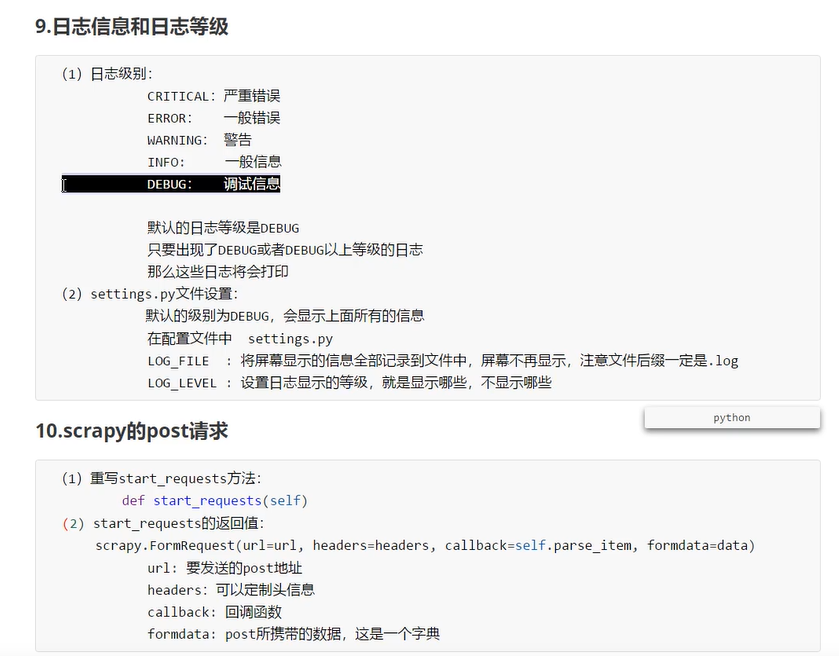
更改scrapy下settings.py文件内容为
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False#机器人协议
LOG_LEVEL='ERROR'#只允许错误日志出现
'''
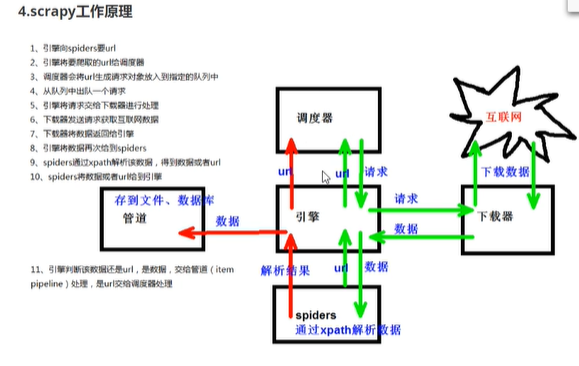
1.
scrapy项目的结构
项目名字
项目名字
spiders.文件夹(存储的是爬虫文件)
init
自示义的爬虫文件 核心功能文件
init
items 定义数据结构的地方爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robotst协议,ua足义等
2.response的属性和方法
response.text返回response文本文件
response.body返回response二进制文件
response.xpath返回response可以直接xpath解析response内的内容
response.extract()提取seletor对象的data属性值
response.extract()提取seletor列表的第一个数据
'''
scrapy shell
1.什么是scrapy shel1? scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取 数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码, 该终端是用来测试xPathi或Css表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该 终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。 一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用.
进入到scrapy shell终端 直接在windows终端中输入scrapy shell 域名
如果看到一些高亮或者自动补全 那么可以安装ipython pip install ipython
尚硅谷当当scrapy框架笔记 - wzc6 - 博客园 (cnblogs.com)
scrapy shell https://www.dushu.com/book/1188.html
from scrapy.linkextractors import LinkExtractor
link =LinkExtractor
link2=LinkExtractor(restrict_xpaths=r'/html/body/div[6]/div/div[2]/div[2]/ul/li[1]/div/div/a ')
link.extract_links(response)
尚硅谷读书网爬取笔记 - wzc6 - 博客园 (cnblogs.com)
更改scrapy下settings.py文件内容为
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False#机器人协议
LOG_LEVEL='ERROR'#只允许错误日志出现,指定日志级别
LOG_FILE='logedemo.log'#把日志信息打印在log文件中
post请求
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['fanyi.baidu.com']
#post请求如果没有参数,那么请求无意义
#所以start_urls也没有用了
#parse方法也没用了
# start_urls = ['https://fanyi.baidu.com/sug']
#
# def parse(self, response):
# pass
def start_requests(self):
url='https://fanyi.baidu.com/sug'
data={'kw':'final'}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)#post请求用formrequests
def parse_second(self,response):
content=response.text
obj=json.loads(content)
print(obj)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号