

正则表达式:字符串匹配;官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
re模块:python处理正则 ----------------------------------------在线测试工具 http://tool.chinaz.com/regex/
^(13|14|15|18)[0-9]{9}$--------------手机号码筛选 以^(13|14|15|18)开头,0-9重复9次
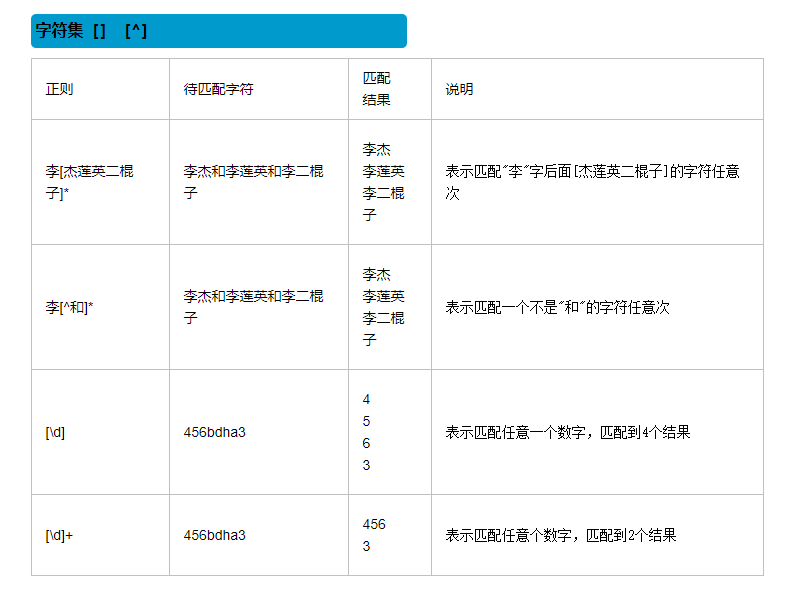
1.字符组 : [字符组]
[0123456789]等价于[0-9]
[0-9a-fA-F]综合匹配指定字符
2.字符
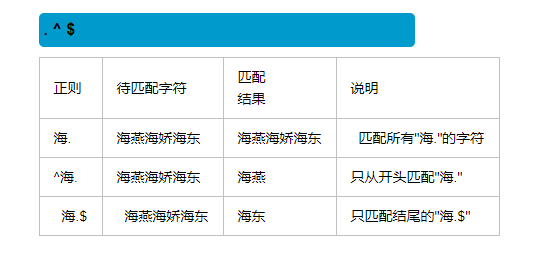
. 匹配换行符以外的任意字符
\w 匹配字母数字下划线 \W 匹配非字母数字或下划线
\s 匹配任意空白符 (space) \S 匹配非空白符
\d 匹配数字(digit) \D 匹配非数字
\n 匹配一个换行符
\t 匹配一个制表符(tab)
\b 匹配一个单词结尾(a\b----判断是否以a结尾)
^ 匹配字符串开始(^A----判断是否以A开始)
$ 匹配字符串结束(A$判断是否以A结尾)
a|b 匹配字符a或b
() 匹配括号内的表达式,也表示一个组
[……] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
3.量词
* 重复0次或更多次 ------李.* (李后面字符全部匹配出来)*表示重复零次或多次,即匹配"李"后面0或多个任意字符
+ 重复一次或更多次 -------李.+ (李后面字符全部匹配出来)+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符
? 重复0次或一次 -------李.? (李后面任意一个字符) ?表示重复零次或一次,即只匹配"李"后面一个任意字符
前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次 ---------李.{1,3}---{1,3}匹配1到3次任意字符
4. .^$使用
5.转义字符
用到了r'\n'这个概念

6.贪婪匹配/非贪婪匹配
默认为贪婪匹配模式,会匹配尽量长的字符串
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复 ------------------------------------------ . 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号