
java集合笔记
集合
1.集合分类
使用集合前都是使用的数组,但是数组有缺点.
数组缺点:
1.长度固定不可修改;
2.保存的必须为同一类型元素;
3.增加删除元素麻烦;
集合的优点:
1.可以动态保存任意多个对象(动态扩容);
2.提供了操作对象的方法(增删改查:add ,remove,set,get);
3.可以保存不同类型的数据;
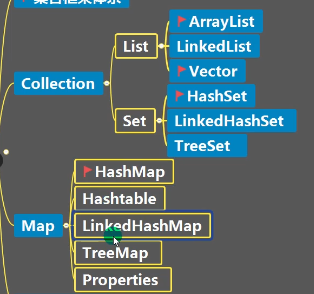
1.1collection集合体系图
collection 接口有两个重要的子接口,list和set,他们的实现子类都是单列集合.
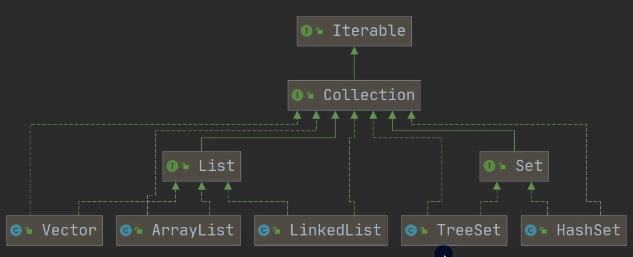
1.2map集合体系图
map接口的实现子类是双列集合,存放的是k——v的键值对;

2.collection接口
1.collection接口的特点:
1.collection实现子类可以存放多个元素,元素类型可以说Object
2.Collection的实现类,有些可以存放相同元素,list可以存放 set不行
3.collection实现类 list是有序的,set无序
4.collection没有直接的实现子类,通过list,set接口实现的
2.1collection接口常用方法:

1.iterator
所有实现collection接口的子类都可以用iterator进行遍历,
iterator进行遍历示例代码:
//创建一个 collection 集合
Collection clo =new ArrayList();
//调用iterator方法
Iterator iterator = col.iterator();
//调用 hasNext方法判断是否还有元素,如果没有元素则返回false 循环结束
while(iterator.hasNext()){
//如果有元素则调用Next方法,则返回该元素
//返回元素类型为object
Object object= clo.Next();
}
如果希望重置遍历
iterator=col.iterator();
iterator接口的方法和注意事项:

2.增强for
增强for增强for底层依然是迭代器
示例代码:
public static void main(String[] args) {
Collection collections = new ArrayList();
collections.add("11");
collections.add("12");
collections.add("13");
collections.add("14");
ArrayList arrayList = new ArrayList();
for (Object collection : collections) {
arrayList.add(collection);
}
System.out.println(arrayList);
}
3.for each
for each 使用的话需要Consumer() 重写Consumer()方法,可以使用lomab表达式代替。
示例代码
public class demo1 {
public static void main(String[] args) {
Collection collections = new ArrayList();
collections.add("11");
collections.add("12");
collections.add("13");
collections.add("14");
ArrayList arrayList = new ArrayList();
collections.forEach(o -> {
arrayList.add(o);
});
System.out.println(arrayList);
}
}
3List
1.List接口基本介绍
1.list集合元素有序(取出是按添加顺序取出的),元素可重复;
2.list元素内的每个元素都有其对应的索引,索引与元素一一对应;
3.list集合支持索引删除;
2.List接口常用方法

3.1ArrayList
1.arrayList介绍
1.arrayList是线程不安全的,源码方法没有加synchronized(没加锁)
2.arrayList底层实现是数组,自动扩容
3.arrayList查询快,增删慢.
2.arrayList源码

1.transient 表示瞬间,短暂的 该属性不会被序列化
2.不指定长度时 elementData初次执行是一个空数组,指定长度,则为指定长度的数组。扩容时就是指定长度的1.5倍扩容
3.arraylist扩容机制
刚开始new 出来arraylist时(没有指定长度)默认创建一个长度为10的数组,如果指定长度则按照指定长度创建,继续添加数据,底层判断是否需要扩容,当数据添加满数组时则出发扩容(grow方法),数组长度增长为原来的1.5倍。
3.2.vector
1.vector基本介绍

2.vector和arrayList的比较

3.vector扩容机制
vector底层也是数组,不指定长度的化默认创建长度为10的数组,继续添加数据当数据填满数组时则触发扩容机制,长度为原来二倍。
3.3LinkedList
1.linkedLis介绍
1.linkedList底层实现了双向链表和双端队列特点
2.可以添加任意类型元素,包括null
3.线程不安全,没有实现同步
4.查询慢,增删快
2.LinkedList底层

3.LinkedList代码模拟
public class LinkedList_ {
public static void main(String[] args) {
//创建三个节点 模拟三个数据
Node cat = new Node("cat");
Node dog = new Node("dog");
Node fish = new Node("fish");
//将三个节点进行相互关联 ,nex指向下一个,pre指向上一个
// cat-->dog-->fish
cat.nex = dog;
dog.nex = fish;
//因为是双向链表,pre属性也要执行上一个
// cat<--dog <--fish
fish.pre = dog;
dog.pre = cat;
//让first节点引用指向第一个节点,last指向最后一个节点
Node first = cat;
Node last = fish;
//从fist节点(首节点)遍历
while (true) {
if (first == null) break;
System.out.println(first);
first = first.nex;
}
System.out.println("********************");
//last(尾节点)遍历
while (true) {
if (last == null) break;
System.out.println(last);
last = last.pre;
}
//模拟删除数据
System.out.println("**********删除***********");
// 如果删除狗节点
//修改节点关联的数据
cat.nex = fish;
first=cat;
fish.pre = cat;
last=fish;
System.out.println("**********删除后查看*******");
while (true) {
if (first == null) break;
System.out.println(first);
first = first.nex;
}
//新增一个节点dog在cat和fish间
System.out.println("*******新增**********");
Node dog1 = new Node("dog1");
cat.nex=dog1;
dog1.nex=fish;
fish.pre=dog1;
dog1.pre=cat;
first=cat;
last=fish;
while (true) {
if (first == null) break;
System.out.println(first);
first = first.nex;
}
}
//定义一个node类 模拟链表一个节点
static class Node {
public Object item;//真正存放数据
public Node nex;//指向下一个节点
public Node pre;//指向前一个节点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node name=" + item;
}
}
}
4.linkedList和arrayList的比较
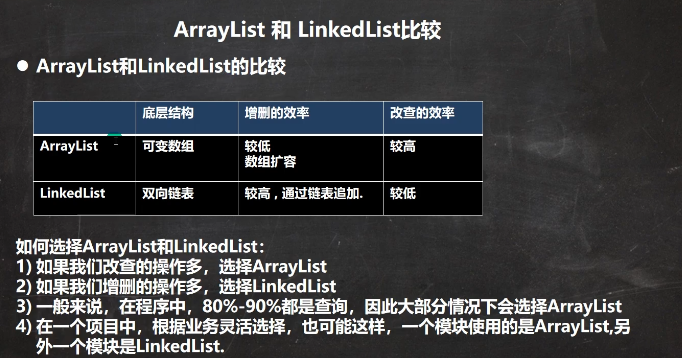
4.1为什么arraylist比linkedlist查询效率高?
arrayList实现了了radomAcess有随机标识,也就是arraylist可以通过数组索引进行,随机查找,而linkedlist底层是链表只能一个个查找所以arraylist相比较linkedlist查询效率高,
4.2为什么linkedlist比arraaylist增删改效率高?
linkedlist添加,删除和修改只需要修改对象位置相邻节点的指向,而arraylist如果添加数据到数组中任意位置则需要其后所有数组进行改变,所以linkedlist增删改效率高。
4.set接口
1.set接口介绍
1.set接口是无序的(放入和取出顺序不一致),没有索引。
2.set集合元素唯一,不能重复,所以最多包含一个null。
2.set接口常用方法
1.set接口和list接口一样,可以使用collection接口的方法。
2.set遍历可以使用迭代器(iterator),增强for。
3.set没有所以。不能使用普通for循环。
4.set遍历也可以使用for each
4.1Hashset
1.hashset介绍
1.hashSet的底层是hashMap。
2.存放元素不能重复。null只能有一个。
3.hashSet不保证元素是有序的,取决于hash后,在 确定索引的结果.
4.hashSet执行add方法时是会返回一个Boolean值,成功为true失败为false。
5.hashSet不能添加相同元素,但是如果添加的是对象,但对象内容相同是可以添加的!
2.HastSet底层
1.hashSet的底层是hashMap。HashMap的底层是(数组+链表+红黑树)。
2.创建hashset时首先创建了一个16位大小的数组,添加进hashset的值通过hash运算得到索引值,确定值储存在数组的索引位置。如果数组上还没有值则把值添加进数组上,如果再次添加的数据通过hash运行,分配给了相同的数组即数组该位置已有值,则调用equals方法进行比较,如果比较结果相同则放弃添加,如果equals比较不相同则形成链表结构,把值最加进链表最后。如果链表大小到达8同时数组(table表)提升到64则自动转换为红黑树结构,提升效率。

3LinkedHashSet

特点:
1.linkedHashSet 加入元素顺序和取出一致。
2.linkedHashSet底层是.linkedHashMap。是HashMap的子类
3..linkedHashSet底层是(数组(taable)+双向链表)
4.第一次添加时,直接将数组(table)扩容到16
4.2treeSet
1.treeset介绍
1.TreeSet的底层是TreeMap,
2.添加的数据存入了map的key的位置,而value则固定是PRESENT(占位作用)。
3.TreeSet中的元素是有序且不重复的,因为TreeMap中的key是有序且不重复的
4.线程不安全
2.TreeSet对元素进行排序的方式:
1.TreeSet中判断元素唯一性的方法是:根据比较方法的返回结果是否为0,如果是 0,则是相同元素,不存,如果不是0,则是不同元素,存储
2.元素自身不具备比较功能,则需要实现(java.until包下)Comparator接口,并覆盖其compare方法。
3.元素自身具备比较功能,即自然排序,需要实现(java.lang包下)Comparable接口,并覆盖其compareTo方法。
public class DEMO2 {
public static void main(String[] args) {
TreeSet set =new TreeSet(new Comparator(){
@Override
public int compare(Object o1, Object o2) {
return (int)o1-(int)o2;
}
} );
set.add("3");
set.add("1");
set.add("a");
set.add("b");
System.out.println(set);
}
}
*********************************************************
package com.wz.demo1;
import java.util.Comparator;
import java.util.TreeMap;
@SuppressWarnings("all")
public class treemap {
public static void main(String[] args) {
TreeMap treeMap=new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).compareTo((String) o2);
}
});
treeMap.put("xing","熊王");
treeMap.put("asd","猫王");
treeMap.put("sfsa","狗王");
treeMap.put("sfaf","虎王");
treeMap.put("gfsa","鹅王");
treeMap.put("qwe","鸟王");
System.out.println(treeMap);
}
}
3.treeSet和hashset的区别
1.HashSet 保存的数据是无序的,TreeSet保存的数据是有序的,
2.TreeSet可以自动排序。
3.TreeSet 依靠的是Comparable 来区分重复数据; 4.HashSet 依靠的是hashCode()、equals()来区分重复数据 5.Set 里面不允许保存重复数据。
4.treeSet和hashset是如何去重的
5.map接口
1.map接口介绍及常用方法

1.map以key-vaule形式存值;
2.不允许重复:当有相同的key时 后加的对象替换前对象,可以允许相同vaule
3.可以有一个key为null
4.常用字符串作为key(其他类型也可以!!!!)

2.map遍历
为了方便遍历,map把k-v的值放入entity集合中。
然后就可以用增强for获取这个entity集合。
HashMap map=new HashMap();
map.put(1,"a");
map.put(2,"a1");
map.put(21,"1a");
map.put(11,"2a");
Set set = map.entrySet();
for (Object o : set) {
System.out.println(o);
}
Map接口常用方法:
1.containsKey:查找键是否存在;
2.keySet:获取所有的键;
3.entrySet:获取所有k-v键值对;
4.values:获取所有值;
@SuppressWarnings("all")
public class maaap {
public static void main(String[] args) {
HashMap map = new HashMap();
person person1 = new person(001, 5000, "小王1");
person person2 = new person(002, 4100, "小王2");
person person3 = new person(003, 2800, "小王3");
person person4 = new person(004, 3700, "小王4");
person person5 = new person(005, 14400, "小王5");
map.put(person1.id, person1);
map.put(person2.id, person2);
map.put(person3.id, person3);
map.put(person4.id, person4);
map.put(person5.id, person5);
System.out.println("**************增强for遍历************");
Set set = map.keySet();
for (Object o : set) {
person vaule = (person)map.get(o);
if (vaule.getSal()>4000) System.out.println("员工的编号为:"+o+" 员工的名字为:"+vaule.name +" 员工的工资为:"+vaule.sal);
else continue;
}
System.out.println("**************迭代器遍历************");
//获取迭代器
Iterator iterator = map.entrySet().iterator();
while (true) {
if (!iterator.hasNext()) break;
Map.Entry next = (Map.Entry) iterator.next();
person value = (person)next.getValue();
if (value.getSal()>4000)
System.out.println(value.getName()+value.getSal());
else continue;
}
}
static class person {
int id;
int sal;
String name;
@Override
public String toString() {
return "person{" +
"id=" + id +
", sal=" + sal +
", name='" + name + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public person(int id, int sal, String name) {
this.id = id;
this.sal = sal;
this.name = name;
}
}
}
3.map接口小结
5.1HashMap
1.HashMap扩容机制

详情见 4.1.2和hashset一样。
5.2hashtable
1.基本介绍
1.hashtable存放的也是键值对;
2.hashtable和hashmap相比,hashtable的键不能为null;
3.hashtable线程安全,方法都有锁;
4.hashtable以弃用,想要线程安全用ConcurrentHashMap;
2.hashtable扩容机制
1.hashtable底层是数组,初始值为11;
2.加载因子为0.75,当添加数组到达阈值则触发扩容 扩容长度为2n+1
3.hashMap和hashTable对比

5.3properties类
1.基本介绍

Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存属性集。不过Properties有特殊的地方,就是它的键和值都是字符串类型。
如果键相同后替换前面的
https://www.cnblogs.com/xudong-bupt/p/3758136.html
5.4ConcurrentHashMap
1.ConcurrentHashMap介绍
ConcurrentHashMap是HashMap的线程安全版本,内部也是使用(数组 + 链表 + 红黑树)的结构来存储元素。相比于同样线程安全的HashTable来说,效率等各方面都有极大地提高。
2.ConcurrentHashMap总结
ConcurrentHashMap的底层和hashmap相同但是它的方法上添加了synchronized锁,它并没有把整个map给锁住,它只是锁住了链表/红黑树头。
当添加数据时经过hash取模计算,其得到的值并不相同则相互之间并不影响操作.
5.5treeMap
1.treeMap介绍
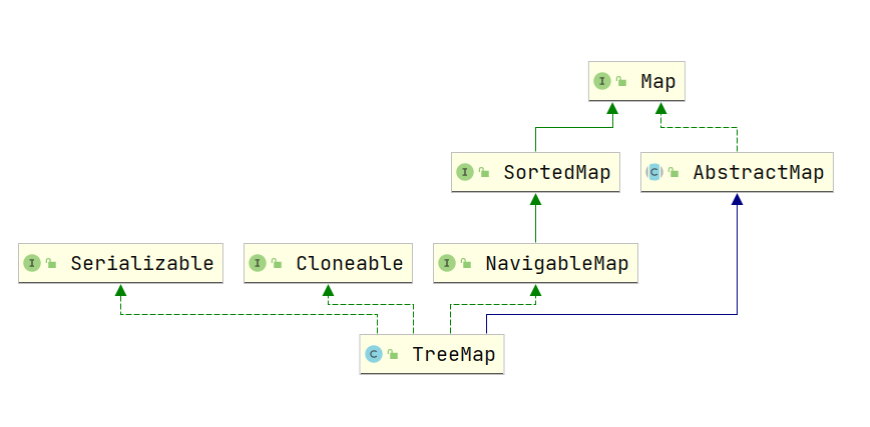
1.TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。 2.TreeMap 实现了 SortedMap 接口,表示它的Key是有序的。支持获取头尾 Key-Value 元素,或者根据Key指定范围获取子集合等。插入的Key 必须实现Comparable 或者 提供额外的比较器 Comparator,所以Key不允许为null, 但是Value可以 3.TreeMap 实现 NavigableMap 接口继承了 SortedMap 接口,根据指定的搜索条件返回最匹配的Key-Value元素。不同于HashMap,TreeMap 并非一定要覆写hashCode 和 equals 方法来达到Key去重的目的。 4.TreeMap 实现了Cloneable接口,意味着它能被克隆。 5.TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
6.Collections工具类
1.介绍及基本方法


7.集合的选择


 浙公网安备 33010602011771号
浙公网安备 33010602011771号