贪心
概念:
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,算法得到的是在某种意义上的局部最优解 。
性质:
存在问题:
实例:
实例一:分数背包问题
有n个物体,第i个物体重量为wi,价值为vi,在总重量不超过C的情况下,让总价值最高,每个物品可以只取走一部分。
解析:
因为背包容量是一定的,且物品可以只拿一部分,我们希望拿到的物品单位价值尽可能的大,所以对所有物品经行单位价值从大到小的排序,从高到低依次取物品,直到装满背包。就可以得到最优结果。反证法,如果不这样拿,总能找到单位价值高的替换掉单位价值低的物品。
实例二:区间问题
1,数轴上有n个开区间(ai,bi),选择最多的区间使得选出的区间两两不相交
第一个选择谁?最早开始的?还是最早结束的?
这个问题十分明显,选了第一个对后续区间有什么影响?选了第一个区间设(2,3)则代表3以左的区间全部不能选了,所以为了使得选择的第一个区间对剩下区间影响小,应该选择右端点最小的区间。之后,排除掉不能再选的区间,就又回到了最初的问题。
代码:
#include <algorithm>
#include <iostream>
#include <cstring>
#include <vector>
#include <cstdio>
#include <cmath>
using namespace std;
const int maxn=1e3+10;
int n;
struct node{
int x;
int y;
}a[maxn];
bool cmp(node a,node b){
if(a.y!=b.y)return a.y<b.y;
return a.x<b.x;
}
int main(){
while(scanf("%d",&n)!=EOF){
if(n==0)break;
for(int i=0;i<n;i++){
scanf("%d%d",&a[i].x,&a[i].y);
}
sort(a,a+n,cmp);
int r=-1;
int num=0;
for(int i=0;i<n;i++){
if(a[i].x>=r){
num++;
r=a[i].y;
}
}
printf("%d\n",num);
}
return 0;
}
例二:poj1328
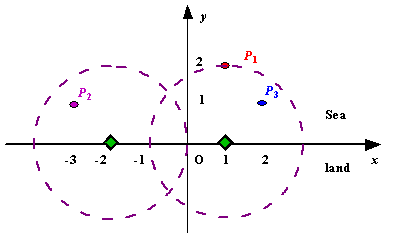
题意:假设海岸线是一条无限延伸的直线。陆地在海岸线的一侧,而海洋在另一侧。每一个小的岛屿是海洋上的一个点。雷达坐落于海岸线上,只能覆盖d距离,所以如果小岛能够被覆盖到的话,它们之间的距离最多为d。
首先进行数模转化,不考虑每个点可以覆盖那些小岛,考虑这个小岛可以被那些点覆盖。
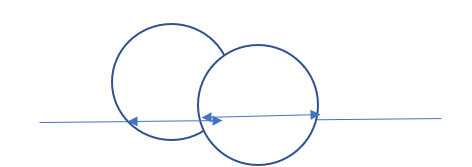
这样问题就变成了,区间上有一些线段,放最少的点,使每个线段中都有一个点。
和上题一样,第一个要考虑的问题使第一个放置的点选在哪里?
因为希望放置的点尽量的少,所以从左向右考虑,尽可能向有放置,又因为每个区间最少得有一个点,所以要放在最早结束得区间的右端点。
去掉已经有点的区间,又重复考虑这个问题即可得到答案。
#595 (Div. 3)d2,一道有意思的贪心题
题意:有n各区间,去掉最少的区间使得每个点的被覆盖次数小于等于k。
解:从左向右对每个点进行考虑,如果这个点的被覆盖次数大于k,那么覆盖整个点的区间至少有一个一个被删除掉。那么问题来了,删除那个?
删除覆盖这个点的区间右端点最大的那个,因为从左向右考虑,左端点已经不会对后继点产生影响,右端点最大的那个点影响的点最多,所以删除它。
代码:
#include<algorithm>
#include<iostream>
#include<cstdlib>
#include<fstream>
#include<cstring>
#include<bitset>
#include<cstdio>
#include<time.h>
#include<deque>
#include<queue>
#include<stack>
#include<cmath>
#include<map>
#include<set>
using namespace std;
const int maxn=5e5+10;
struct aa{
int x,lr,id;
}a[maxn];
int num[maxn];
bool cmp(aa a,aa b){
if(a.x!=b.x)return a.x<b.x;
else return a.lr<b.lr;
}
struct qq{
int rr;
int id;
qq(){}
qq(int _rr,int _id):rr(_rr),id(_id){}
bool operator<(const qq &x)const{
return rr<x.rr;
}
}q[maxn];
int vis[maxn];
int main(){
int n,m;
scanf("%d%d",&n,&m);
for(int i=0;i<n;i++){
int l,r;
scanf("%d%d",&l,&r);
a[i*2].x=l;
a[i*2+1].x=r;
a[i*2].lr=0;
a[i*2+1].lr=1;
a[i*2].id=i+1;
a[i*2+1].id=i+1;
q[i+1].rr=r;
q[i+1].id=i+1;
}
priority_queue<qq >idvis;
int sum=0;
int minnum=0;
sort(a,a+2*n,cmp);
for(int i=0;i<2*n;i++){
if(!vis[a[i].id]){
if(a[i].lr==0){
sum++;
//printf("%d %d...\n",a[i].x,q[a[i].id].rr);
idvis.push(qq(q[a[i].id].rr,a[i].id));
}
else{
sum--;
vis[a[i].id]=1;
}
if(sum>m){
qq xx=idvis.top();
//printf("%d++++\n",xx.id);
while(vis[xx.id]){
idvis.pop();
xx=idvis.top();
}
num[minnum++]=xx.id;
vis[xx.id]=1;
//printf("%d++++\n",xx.id);
sum--;
}
}
}
sort(num,num+minnum);
printf("%d\n",minnum);
for(int i=0;i<minnum;i++){
if(i==minnum-1)printf("%d\n",num[i]);
else printf("%d ",num[i]);
}
return 0;
}
注释:这里用到一个关于优先队列的小技巧,因为优先队列的本质是一个堆,所以我们只能访问和删除堆顶元素,当我们想删除堆中任意元素时,可以给他打上标记但不直接删除,在不断取出元素的过程中如果发现取出的元素已经标记它被删除,那么取出它后接着再取一次即可。
实例三:huffman编码(平均长度最短的码字)
假设目前有5种字符,在一文件中出现频率如下表:
| 字符 | a | b | c | d | e |
| 频率 | 45 | 16 | 12 | 13 | 9 |
赫夫曼编码的具体方法:先按出现的概率大小排队,把两个最小的概率相加,作为新的概率 和剩余的概率重新排队,再把最小的两个概率相加,再重新排队,直到最后变成1。每次相 加时都将“0”和“1”赋与相加的两个概率,读出时由该符号开始一直走到最后的“1”, 将路线上所遇到的“0”和“1”按最低位到最高位的顺序排好,就是该符号的赫夫曼编码.
第一步:
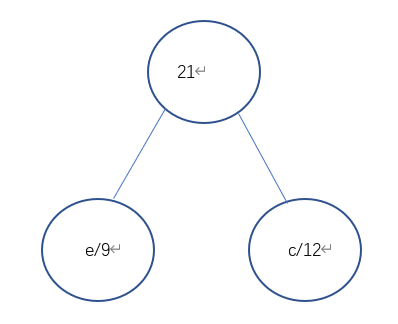
第二步:
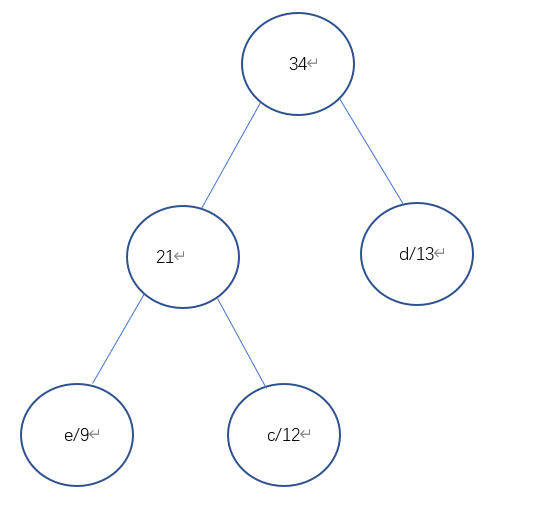
第三步:

第四步:

由此可以得出各个字符的编码如下表
| 字符 | a | b | c | d | e |
| 频率 | 45 | 16 | 12 | 13 | 9 |
| 编码 | 0 | 10 | 1110 | 110 | 1111 |
补:贪心算法的真确性需要证明,常见的证明方法
1,微扰(领项交换):再任何情况下微笑的改变等不能使得结果变的更好,则贪心方法真确,常用于以排序为贪心策略的证明。
2,范围缩放,局部最策略的作用范围扩大并不会使得整体变差
3,反证法:例如实例一
4,数学归纳法,例如实例二里的1
