
箱线图boxplot
箱线图boxplot——展示数据的分布
图表作用:
1.反映一组数据的分布特征,如:分布是否对称,是否存在离群点
2.对多组数据的分布特征进行比较
3.如果只有一个定量变量,很少用箱线图去看数据的分布,而是用直方图去观察。一般都要跟其余的定性变量做分组箱线图,可以起对比作用。(key)
适合数据类型:
针对连续型变量
用法:
只有一个变量、一组的数据(1个变量,0个定性变量),比如:学生的成绩情况
只有一个变量、多组数据(1个变量,1个定性变量[班级]),比如:1、2、3班学生的成绩情况
只有一个变量、多组数据(1个变量,多个定性变量[年级、班级]),比如:初一、初二、初三的1、2、3班学生的成绩情况
多个变量同理,看Y轴数据大小才相近才采用此用法
图表解读:
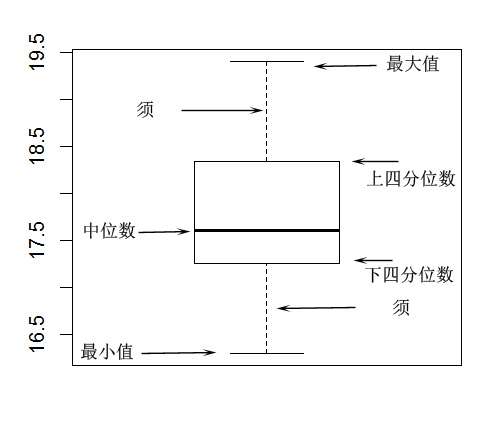
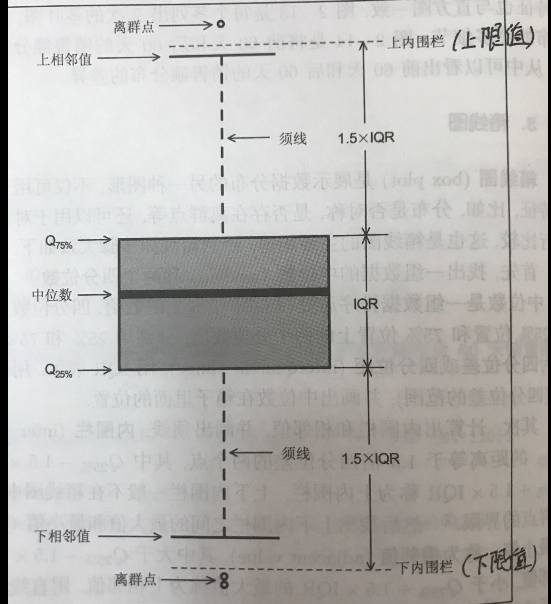
1.箱子的大小取决于数据的四分位距,即IQR = Q3 - Q1(Q3: 75%分位数 , Q1: 25%分位数 , Q3和Q1为四分位数)。50%的数据集中于箱体,若箱体太大即数据分布离散,数据波动较大,箱体小表示数据集中。
2.箱子的上边为上四分位数Q3,下边为下四分位数Q1,箱体中的横线为中位数Q2(50%分位数)
3.箱子的上触须为数据的最大值Max,下触须为数据的最小值Min(注意是非离群点的最大最小值,称为上下相邻值)
4.若数据值 > Q3+1.5 * IQR(上限值) 或 数据值 < Q1-1.5 * IQR(下限值) ,均视为异常值。数据值 > Q3+3 * IQR 或 数据值 < Q1-3 * IQR ,均视为极值。在实际应用中,不会显示异常值与极值的界限,而且一般统称为异常值。
- 也表明上下触须不一定是数据的最大最小值,
- (1)若数据的最大值比上限值小的,那么上触须顶点就是观察到的最大的;若数据的最大值比上限值大的,那么上触须顶点就是上限值,观察到的最大值就是异常点。
- (2)若数据的最小值比下限值大的,那么下触须顶点就是观察到的最小值;若数据的最小值比下限值小的,那么下触须顶点就是下限值,观察到的最小值就是异常点。
- 上述情况复杂,在线范围外的,直接理解成异常值即可
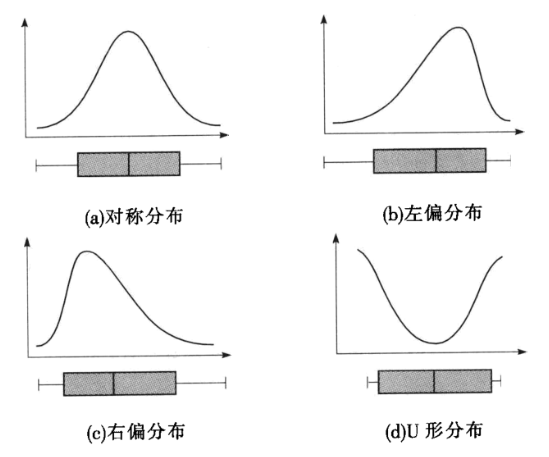
5.偏度:
- 对称分布:中位线在箱子中间,上下相邻值到箱子的距离等长,离群点在上下限值外的分布也大致相同。
- 右偏分布:中位数更靠近下四分位数,上相邻值到箱子的距离比下相邻值到箱子的距离长,离群点多数在上限值之外。
- 左偏分布:中位数更靠近上四分位数,下相邻值到箱子的距离比上相邻值到箱子的距离长,离群点多数在下限值之外。
作图实操:
下面是plt.boxplot()的参数
plt.boxplot(x,
notch=None,
sym=None,
vert=None,
whis=None,
positions=None,
widths=None,
patch_artist=None,
bootstrap=None,
usermedians=None,
conf_intervals=None,
meanline=None,
showmeans=None,
showcaps=None,
showbox=None,
showfliers=None,
boxprops=None,
labels=None,
flierprops=None,
medianprops=None,
meanprops=None,
capprops=None,
whiskerprops=None,
manage_xticks=True,
autorange=False,
zorder=None,
hold=None,
data=None)
- x:指定要绘制箱线图的数据;
- notch:是否是凹口的形式展现箱线图,默认非凹口;
- sym:指定异常点的形状,默认为+号显示;
- vert:是否需要将箱线图垂直摆放,默认垂直摆放;
- whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差;
- positions:指定箱线图的位置,默认为[0,1,2…];
- widths:指定箱线图的宽度,默认为0.5;
- patch_artist:是否填充箱体的颜色;
- meanline:是否用线的形式表示均值,默认用点来表示;
- showmeans:是否显示均值,默认不显示;
- showcaps:是否显示箱线图顶端和末端的两条线,默认显示;
- showbox:是否显示箱线图的箱体,默认显示;
- showfliers:是否显示异常值,默认显示;
- boxprops:设置箱体的属性,如边框色,填充色等;
- labels:为箱线图添加标签,类似于图例的作用;
- filerprops:设置异常值的属性,如异常点的形状、大小、填充色等;
- medianprops:设置中位数的属性,如线的类型、粗细等;
- meanprops:设置均值的属性,如点的大小、颜色等;
- capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等;
- whiskerprops:设置须的属性,如颜色、粗细、线的类型等;
例1
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")
plt.rcParams["font.sans-serif"]=["SimHei"] #正常显示中文标签
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
np.random.seed(800) #设置随机种子
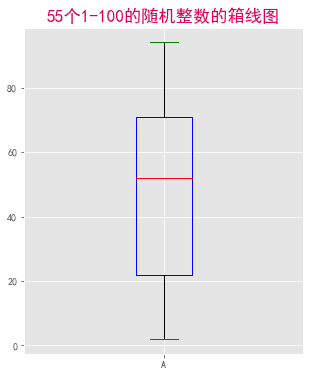
data=np.random.randint(1,100,55)
plt.figure(figsize=(5,6)) #设置图形尺寸大小
plt.boxplot(data,
notch=False, #中位线处不设置凹陷
widths=0.2, #设置箱体宽度
medianprops={'color':'red'}, #中位线设置为红色
boxprops=dict(color="blue"), #箱体边框设置为蓝色
labels="A", #设置标签
whiskerprops = {'color': "black"}, #设置须的颜色,黑色
capprops = {'color': "green"}, #设置箱线图顶端和末端横线的属性,颜色为绿色
flierprops={'color':'purple','markeredgecolor':"purple"} #异常值属性,这里没有异常值,所以没表现出来
)
plt.title("55个1-100的随机整数的箱线图",fontsize="xx-large",color="#DE0052")
plt.show()
例2
拿Titanic数据,作乘客年龄的箱线图
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv(r"G:\Kaggle\Titanic\train.csv")
any(train.Age.isnull()) #检查年龄是否有缺失
train.dropna(subset=["Age"], inplace=True) #删除含有缺失年龄的观测,即行
plt.style.use("ggplot") #使用ggplot的图形style
plt.rcParams["font.sans-serif"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False # 设置中文、负号正常显示
plt.figure(figsize=(5,6))
plt.boxplot(x = train.Age, # 绘图数据
notch = True, #设置中位线处凹陷,(注意:下图看起来有点丑)
patch_artist=True, # 设置用自定义颜色填充盒形图,默认白色填充
showmeans=True, # 以点的形式显示均值
boxprops = {"color":"black","facecolor":"#F43D68"}, # 设置箱体属性,填充色and 边框色
flierprops = {"marker":"o","markerfacecolor":"#59EA3A","color":"#59EA3A"}, # 设置异常值属性,点的形状、填充色和边框色
meanprops = {"marker":"D","markerfacecolor":"white"}, # 设置均值点的属性,点的形状、填充色
medianprops = {"linestyle":"--","color":"#FBFE00"} # 设置中位数线的属性,线的类型和颜色
)
plt.ylim(0,85) # 设置y轴的取值范围
plt.title("乘客年龄箱线图",fontsize="xx-large",color="#DE0052")
plt.tick_params(top="off", right="off") # 去掉o箱线图的上方及右方边框的刻度标签
plt.show() # 显示图形,jupyter notebook有另一种写法,可以不用每一次画图都码这句
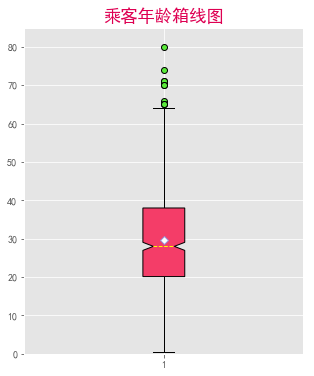
乘客的平均年龄为30岁,有50%的人,年龄落在20~38岁之间(看箱体);中位线偏下,上相邻值到箱子的距离比下相邻值到箱子的距离长,异常值多在上限值之外,说明年龄整体右偏;有偏大的异常值在64岁以上。
例3 针对箱线图箱体太扁、异常值突出情况
借用kaggle泰坦尼克号生存预测数据:Fare一项作为例子
import pandas as pd
import numpy as np
df = pd.read_csv(r"G:\Kaggle\Titanic\train.csv")
plt.figure(figsize=(5,6))
plt.boxplot("Fare",data=df)
plt.title("乘客船票价格箱线图",fontsize="xx-large",color="#DE0052")
plt.show()
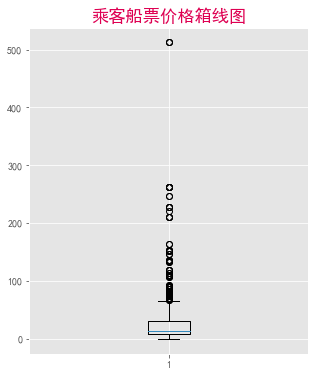
箱体很扁,异常值特别突出,难以看出数据的分布情况。留意到票价均为正数,我们选择将票价做对数变换。否则就换另一种图形来呈现数据,箱线图不行。
换seaborn来画
import seaborn as sns
plt.figure(figsize=(5,6))
sns.boxplot(y="Fare",data=df) #不注明y轴的话,箱线图是横躺着的
plt.title("乘客船票价格箱线图2",fontsize="xx-large",color="#DE0052")
plt.show()#DE0052
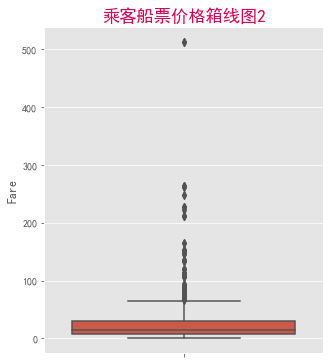
下面做对数变换,然后再画箱线图:
x = df.Fare
df["new_Fare"] = np.log(x)
plt.figure(figsize=(5,6))
plt.boxplot(x="new_Fare",data=df)
plt.title("乘客船票价格箱线图(对数变换后)",fontsize="xx-large",color="#DE0052")
plt.show()
F:\Anaconda\lib\site-packages\ipykernel_launcher.py:2: RuntimeWarning: divide by zero encountered in log
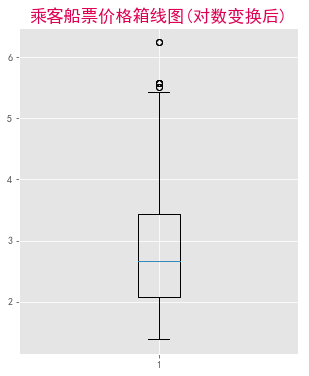
这样就好看多了,看得出中位线、数据分布情况,异常值也没这么凸显了。
用seaborn来画
plt.figure(figsize=(5,6))
sns.boxplot(y="new_Fare",data=df,width=0.2) #不注明y轴的话,箱线图是横躺着的
plt.title("乘客船票价格箱线图2(对数变换后)",fontsize="xx-large",color="#DE0052")
plt.show()
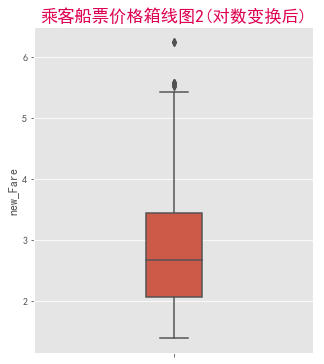
看出船票票价整体右偏,存在偏高的异常值。
例4
在一个定量变量的基础上,加入Pclass定性变量进行分组
plt.figure(figsize=(5,6))
sns.boxplot(x="Pclass",y="new_Fare",data=df,width=0.35)
plt.title("不同船舱等级乘客船票价格箱线图(对数变换后)",fontsize="xx-large",color="#DE0052")
plt.show()

对数变换后,不同船舱等级乘客的票价都呈现右偏,票价中位数:一等舱 > 二等舱 > 三等舱,一等舱的票价普遍比二、三等舱的票价高。同时看到,一等舱存在个别票价偏低、偏高的乘客,三等舱存在部分乘客票价异常情况。
在一个定量变量、一个定性变量的基础上,再加入一个定性变量Survived进行分组
plt.figure(figsize=(6,6))
sns.boxplot(x="Pclass",y="new_Fare",hue="Survived",data=df,width=0.6)
plt.title("不同船舱等级乘客船票价格箱线图2(对数变换后)",fontsize="xx-large",color="#DE0052")
plt.show()
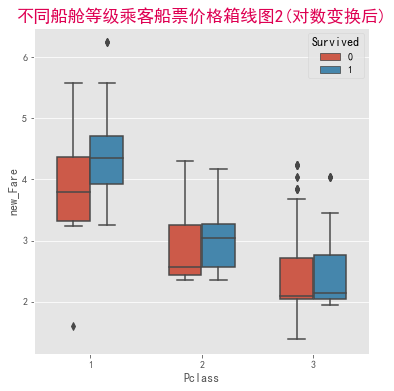
- 随着船舱等级的升高,船票价格也是随之升高的;
- 而且在同一船舱等级中,存活下来的乘客的票价中位数均比死亡乘客的票价中位数高;
- 在一等舱中,死亡乘客中存在一个票价异常低的乘客,而存活下来的乘客中存在一个票价异常高的乘客;
- 在三等舱中,死亡乘客中存在票价异常高的乘客,生存乘客中也存在一个票价异常高的乘客。与一等舱形成对比。
今天先作此笔记,plt.boxplot()的加入类别型变量、整块图形的背景色、坐标轴的字体大小还未解决。后期补上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号