

Python 编码encode()、 解码decode()问题
乱码这种东西,时不时出现。本来开开心心想着我要学习啦,然后兴高采烈打开了比火星文还火星文的字符……

没事,我可以搞定这堆鬼画符。

先来讲一下为什么有乱码这种东西的存在
故事是这样滴:
字符串是Python的一种数据类型,它的处理会涉及到编码问题。
我们可爱的计算机只能识别计算机语言,它以二进制字节形式来存储数据,就是0和1构成的一个长长的二进制字节(一般人是识别不了这种这么原始的语言的)
而作为人类,我们说的是人话,'language'、'中文'、'123'……,用的是文本字符(计算机读不懂这种抽象语言)
So, 人类创造出了ASCII码,一种字符对照表(类似翻译官),让人类跟计算机能交流啦!
最早的对照表是ASCII码表,ASCII码表是美国人创造出来的,总共128个字符,满足美国人民的日常需求!
但是!!!
世界那么大,每个国家都有自己的文字、符号,人类一直在扩充这张对照表,陆续创造了:扩展ASCII码、GB2312、GBK……
啊哈哈,各个国家有各个国家的特色。于是,生产出了许许多多的对照表。
工作中经常会遇到不同编码的问题,需要我们对不同的编码进行转换……但是随着人们的扩充,选到合适的对照表越来越费时间、精力,你们谁才是我要的那张表?

你可知道,时间是宝贵的,更何况是程序员的时间。
终于,美国一个叫ISO的组织看不下去了,它决定整顿一下这个混乱的编码世界
于是,Unicode就诞生啦,它将全世界人民的符号全部编进去了。让你们全部有个规范走,别再搞事情啦!(快去这个神器的网站看看:https://unicode-table.com/en/)
在Python里,如果你们要转换编码,都要经过Unicode。
不论是UTF-8或者是GBK,整个过程都是先通过编码decode转换为Unicode告诉Unicode当前的编码格式是什么、然后再通过解码encode转换为自己想要实现的编码格式或类型。
假设一个只会中文和一个只会英文的外交官在交流,Unicode就扮演其中的翻译官,他将中文字符转换成Unicode字节,再将Unicode字节转换成英文字符。
Python3中,str类型存unicode数据,bytse类型存bytes数据。
And, 文件默认的编码方式就是utf-8。
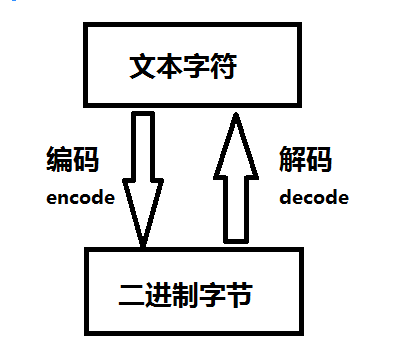
下面给个图来加深一下记忆:
下面到举栗子时间:

a = '我爱排球,有人要打球吗?'
print(type(a))
<class 'str'>
a.encode()
b'\xe6\x88\x91\xe7\x88\xb1\xe6\x8e\x92\xe7\x90\x83\xef\xbc\x8c\xe6\x9c\x89\xe4\xba\xba\xe8\xa6\x81\xe6\x89\x93\xe7\x90\x83\xe5\x90\x97\xef\xbc\x9f'
上面的是用默认的UTF-8去encode变量a,下面试一下encode为GBK类型
a.encode('GBK')
b'\xce\xd2\xb0\xae\xc5\xc5\xc7\xf2\xa3\xac\xd3\xd0\xc8\xcb\xd2\xaa\xb4\xf2\xc7\xf2\xc2\xf0\xa3\xbf'
上面展示了编码过程,接下来展示解码操作,解码经常出错,所以要留心哦

b = '下午四点全队集合,东区气排场'
print(type(b))
b1 = b.encode()
b2 = b.encode('GBK')
<class 'str'>
print(type(b1))
print(type(b2))
<class 'bytes'>
<class 'bytes'>
先把b以两种编码形式编好,一个是b1(UTF-8编码的),另一个是b2(GBK编码的)
用谁编码的,就只能用谁去解码,不然会报错
下面,我们不这么干,先来个乱码情况:

b1是UTF-8编码的,但是我们用GBK去解码
b1.decode('GBK')
'涓嬪崍鍥涚偣鍏ㄩ槦闆嗗悎锛屼笢鍖烘皵鎺掑満'
啊哈哈,你看出上面输出的是什么吗,反正我看不出

这就是常见的乱码情况。
下面是时候正常解码一下啦!
b1.decode('UTF-8')
'下午四点全队集合,东区气排场'
So,乱码就是这么一回事,他只是缺少一个对的翻译官。你要做的就是帮他找一个正确的翻译官。兄弟,加油,你是个称职的媒婆,你可以的

好了,我要去找吃的了。吃,吃,吃 ,我要胖十斤


