
MySQL缓存命中率概述及如何提高缓存命中率
MySQL缓存命中率概述
工作原理:
查询缓存的工作原理,基本上可以概括为: 缓存SELECT操作或预处理查询(注释:5.1.17开始支持)的结果集和SQL语句; 新的SELECT语句或预处理查询语句,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写;
查询缓存对什么样的查询语句,无法缓存其记录集,大致有以下几类:
1、 查询语句中加了SQL_NO_CACHE参数;
2、查询语句中含有获得值的函数,包涵自定义函数,如:CURDATE()、GET_LOCK()、RAND()、CONVERT_TZ等;
3、 对系统数据库的查询:mysql、information_schema 查询语句中使用SESSION级别变量或存储过程中的局部变量;
4、查询语句中使用了LOCK IN SHARE MODE、FOR UPDATE的语句 查询语句中类似SELECT …INTO 导出数据的语句;
5、对临时表的查询操作; 存在警告信息的查询语句; 不涉及任何表或视图的查询语句; 某用户只有列级别权限的查询语句;
6、 事务隔离级别为:Serializable情况下,所有查询语句都不能缓存;
配置
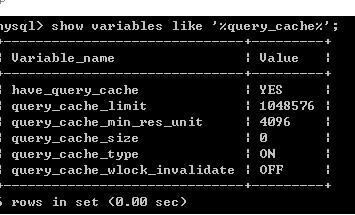
是否启用mysql查询缓存,可以通过2个参数:query_cache_type和query_cache_size,其中任何一个参数设置为0都意味着关闭查询缓存功能。
query_cache_type 值域为:
0(OFF):关闭 Query Cache 功能,任何情况下都不会使用 Query Cache;
1(ON): 启用查询缓存,只要符合查询缓存的要求,客户端的查询语句和记录集斗可以 缓存起来,共其他客户端使用;
2(DEMAND): 启用查询缓存,只要查询语句中添加了参数:sql_cache,且符合查询缓存的要求,客户端的查询语句和记录集,则可以缓存起来,共其他客户端使用;
query_cache_size 允许设置query_cache_size的值最小为40K,对于最大值则可以几乎认为无限制,实际生产环境的应用经验告诉我们,该值并不是越大, 查询缓存的命中率就越高,也不是对服务器负载下降贡献大,反而可能抵消其带来的好处,甚至增加服务器的负载,至于该如何设置,下面的章节讲述,推荐设置 为:64M;建议设置不要超过256MB
缓存选项的说明:
用show global status like 'QCache%';查看
Qcache_free_blocks:目前还处于空闲状态的 Query Cache 中内存 Block 数目
Qcache_free_memory:目前还处于空闲状态的 Query Cache 内存总量
Qcache_hits:Query Cache 命中次数
Qcache_inserts:向 Query Cache 中插入新的 Query Cache 的次数,也就是没有命中的次数
Qcache_lowmem_prunes:当 Query Cache 内存容量不够,需要从中删除老的 Query Cache 以给新的 Cache 对象使用的次数
Qcache_not_cached:没有被 Cache 的 SQL 数,包括无法被 Cache 的 SQL 以及由于 query_cache_type 设置的不会被 Cache 的 SQL
Qcache_queries_in_cache:目前在 Query Cache 中的 SQL 数量
Qcache_total_blocks:Query Cache 中总的 Block 数量
内存碎片的产生。当一块分配的内存没有完全使用时,MySQL会把这块内存Trim掉,把没有使用的那部分归还以重 复利用。比如,第一次分配4KB,只用了3KB,剩1KB,第二次连续操作,分配4KB,用了2KB,剩2KB,这两次连续操作共剩下的 1KB+2KB=3KB,不足以做个一个内存单元分配, 这时候,内存碎片便产生了。使用flush query cache,可以消除碎片
下面是命中率和内存使用率的一些算法
query_cache_min_res_unit的估计值:(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
查询缓存命中率 ≈ (Qcache_hits – Qcache_inserts) / Qcache_hits * 100%
查询缓存内存使用率 ≈ (query_cache_size – Qcache_free_memory) / query_cache_size * 100%
InnoDB存储引擎的缓冲池
通常InnoDB存储引擎缓冲池的命中不应该小于99%。
参数说明:
Innodb_buffer_pool_reads: 表示从物理磁盘读取页的次数
Innodb_buffer_pool_read_ahead: 预读的次数
Innodb_buffer_pool_read_ahead_evicted: 预读的页,但是没有读取就从缓冲池中被替换的页的数量,一般用来判断预读的效率
Innodb_buffer_pool_read_requests: 从缓冲池中读取页的次数
Innodb_data_read: 总共读入的字节数
Innodb_data_reads: 发起读取请求的次数,每次读取可能需要读取多个页
Innodb缓冲池命中率计算:

提高缓存命中率
众所周知,系统读取数据时,从内存中读取要比从硬盘上速度要快好几百倍。故现在绝大部分应用系统,都会最大程度的使用缓存(内存中的一个存储区域),来提高系统的运行效率。MySQL数据库也不例外。在这里,笔者将结合自己的工作经验,跟大家探讨一下,MySQL数据库中缓存的管理技巧:如何合理配置MySQL数据库缓存,提高缓存命中率。
什么时候应用系统会从缓存中获取数据?
数据库从服务器上读取数据时,可以从硬盘的数据文件中获取数据,也可以从数据库缓存中读取数据。现在数据库管理员需要搞清楚的是,在什么样的情况下,系统是从缓存中读取数据,而不是从硬盘的数据文件中读取数据?
简单的说,数据缓存就是内存中的一块存储区域,其存储了用户的SQL文本以及相关的查询结果。通常情况下,用户下次查询时,如果所使用的SQL文本是相同的,并且自从上次查询后,相关的纪录没有被更新过,此时数据库就直接采用缓存中的内容。从这个原则中,可以看到如果要直接使用缓存中的数据,至少要满足以下几个条件。
一是所采用的SQL文本是相同的。当前后两次用户使用了相同的SQL语句(假设不考虑其他条件),则服务器会从缓存中读取结果,而不需要再去解析和执行SQL语句。这里需要注意的是,这里的SQL文本必须一次不差的完全相同。如果前后两次查询,使用了不同的查询条件。如第一次查询时没有输入Where条件语句。后来发现数据量过多,利用了Where条件了过滤查询的结果。此时即使最后的查询结果是相同的,系统仍然是从数据文件中获取数据,而不是从数据缓存中。再如,Select后面所使用的字段名称也必须是相同的。如果有一个字段名称不同或者前后两次查询所使用的字段数量不同,则系统都会认为是不同的SQL语句,而重新解析并查询。
二是从数据缓存的角度考虑,大小写是不敏感的。如前后两次查询时,采用的字段名称可能只有大小写的差异。如第一次使用的是大小,第二次使用的是小写,这系统认为仍然是相同的SQL语句。或者说关键字大小写等等这都是不敏感的。
三是要满足二次查询之间,数据记录包括表结构都没有被更改过。如果记录所在的标更改了,如增加了一个字段等等,此时使用这个表的所有缓冲数据系统将自动清空。这里需要注意,这里指的更改是一个广义的更改,包括表中任何数据或者结果的改变。举一个简单的例子,第一次查询时用户需要查询2010年的出货数据。查询后有用户在这个表中插入了一条2011年1月份的出货信息。然后又有用户需要查询2010年的出货信息。使用的SQL语句与第一次查询时完全相同。在这种情况下,数据库系统会使用缓存中的数据吗?答案是否定的。因为当中间用户插入一条记录时,系统会自动清空跟这个表相关的所有缓存记录。当第二次查询时,缓存中已经没有这张表对应的缓存信息。此时就需要重新解析并查询。
四是需要注意,默认字符集对缓存命中率的影响。通常情况下,如果客户端与服务器之间所采用的默认字符集不同,则即使查询语句相同、在两次查询之间记录与表结构也没有被更改,系统仍然认为是不同的查询。对于这一点需要特别的注意,大家比较容易忽视。
提高缓存命中率的建议
从上面的条件分析中可以看出,利用缓存中的数据具有比较严格的条件。其实这些条件也是合情合理的。主要是为了保障数据的一致性。对以上这些条件有深入的认识之后,现在数据库管理员需要考虑的是,如何来提高这个缓存的命中率?对此笔者有如下几个建议。
一是在配置时,客户端与服务器端要使用相同的字符集。如果客户端(或者说第三方工具)与服务器端使用的字符集不同,那么任何情况下都不会使用缓存功能。特别在国内,需要用到中文的字符集。此时特别需要注意,客户端默认字符集要与服务器端的默认字符集相同。注意,这里是相同,而不是兼容。有时候即使采用了不同的字符集,客户端上仍然可以正常显示。这主要是因为有些字符集虽然不相同,但是是相互兼容的。在缓存管理上,需要相同,光兼容还不行。
二是在客户端上,要固化查询的语句。如现在有财务人员和采购人员同时从系统中查询11月份的出货数据。显然他们岗位职责不同,所需要字段的内容是不同的。此时在客户端出,可以允许用户设置自己所需要的表单格式。但是笔者建议,后台所采用的SQL语句最好是相同的。这里数据会经过三个渠道:后台数据库、客户端、用户。笔者的意识时,后台数据库与客户端之间的交互采用相同的SQL语句。然后客户端与用户之间进行交互时,根据用户定义的格式(包括字段前后的排列、不包括查询条件语句的差异)向用户显示数据。此时由于采用了相同的SQL语句(只是用户对于显示格式的要求不同),从而可以提高应用系统的查询效率。
三是提高内存中缓存的配置,来提高命中率。一般在服务器启动时,操作系统会跟数据库软件协商缓存空间的大小。当缓存工作不足时,缓存中最旧的缓存记录会被最新的消息所覆盖。可见,如果能够提高缓存空间,就可以提高命中率。这就好像打靶,目标多了,命中的几率也会高许多。不过用户的并发数越多,这个设置的效果会越不明显。
四是通过分区表可以提高缓存的命中率。在上面的条件分析中,大家可以看到,只要所查询的表中插入了一条记录,系统就会清空缓存记录。现在以查询出货记录为例。出货记录表每天都在更新,而用户在年初时,会经常需要查询上一年的出货记录。此时由于这个表中的数据每个小时都在更新,那么缓存中的信息会不断的被情况。此时缓存的命中率显然不会很高。针对这种情况,笔者建议可以采用分区表。如可以通过系统设置,将2010年的出货记录单独存放在一个出货的分区表中。即每一个年度都使用一张单独的分区表。此时2011年的纪录,就不会影响到2010年的分区表。此时如果用户重复查询2010年的出货信息,只要其使用的SQL语句相同(没有采用不同的查询条件),那么就可以享受缓存机制所带来的效益,提高应用系统的查询效果。。
多个应用对缓存的影响
通常情况下,MySQL数据库的缓存是根据服务器内存的大小自动分配的。如果一台服务器上只有一个MySQL应用,那么固然最好。不过在实际工作中,为了降低信息化投资的成本,往往会在同一台服务器上布置多个信息化应用。由于其他信息化应用也需要使用内存的空间作为缓存,那么MySQL数据库中缓存空间就可能变小。如果遇到这种情况下,数据库管理员需要跟系统工程师进行协商,为各种不同的应用根据性能要求的不同,手工设置不同的缓存空间。如此的话,就可以避免同一台服务器上不同信息化应用对缓存的冲突。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号