
字符编码与数据编码合集
一、分类
(一)字符编码
字符编码用于将字符集中的字符映射到计算机可以处理的数字(通常是字节)。它主要处理文本数据,确保不同设备和系统能够正确显示和理解文本。
人话:把世界各地不同的符号转化成便于处理的二进制数。
举例: ASCII、Unicode、UTF8、UTF32、GBK、GB2312…
补充:字符集通常与字符编码混用,但严格来说,字符集定义了字符和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将字符的编号存储到计算机中。一个字符集可以有多种编码实现,就像一个接口可以有多种实现类一样。如ASCII、Unicode其实是字符集,但人们把它也叫成了字符编码。
(二)数据编码
数据编码方式用于将二进制数据转换为某种格式,确保数据能够在特定的传输或存储介质上有效传输或存储。
人话:把二进制数转化成一些字母来传输。
举例:base64、base16(Hex编码)、base32、URL中的百分号编码、QR编码…
二、字符编码
(一)、ASCII码字符表
(二)、Unicode编码、UTF32、UTF16、UTF8
Unicode
简要概括: 码点分为0x0000~0x10FFFF,最多用3个字节表示

UTF32
简要概括: 定长码,用32bit即4个字节表示

UTF8
简要概括: 变长码,最多需要4个字节表示
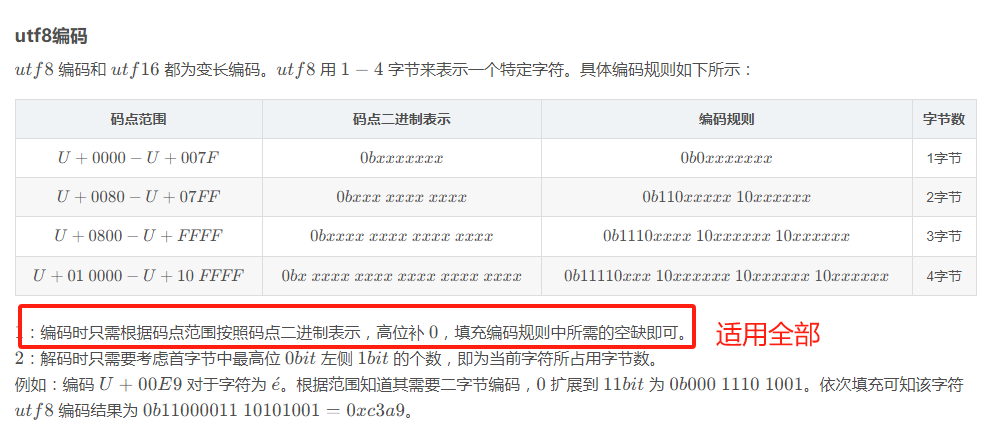
注意填充规则同样适用UTF32\16\8
UTF16
简要概括:实质就是把UTF32进行拆分,原本需要32bit表示一个字符,现在把一个字符拆分成高16位和低16位进行表示

UTF8与UTF16进行对比

(三) GBK、GB2312、GB18030
(四)、乱码问题※
1、产生原因

2、编码与解码时产生的实际问题剖析
字符编码与解码不一致会导致乱码,但通常不会对原文本本身产生不可逆的损坏,前提是你有原始的正确编码,最开始文章提到过,编码的实际过程就是把字符转为易于保存的二进制码,只要这个原始的二进制码没有被破坏,那么原来的文本实际就没有被损坏,只要选择正确的编码进行打开便可以查看到其正确字符。
但是,如果文本已经被错误地解码并重新编码(例如通过保存文件时进行了编码转换),那么乱码可能会变得不可恢复。例如,下面的例子,使用GBK对“哈哈哈”进行编码并保存,下次打开时使用UTF8编码进行打开会发现乱码,但这个时候原始的二进制数据并没有改变,只是解码的方式不正确导致显示乱码。如果这个时候再对这个乱码选择UTF8编码格式进行保存,那么将导致这些乱码被UTF8规则进行编码并覆盖了原来正确内容的二进制码,原来的数据将彻底损坏并不可恢复。
- 第一步


- 第二步

- 第三步

-
第四步


可见这时文件的二进制码已和最开始的不一样了。
这种问题离我们并不遥远,通常发生在远程控制或者使用不同平台对文件进行打开时,由于不同平台默认的打开文件和保存文件的编码规则不一样。例如,开发者在本地用编码A对数据进行保存,下一次在云端对本地进行远程控制时使用云端打开这个数据,但是云端默认的编码规则为B,这就导致乱码,如果再不幸一点,云端默认的保存编码规则也为B,并且你一时激动按下了Ctrl+S保存了这个文件,那么这个文件将彻底损坏。所以,为了避免这种悲剧的发生,在你打开一个文件发现乱码的时候,不要着急改动里面的内容,更不要着急保存,正确的做法应该是直接关闭你的编辑器,确认好选择好正确的编码规则对文件再次打开。
三、数据编码
(一)、base16、base32、base64、base256
- base64


-
小结

-
对比

(二)、base64URL编码与百分号编码:
1、URL中的参数规则概述与URL参数传输机制
-
传输机制

-
参数规则
通常URL中“?”之后的内容代表参数,比如name=%E4%BD%A0%E5%A5%BD,等号后面的就是数据,对于这个数据,我们主要可以选择两种方式,一种就是前面格式的百分号编码,另一种就是base64URL(也称base64安全编码),例如?data=eyJuYW1lIjogIlRvbSAmIEplcnJ5IiwgImFnZSI6IDV9
先别着急,下面就来解释为什么要这样进行数据编码。
2、URL对特殊字符的处理
URL 中不能包含某些字符,如空格、特殊符号(例如 &、=、?)以及控制字符。这些字符有特殊的含义,或者会导致解析错误。那么当我们的参数有这些特殊符号的时候,就需要进行相应的转换。
- 对于百分号编码

参考资料:
《URL中“#” “?” &“”号的作用》
- 对于base64安全编码
由于base64编码的结果中存在+和/,而这两个符号在url中也有特殊含义,分别代表空格和路径分隔,那么如果使用base64对数据进行编码,就容易使后端服务器产生误解,为了解决这个问题,base64安全编码诞生,其实就是用-和_对+和/进行替代,其他规则不变。
3、中文传参
如果我们要传入的参数数据中包含有中文怎么办?前面说到因特网只能传输英文、数字和某些标点,显然直接传输中文是不行的,那么就需要先使用字符编码,之后在对其进行数据编码,便可以作为参数放入url中。
例如前面提到的`name=%E4%BD%A0%E5%A5%BD`,就是先使用UTF8对"你好"进行字符编码得到`0xE4BDA0E5A5BD`,再使用百分号的数据编码方式,其实百分号在URL中起到了转义字符的作用。
我们也可以用base64安全编码对`0xE4BDA0E5A5BD`进行数据编码再放入参数,但是实际中很少这么做,因为这么做会增加数据长度,同时编码相较百分号更为复杂,至于什么时候用base64编码更为合适,我们后面再说。
此外,对中文的字符编码不仅仅只能是UTF8,其他的字符编码方式(如GBK、GB2312)也可以,UTF8只是最通用、最广泛的方式。如果一定要用其他编码方式,需要再http请求头中指明,以便后端服务器进行解码,例如要制定GBK编码方式:`Content-Type: application/x-www-form-urlencoded; charset=GBK`
4、base64的运用
虽然在URL中base64并没有太大优势,也较少使用,但这并不代表它无用处。实际上,它仍然在某些场景中非常有用,主要是因为它提供了一些重要的优点,尤其是在处理二进制数据时:
Base64 编码最常见的用途之一是将二进制数据(如图片、音频文件、视频文件、加密数据等)转换为可读文本。二进制数据通常无法直接嵌入文本系统(如 URL、JSON 或电子邮件),因为它们包含了非打印字符,可能会干扰数据传输。Base64 编码将任意二进制数据转换成字母数字字符,这样就能安全地通过文本协议(如 HTTP 或 SMTP)传输。
